

Графическое представление данных
Для построения диаграммы дискретного вариационного ряда нужно выделить область ячеек А1:В7 (ячейки, в которых находятся данные). После этого можно вызвать Мастер диаграмм или выбрать команду падающего меню Вставка-Диаграмма. На втором шаге выбирают тип диаграммы Точечная (можно с соединенными точками, можно отдельно стоящие точки) и область построения диаграммы на этом листе или на новом листе. Для описания диаграммы можно заполнить легенду (например, Объем товарооборота, тыс.грн.), название осей (ось Х – Временные периоды, ось Y –Величина товарооборота).
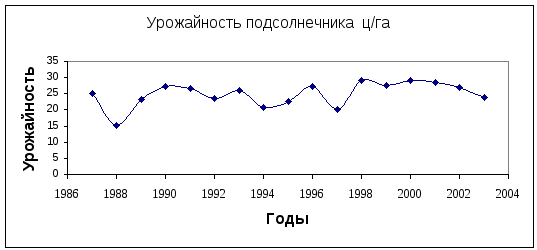
Рисунок 3
Гистограмма.
Вычисляет выборочные и накопленные
частоты попадания ряда данных в интервалы,
а также может выводить соответствующие
графики (модуль 3). Границы интервалов
(карманы) можно указать (обычно задают
верхние границы интервалов). Если не
задать границы, то Excel
сам разобьет анализируемый ряд на
интервале с шагом
![]() :
:
![]() ,
,
где
![]() – наибольший вариант,
– наибольший вариант,
![]() – наименьший вариант,
– наименьший вариант,
![]() -ряда
(количество членов).
-ряда
(количество членов).
Гистограмму можно построить автоматически, для этого достаточно выделить необходимый диапазон и нажать F11.
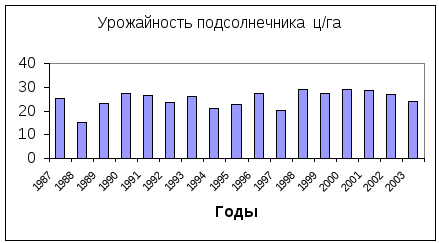
Рисунок 4
Одним из основных плюсов Excel является возможность создания формул и использования готовых функций для обработки массивов чисел (а так же текстов и символов).
Для ввода формулы необходимо набрать в пустой ячейке “=”, а затем с помощью операций ^, *, /, + связать исходные данные в ячейках, результат расчета с которыми мы хотим получить.
При вводе формул
удобно использовать встроенные функции
![]() (существует несколько сотен встроенных
функций, позволяющих обрабатывать
численную, текстовую и символьную
информацию), используя так называемые
диалоговые окна, предписывающие
последовательность ввода данных и
уменьшающие возможности допущения
ошибки.
(существует несколько сотен встроенных
функций, позволяющих обрабатывать
численную, текстовую и символьную
информацию), используя так называемые
диалоговые окна, предписывающие
последовательность ввода данных и
уменьшающие возможности допущения
ошибки.
При решении различных
задач в Excel
можно использовать, как в формулах, так
и независимо, встроенные функции. На
панели Стандартные
с помощью кнопки
![]() Вставка функции
откроем диалоговое
окно мастера функций (желательно после
установки в Меню Сервис
надстройки Пакет
анализа), которое
содержит 13 различных категорий функций.
Вставка функции
откроем диалоговое
окно мастера функций (желательно после
установки в Меню Сервис
надстройки Пакет
анализа), которое
содержит 13 различных категорий функций.
Нахождение суммы данных
Установить
курсор мыши в свободную ячейку, выбрать
на панели кнопку
![]() ,
выделить данные, записанные в столбец
или строку. В выбранную свободную ячейку
будет помещен результат суммирования.
,
выделить данные, записанные в столбец
или строку. В выбранную свободную ячейку
будет помещен результат суммирования.
Нахождение среднего значения
Предварительно
просуммированные данные можно разделить
на количество наблюдений, для чего в
свободную ячейку вводят формулу
![]() ,
где
,
где
![]() – ячейка, в которой записана сумма
данных,
– ячейка, в которой записана сумма
данных,
![]() – количество наблюдений.
– количество наблюдений.
Статистический анализ данных в Excel
Категория функций
Статистические
является одной из самых многочисленных.
Она содержит 78 статистик (функций
обрабатываемых данных): среднее,
дисперсию, максимальное и минимальное
значения; квантили статистик
![]() -Стьюдента,
-Стьюдента,
![]() – Фишера-Снедекора,
– Фишера-Снедекора,
![]() – хи-квадрат Пирсона, нормального
закона; частоту попадания в заданные
интервалы массива данных (ЧАСТОТА) и
многое другое. Кроме того, ряд функций
позволяет рассчитать вероятности того,
что случайная величина
– хи-квадрат Пирсона, нормального
закона; частоту попадания в заданные
интервалы массива данных (ЧАСТОТА) и
многое другое. Кроме того, ряд функций
позволяет рассчитать вероятности того,
что случайная величина
![]() примет значение
примет значение
![]() или случайная величина
или случайная величина
![]() не превысит значение
не превысит значение
![]() для часто встречающихся законов
распределения случайной величины.
Например, функции Гипергеомет
и Отрбиномрасп
– возвращают
для часто встречающихся законов
распределения случайной величины.
Например, функции Гипергеомет
и Отрбиномрасп
– возвращают
![]() для гипергеометрического и отрицательного
биномиального законов соответственно;
функции Биномрасп,
Пуассон,
Экспрасп,
нормрасп
возвращают
для гипергеометрического и отрицательного
биномиального законов соответственно;
функции Биномрасп,
Пуассон,
Экспрасп,
нормрасп
возвращают
![]() или
или
![]() (значения интегральных, а в последних
двух случаях дифференциальных функций
в точке
(значения интегральных, а в последних
двух случаях дифференциальных функций
в точке
![]() )
для биномиального, пуассоновского,
экспоненциального и нормального законов
соответственно.
)
для биномиального, пуассоновского,
экспоненциального и нормального законов
соответственно.
Рассмотрим получение основных параметров распределения на примере урожайности подсолнечника (ц/га).
Описательная
статистика. Эта
команда генерирует статистический
отчет для несгруппированного массива
чисел: характеристики положения и
вариации, наибольшее и наименьшее
значение, коэффициенты асимметрии и
эксцесса, сумму, предельную ошибку
доверительного интервала (уровень
надежности
![]() )
для средней при заданном уровне
надежности.
)
для средней при заданном уровне
надежности.
Выполним команду
Сервис – Анализ
данных – Описательная статистика,
заполним параметры диалогового окна
(при уровне значимости
![]() ).
В результате получим лист книги Ecxel,
изображенный на рисунке 5.
).
В результате получим лист книги Ecxel,
изображенный на рисунке 5.
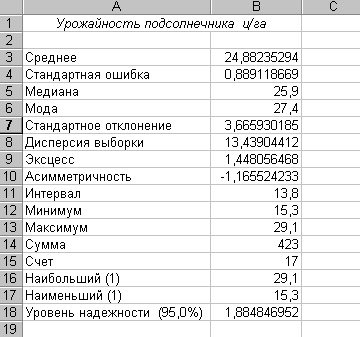
Рисунок 5
Параметры диалогового окна “Описательная статистика”:
-
Входной диапазон: введите ссылку на ячейки, содержащие анализируемые данные. Ссылка должна состоять как минимум из двух смежных диапазонов данных, организованных в виде столбцов или строк.
-
Группирование: установите переключатель в положение По столбцам или По строкам в зависимости от расположения данных во входном диапазоне.
-
Метки в первой строке/Метки в первом столбце: установите переключатель в положение Метки в первой строке, если первая строка во входном диапазоне содержит названия столбцов. Установите переключатель в положение Метки в первом столбце, если названия строк находятся в первом столбце входного диапазона. Если входной диапазон не содержит меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
-
Уровень надежности: установите флажок, если в выходную таблицу необходимо включить строку для уровня надежности. В поле введите требуемое значение. Например, значение 95% вычисляет уровень надежности среднего со значимостью 0.05.
-
К-ый наибольший: установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать максимум из набора данных.
-
К-ый наименьший: установите флажок, если в выходную таблицу необходимо включить строку для k-го наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта строка будет содержать минимум из набора данных.
-
Выходной диапазон: введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в зависимости от положения переключателя Группирование.
-
Новый лист: установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном напротив соответствующего положения переключателя.
-
Новая книга: установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
-
Итоговая статистика: установите флажок, если в выходном диапазоне необходимо получить по одному полю для каждого из следующих видов статистических данных: Среднее, Стандартная ошибка (среднего), Медиана, Мода, Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум, Максимум, Сумма, Счет, Наибольшее (#), Наименьшее (#), Уровень надежности.
В таблице 1 в третьем столбце указаны принятые обозначения и формулы для рассчитываемых статистик.
Таблица 1
|
Урожайность подсолнечника, ц/га |
|
Принятые обозначения |
|
Среднее |
24,88235294 |
|
|
Стандартная ошибка |
0,889118669 |
|
|
Медиана |
25,9 |
|
|
Мода |
27,4 |
|
|
Стандартное отклонение |
3,665930185 |
|
|
Дисперсия выборки |
13,43904412 |
|
|
Эксцесс |
1,448056468 |
|
|
Асимметричность |
-1,165524233 |
|
|
Интервал |
13,8 |
|
|
Минимум |
15,3 |
|
|
Максимум |
29,1 |
|
|
Сумма |
423 |
|
|
Счет |
17 |
|
|
Наибольший |
29,1 |
- |
|
Наименьший |
15,3 |
- |
|
Уровень надежности (95,0%) |
1,884846952 |
|