

John Wiley & Sons - 2004 - Analysis of Genes and Genomes
.pdf278 |
PROTEIN PRODUCTION AND PURIFICATION 8 |
|
|
NH |
|
|
O |
|
|
|
|
C |
O |
N |
C |
|
CH2 |
|
OH |
CH |
CH2 |
|
|
||||
|
−O |
N |
|
CH2 NH |
CH |
||
NH |
|
|
|
CH2 |
|||
|
N |
|
|
||||
O C |
|
|
|
CH |
CH2 CH2 |
CH2 CH2O |
|
|
|
Ni2+ |
CH2 |
|
|||
CH |
CH2 |
|
|
|
|
||
|
N |
O− |
C |
|
|
||
|
|
|
|
|
|
||
HN |
|
N |
C |
|
|
|
|
|
|
|
|
|
|||
|
|
|
−O |
O |
O |
|
Resin |
|
|
|
Ni2+-nitriloacetic acid |
|
|||
Protein |
|
|
Spacer |
matrix |
|||
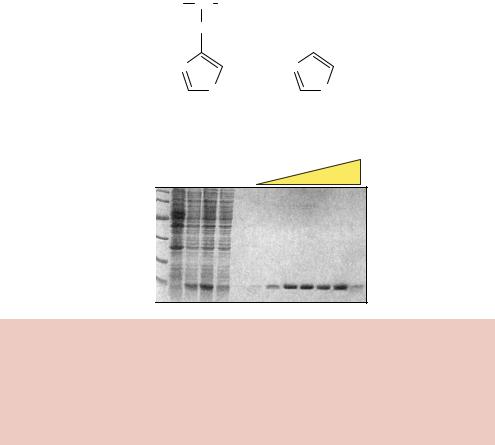
Figure 8.9. The binding of proteins tagged with multiple histidine residues to Ni2+ - NTA resin
The purification of a his-tagged protein from E. coli cells is shown in Figure 8.10. E. coli cells containing an inducible expression vector were grown and induced to produce the tagged target protein. The cells were broken open and insoluble cell debris was removed by centrifugation. The supernatant from this process was applied to a Ni2+-NTA column. The column was washed with a low concentration (20 mM) of imidazole, which will compete with low-affinity histidine –column interactions to remove from the column any, perhaps histidine-rich, proteins that are non-specifically bound. Finally, the tagged protein itself is removed from the column by increasing the concentration of imidazole to a high level (250 mM). This process results in the single-step purification of the tagged protein to yield a very pure, almost homogenous, sample. His-tagged proteins from any expression system including bacteria, yeast, baculovirus, and mammalian cells, can be purified to a high degree of homogeneity using this technique. Alternative elution conditions may also be used. For example, lowering the pH from 8 to 4.5 will alter the protonated state of the histidine residues and results in the dissociation of the protein from the metal complex. The tagged protein can also be removed by adding chelating agents, such as EDTA, to strip the nickel ions from the column and consequently remove the tagged protein.
The small size of the histidine tag means that the tagged recombinant protein often behaves identically to its untagged parent. In some cases, the tagged protein is actually found to be more biologically active than the untagged version of the same protein (Janknecht et al., 1991), although this effect is likely to be due to the speed of the purification process rather than any biological activity of the tag itself. Some proteins have been crystallized in the presence of the his-tag (Kim et al., 1996a). Additionally, the his-tag has extremely low

8.5 PROTEIN PURIFICATION |
281 |
|
|
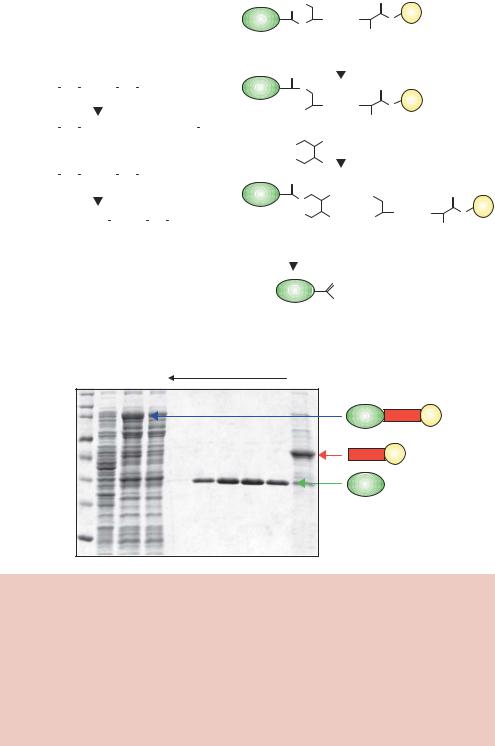
The enzyme from the parasitic flatworm Schistosoma japonicum is a 26 kDa dimeric protein (Walker et al., 1993). The gene encoding this protein is fused, in the correct reading frame, to the target gene and a fusion protein is produced from an expression vector. Host cells producing the fusion protein are broken open and soluble proteins are applied to a column to which glutathione is attached (e.g. glutathione-agarose). The specific interaction between GST and glutathione will result in the binding of the fusion protein to the column, while the majority of host proteins are unable to adhere. The bound protein can then be eluted from the column by washing with a high concentration of glutathione (10 mM) to compete for the interaction with the column (Figure 8.11(c)).
Both the large size of GST and its dimeric nature mean that the tag is more likely to influence the biological activity of the target protein than the his-tag. It is therefore desirable to remove the GST portion of the fusion protein to study the activity of the target protein in isolation. This can be achieved by the inclusion, in the expression vector, of DNA coding for the amino acid sequence of a specific protease cleavage site between GST and the target gene. Treatment of the purified fusion protein with the protease will then result in the generation of two polypeptides – the free target protein and GST itself. GST can then be removed from the target protein by applying the mixture back onto a glutathione column. The GST will, again, bind to the column, but the target protein will not. The column flow-through can be collected and will contain the purified target protein.
A variety of specific proteases have been used to cleave purification tags
from |
target |
fusion proteins (Table 8.2). Unlike restriction enzymes when |
they |
cleave |
DNA (see Chapter 2), many proteases do not have an abso- |
lute sequence requirement for their cleavage sites. For example, the protease Factor Xa cleaves after the arginine residue in its preferred cleavage site Ile – Glu –Gly– Arg. However, it will sometimes cleave at other basic residues, depending on the conformation of the protein substrate, and a number of the secondary sites have been sequenced that show cleavage following Gly–Arg dipeptides (Quinlan, Moir and Stewart, 1989). Consequently, the protease may not only cleave the site between the tag and the target protein, but many also cleave the target protein itself. Obviously, this must be avoided to maintain the integrity of the target protein. Other proteases, e.g. the TEV and PreScission proteases, have larger and more specific recognition sequences and are less likely to cleave at alternative sites. The TEV protease has the added advantage that the protease can be produced in a recombinant form from E. coli and is therefore not contaminated with other plasma proteases and factors.

282 |
PROTEIN PRODUCTION AND PURIFICATION 8 |
|
|
Table 8.2. Site-specific proteases. The recognition sequence of each protease is shown, together with the actual site of cleavage, depicted by the arrow
Protease |
Recognition and |
Notes |
Reference |
|
cleavage site |
|
|
|
|
|
|
Factor Xa |
IleGluGlyArg↓ |
42 kDa protein, composed |
(Nagai, Perutz and |
|
|
of two disulphide linked |
Poyart, 1985) |
|
|
chains, purified from |
|
|
AspAspAspAspLys↓ |
bovine plasma |
|
Enterokinase |
26 kDa light chain of |
(LaVallie et al., 1993b) |
|
|
|
bovine enterokinase |
|
|
|
produced in and purified |
|
|
LeuValProArg↓ |
from E. coli |
|
Thrombin |
Purified from bovine |
(Chang, 1985) |
|
|
GlySer |
plasma |
|
TEV |
GluAsnLeuTyr- |
Tobacco etch virus protease |
(Dougherty et al., 1989) |
|
PheGln↓Gly |
|
|
PreScission |
LeuGluValLeuPhe |
Protease from the 3C |
(Walker et al., 1994) |
|
Gln↓ GlyPro |
human rhinovirus |
|
8.5.3 The MBP-tag
The target gene is inserted downstream from the malE gene of E. coli, which encodes maltose binding protein (MBP), in an expression vector that results in the production of an MBP fusion protein (Kellermann and Ferenci, 1982). Maltose is a disaccharide composed of two molecules of glucose (Figure 8.12(a)). MBP is a 40 kDa monomeric protein that forms part of the maltose/maltodextrin system of E. coli, which is responsible for the uptake and efficient catabolism of glucose polymers (Boos and Shuman, 1998). The protein undergoes a large conformational change upon binding of maltose, and results in the formation of a stable complex (Figure 8.12(b)). One-step purification of fusion proteins is achieved using the affinity of MBP for cross-linked amylose (starch) (di Guan et al., 1988). Bound proteins can be eluted from amylose by including maltose (10 mM) in the column buffer (Figure 8.12(c)).
8.5.4IMPACT
Intein mediated purification with an affinity chitin binding tag (IMPACT) is an approach to protein purification that uses the protein self-splicing of

284 |
PROTEIN PRODUCTION AND PURIFICATION 8 |
|
|
inteins to remove the purification tag and give pure isolated protein in one chromatographic step. Inteins are a class of proteins, found in a wide variety of organisms, that excise themselves from a precursor protein and in the process ligate the flanking protein sequences (exteins) (Cooper and Stevens, 1995). The excised intein is a site-specific DNA endonuclease that catalyses genetic mobility of its own DNA coding sequence. The process of polypeptide cleavage and ligation is dependent on specific chemistry involving thiols and a conserved asparagine residue.
Most inteins have a cysteine residue at their amino-terminal end and an asparagine at their carboxy-terminal end (Figure 8.13(a)). All the information required for the splicing reaction is contained within the intein itself, and if these sequences are placed in the context of a target protein they still splice themselves out. The mechanism of splicing is complex, but the reaction is very efficient. The IMPACT expression system exploits this unusual chemistry by mutation of the C-terminal asparagine to alanine in a yeast intein, VMA1 (Chong and Xu, 1997). This mutation prevents the cleavage reaction occurring at the carboxy-terminal side of the intein and traps the protein in a thioester that can be cleaved by β-mercaptoethanol or dithiothreitol (DTT). The target gene is cloned into an expression vector such that a three-component fusion protein is produced, in which a target protein – intein –chitin binding domain fusion is produced. Chitin is a fibrous insoluble polysaccharide made of β-1,4- N-acetyl-D-glucosamine that is found in the cell walls of fungi and algae and in the exoskeletons of arthropods. Chitinase catalyses the hydrolytic degradation of chitin, and the Bacillus circulans enzyme (Mr 74 kDa) is composed of three domains – an amino-terminal catalytic domain (CatD) (417 amino acid residues), a tandem repeat of fibronectin type III-like (FnIII) domains (duplicate 95 residues) and a carboxy-terminal chitin-binding domain (CBD, 45 amino acid residues) (Watanabe et al., 1990). The isolated CBD shows high-affinity binding to chitin.
In the IMPACT system, the fusion protein is made in E. coli and passed down the chitin column, where it binds. The protein can be cleaved off the column by using thiol containing compounds, such as DTT, at 4 ◦C. This is a slow process and requires an overnight incubation to complete, which may prove problematical if the target protein is not stable under these conditions. The final target protein produced by this method is native except for the DTT thioester moiety attached at the carboxy-terminal end. The thioester is, however, unstable and will spontaneously hydrolyse to yield a native protein. Other thiols can also be used to initiate the cleavage process, e.g. β-mercaptoethanol and cysteine. Cysteine induced cleavage results in the insertion of a cysteine amino acid residue at the carboxy-terminal end of the cleaved polypeptide. The cysteine
 SDS
SDS286 |
PROTEIN PRODUCTION AND PURIFICATION 8 |
|
|
can be radio-labelled, or it can be a site for chemical modification, especially if it is the only cysteine in the protein, since it is a good site to add protein cross-linkers, fluorescent probes, spin labels or other tags.
8.5.5TAP-tagging
An extension of tagging over-produced proteins for purification is to tag proteins produced at wild-type levels in their native host cells. Protein purification in these circumstances, if performed under suitably mild conditions, can lead to the isolation of naturally occurring protein complexes. Most proteins do not exist as single entities within cells. They are associated, through non-covalent interactions, with a variety of other proteins that may be involved in the regulation of their function. The over-production of a single protein will not result in the over-production of other proteins in the complex. Therefore, to isolate complexes from cells, protein production should be as close to the
natural state as possible. The DNA encoding what is termed a tandem affinity purification tag (TAP-tag) is cloned at the 3 -end of a target gene so that little disruption is made to its ability to be transcribed, and the fusion protein should be produced at the same level as the wild-type target protein. The TAP-tag encodes two purification elements – a calmodulin binding peptide and Protein A from Staphylococcus aureus. These elements are separated by a TEV protease cleavage site (Puig et al., 2001). Cells containing the tagged protein are gently lysed and then applied to a column containing IgG, which binds with high affinity to Protein A. The fusion protein, and its associated proteins, are removed
from the column using TEV protease and then applied directly to a calmodulin bead column, in the presence of Ca2+, and eluted using the chelating agent EDTA. The two-step purification procedure is highly specific and can result in the isolation of contaminant-free protein complexes. The TAP-tag allows the rapid purification of complexes from a relatively small number of cells without prior knowledge of the complex composition, activity or function (Rigaut et al., 1999; Gavin et al., 2002), and, combined with mass spectrometry, the TAP strategy allows for the identification of proteins interacting with a given target protein.
