

John Wiley & Sons - 2004 - Analysis of Genes and Genomes
.pdf248 CREATING MUTATIONS 7
This linker, 19 amino acids in length, forms different structures in each protein that positions the zinc cluster differently with respect to the coiled coil. These differences are sufficient to dictate the binding of the protein to 5 -CGG-3 triplets that are separated by different numbers of base pairs. This kind of precise gene analysis would simply not have been possible using traditional cloning methods.
The power and speed of using PCR techniques to produce mutant DNA molecules, either gene fusions as described above, or point mutants, is unquestionable. Mutagenesis can be performed very quickly. With the availability of suitable oligonucleotides, the two-step PCR strategy can be performed in 3 –4 h. The limiting step in the process is the cloning of the mutant linear PCR products into plasmids such that functional analysis may be performed. Procedures in which the double-stranded plasmid DNA can be mutated without the need for additional cloning steps are therefore required.
7.5QuikChange Mutagenesis
The PCR based mutagenesis procedures described above require that the linear mutant DNA fragments produced are cloned into plasmid DNAs so that they can be propagated and analysed functionally. A method using the power of PCR to introduce mutations directly into plasmid DNA would alleviate the need for additional cloning steps.
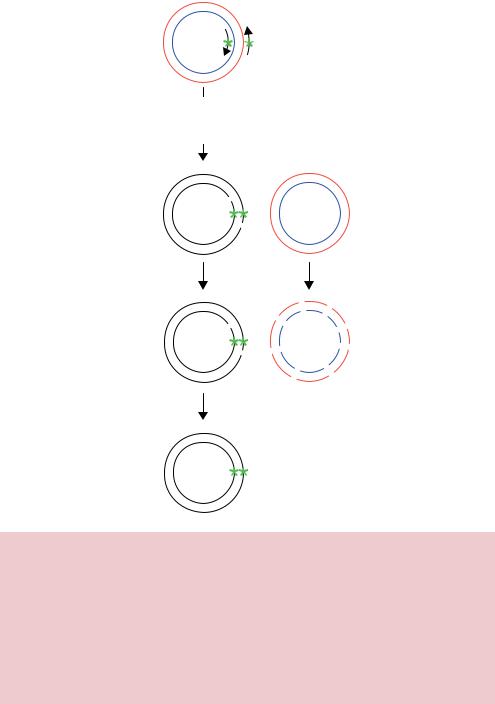
One popular PCR based method for introducing mutations directly into plasmid DNA is outlined in Figure 7.9. This method, often referred to as the QuikChange method (Wang and Malcolm, 1999), utilizes two oligonucleotide primers. One of the primers is produced so it is complementary to the sense strand of the gene and contains the desired mutation, whilst the other primer is designed to be complementary to the anti-sense strand of the gene, but also contains the mutation. Double-stranded plasmid DNA is used as a PCR template. The plasmid DNA is heated during the course of a normal PCR reaction such that the individual strands become separated (denatured). Cooling the denatured DNA in the presence of the oligonucleotides results in their binding to complementary sequences within the plasmid. Thermocycling is then continued to extend the oligonucleotides to create newly synthesized mutant plasmid DNA. After the PCR reaction is completed, newly synthesized DNA (containing the mutation) comprises two complementary linear DNA
QUIKCHANGE MUTAGENESIS |
249 |
|
|
Thermocycle to denature wild-type DNA strands and extend mutantoligonucleotide primers using thermostable DNA polymerase
Digest with restriction enzyme Dpnl
Transform into E. coli
Figure 7.9. QuikChange mutagenesis. The plasmid to be mutated is mixed with two complementary overlapping oligonucleotide primers, each of which encodes the required mutation. The primers are extended in a PCR reaction to synthesize both plasmid DNA strands, each of which contains the mutation. The DNA is then digested with the restriction enzyme DpnI, which can only cleave methylated DNA. If the parental plasmid was isolated from a Dam+ E. coli strain then the parental DNA strands, but not the unmethylated newly synthesized mutant DNA strands, will be cleaved by the enzyme. Subsequent transformation into E. coli will result in the degradation of the cut parental DNA fragments and the repair of the nicks in the newly synthesized DNA. The newly synthesized mutant DNA will then be replicated

250 CREATING MUTATIONS 7
molecules that are able to form a double-stranded circle containing staggered DNA nicks (Figure 7.9). The PCR products are then digested with the restriction enzyme DpnI, which can only cleave methylated DNA:
DpnI:
CH3
5'-GA TC-3' 3'-CT AG-5'
CH3
The newly synthesized DNA will not be methylated, and consequently will not be cleaved by the restriction enzyme. If the non-mutant parental plasmid DNA, on the other hand, was isolated from an E. coli strain that contains the Dam methylase (see Chapter 2), then DpnI will cleave at its recognition sequences. Most common laboratory E. coli strains are dam+, so this method of degradation of the wild-type DNA is applicable to the majority of plasmids available in the laboratory. Transformation of the restriction enzyme products into E. coli cells will result in the degradation of the wild-type DNA fragments and the repair of the nicks in the newly synthesized mutant DNA circles, which will then be propagated. This procedure is very rapid (3 –4 h) and is highly efficient ( 80 per cent) at producing mutant DNA plasmids without the need for additional cloning steps.
7.6Creating Random Mutations in Specific Genes
The creation of specific directed mutants within genes using oligonucleotides has revolutionized our understanding of protein function. The examples we have discussed so far have, however, been limited to the alteration of specific bases within a gene to other defined bases. This will result in the formation of mutant protein with defined amino acid changes if the alterations are within the coding sequence of the gene. It is not always possible to know which amino acids of a protein should be altered, or what they should be altered to. Some systematic approaches to this problem involve the change of each amino acid coding triplet within a gene to an alanine codon (Cunningham and Wells, 1989). This alanine scanning mutagenesis can identify amino acid side chains that are important for protein function with the premise that the presence of alanine will not perturb the overall structure of the protein and will only eliminate amino acid side chain interactions. This type of approach requires
7.6 CREATING RANDOM MUTATIONS IN SPECIFIC GENES |
251 |
|
|
that a screen is available for identifying protein function and is especially applicable to small proteins or protein domains owing to the number of individual mutations that must be constructed. An alternative approach is to convert sets of charged amino acid residues that occur consecutively within a linear polypeptide sequence to alanine (Bass, Mulkerrin and Wells, 1991). This charged to alanine scanning mutagenesis is based on the observation that most proteins contain a hydrophobic core with charged residues on the outside surface of the protein. Consequently, clusters of charged amino acids in a linear protein sequence are likely located on the surface of the protein and may therefore participate in, for example, protein –protein interactions. Mutation of these charged clusters are more likely to disrupt these protein –protein interactions than mutagenesis of other residues.
Two approaches are commonly used for the creation of random mutations within individual genes, or parts of genes. Again, these methods rely on a screen to analyse mutants with an appropriate phenotype, but do not suffer from limiting mutations types to individual residues or from the types of alteration that can be made.
•Doped cassette mutagenesis. An experiment like that already discussed in Figure 7.5 is performed except that a library of oligonucleotides is ligated into the cut plasmid (Figure 7.10). Like conventional cassette mutagenesis, the DNA between two restriction enzyme recognition sites is removed from a plasmid and replaced using a pair of synthetic oligonucleotides. Here, however, the oligonucleotides do not encode a unique sequence. Instead, libraries of oligonucleotides are produced that are based on the same sequence, but contain certain random changes from that sequence. Such doped oligonucleotides are synthesized (Figure 4.6) using a mixture of bases. For example, if the next base to be added to an extending oligonucleotide were an A, then rather than chemically adding only the A precursor to the growing oligonucleotide chain a mixture of A and a small quantity of the other nucleotide precursors would be added. Such mixtures might commonly contain 95 per cent of the wild-type nucleotide and 1.7 per cent of each of the other nucleotides. The level of ‘doping’ gives some control over the level of mutagenesis that will be obtained. In the example shown in Figure 7.10, the sequence between the EcoRI and PstI restriction sites is to be altered. An oligonucleotide is constructed that contains invariant EcoRI and PstI restriction sites that are absolutely required for cloning of the DNA back into the plasmid. The sequences between these sites are doped at a level such that, on average, each oligonucleotide produced will contain a single variation from the wild-type sequence. Two example of oligonucleotides produced are shown in Figure 7.10. By choosing an appropriate level
 and PstI
and PstI
7.6 CREATING RANDOM MUTATIONS IN SPECIFIC GENES |
253 |
|
|
strands, or the palindromic nature of the restriction enzyme recognition sites at the end of the oligonucleotide are used to create dimeric molecules that can then be cut with the restriction enzymes and cloned into the plasmid. The first method relies complementary mutations existing with the two complementary DNA strands, and suffers from that mutant mis-matches between the oligonucleotide pairs may be tolerated during the formation of double-stranded DNA to increase the number of mutations found in each cassette. The second method (as shown in Figure 7.10) is more desirable since individual mutations within the single-stranded oligonucleotide library will be retained in the double-stranded form.
•Error-prone PCR. We have already discussed the error-prone nature of cer-
tain DNA polymerases that are used in PCR (Chapter 4). In particular, the lack of a 3 –5 exonuclease proofreading activity in Taq DNA polymerase means that significant mutations may be introduced into PCR products simply as a consequence of the PCR itself (Keohavong and Thilly, 1989). The advantage of this method for introducing random mutations (Figure 7.11) is that only a PCR reaction need be performed. The PCR product can then be cloned and analysed functionally. The error rate of Taq DNA polymerase
5′ |
|
|
|
|
|
|
|
|
|
|
|
|
3′ |
|
|
|
|
|
|
|
|
|
|
|
|
||||
3′ |
|
|
|
|
|
|
|
|
|
|
|
|
|
5′ |
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
3′ |
|
|
5′ |
|||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
||||||
5′ |
|
|
|
|
|
|
|
|
|
|
3′ |
|||
|
|
|
|
|
|
|
|
|
|
|||||
3′ |
|
|
|
|
|
|
|
|
|
|
|
5′ |
||
|
|
|
3′ |
|
|
|
|
|
|
|||||
5' |
|
|
Error prone |
|||||||||||
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
5′ |
x |
|
PCR |
3′ |
||||||
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
3′ |
x |
|
|
|
|
5′ |
||||
|
|
|
|
5′ |
|
|
x |
3′ |
||||||
|
|
|
|
3′ |
|
|
x |
5′ |
||||||
|
|
|
|
5′ |
|
|
|
|
|
|
3′ |
|||
|
|
|
|
|
|
|||||||||
|
|
|
|
3′ |
|
|
|
|
|
|
5′ |
|||
|
|
|
|
|
|
|||||||||
|
|
|
|
5′ |
|
x |
|
|
|
|
3′ |
|||
|
|
|
|
3′ |
|
x |
|
|
|
|
5′ |
|||
|
|
|
|
5′ |
|
|
|
x |
3′ |
|||||
|
|
|
|
3′ |
|
|
|
x |
5′ |
|||||
|
|
|
|
5′ |
|
|
|
x |
3′ |
|||||
|
|
|
|
3′ |
|
|
|
x |
5′ |
|||||
|
|
|
|
5′ |
|
x |
|
x |
3′ |
|||||
|
|
|
|
3′ |
|
x |
|
x |
5′ |
|||||
Figure 7.11. Error-prone PCR as a method for mutating a gene. The error-prone nature of certain DNA polymerases using during PCR will result in the creation of mutations within the amplified DNA. The PCR experimental conditions can be altered to increase the error rate so that, on average, each amplified double-stranded product contains a single mutation

254 CREATING MUTATIONS 7
may be increased, to increase the mutation frequency obtained, by altering a variety of the PCR reaction conditions. For example, increasing the magnesium concentration in the reaction or adding manganese ions to the reaction will increase the error rate of the polymerase (Lin-Goerke, Robbins and Burczak, 1997). Additionally, changes in the reaction deoxynucleotide concentration, the concentration of the polymerase itself or the length of the extension step of the reaction can each result in an elevated error rate. The ease at which PCR based random mutagenesis can be preformed has made it a popular choice. The main drawback of the technique is the reliance on an enzyme to create random mutations. DNA polymerases have preferences in the mistakes they make. In the case of Taq DNA polymerase, transitions are favoured over transversions (Keohavong et al., 1993), so some mutations are difficult to obtain.
7.7Protein Engineering
Protein engineering can be thought of as the deliberate modification of the sequence of a protein (through the alteration of the DNA sequence encoding it) to impart the protein with a new or novel function. This approach has been used for the creation of enzymes with altered characteristics that may be desirable for particular purposes. The sorts of enzyme characteristics that may be altered include.
•thermal stability
•pH stability
•kinetic properties
•stability in organic solvents
•altered cofactor requirement
•altered substrate binding specificity
•resistance to proteases
•changed allosteric regulation.
Protein engineering has been used to alter the thermal stability of lysozyme in a directed way (Matsumura, Signor and Matthews, 1989). The rationale behind these experiments was that disulphide bonds formed between two cysteine amino acid residues within a protein should be able to lock the protein
7.7 PROTEIN ENGINEERING |
255 |
|
|
structure into a conformation that is resistant to heat denaturation. The gene encoding lysozyme from the bacteriophage T4, a disulphide-free enzyme, was engineered by the introduction of cysteine codons in its sequence such that in the resulting protein disulphide bonds were formed to crosslink residues 3 –97, 9 –164 and 21 –142. The mutant protein denatured at 66 ◦C, compared with 42 ◦C for its wild-type counterpart (Matsumura, Signor and Matthews, 1989).
Protein engineering can also be used to change the specificity of an enzyme such that it is able to catalyse the reaction of alternative substrates. For example, a single point mutation in the yeast alcohol dehydrogenase I gene, converting aspartic acid 233 to glycine, results in the production of a protein that, rather than solely using NAD+ as a cofactor for the is reduction of acetaldehyde to ethanol, can using both NAD+ and NADP+ (Fan, Lorenzen and Plapp, 1991). In a more extreme example, the lactate dehydrogenase from the bacterium Bacillus stearothermophilus has been converted, through the mutation of three active site amino acids, into a highly active malate dehydrogenase (Wilks et al., 1988). In both of these cases, the alterations were made in the light of high-resolution structures of the respective proteins and converted the natural enzyme into one with only a slightly altered function. A more difficult problem is to design proteins that have entirely novel functions. Some inroads into this have been achieved by using directed evolution – a method in which multiple rounds of random mutagenesis beginning with a gene encoding a known protein function are combined with selection processes to produce a protein with a specific, and new, function. For example, Olsen et al. used phage display (Chapter 6) and random mutagenesis to isolate proteases with novel substrate specificity (Olsen et al., 2000). This approach is especially successful at generating altered protein characteristics rather than entirely novel proteins. For example, Williams et al. used directed evolution to alter the stereochemical course of a reaction catalysed by tagatose-1,6-bisphosphate aldolase (Williams et al., 2003). After three rounds of mutagenesis and screening, an evolved aldolase was produced, which showed a 100-fold change in stereospecificity toward the non-natural substrate fructose 1,6-bisphosphate. The altered enzyme contains four specific single amino acid changes when compared with the original tagatose-1,6- bisphosphate aldolase, and the changes are spread through the length of the polypeptide. Each of the changes does, however, alter the active site of the protein when it is folded into its three-dimensional form.
