

4. Технология оценки тесноты связи исследуемых признаков на основе линейного коэффициента корреляции
Сервис – Анализ данных – Корреляция – ОК. Появляется окно «Корреляция» (рис. 8.32).
Входной интервал – диапазон ячеек таблицы со значениями признака У (В3:В7).
Входной интервал Х – диапазон ячеек таблицы со значениями факторного и результативного признаков (А3:В7).

Рис. 8.32. Окно «Корреляция»
Группирование – по столбцам;
Метки в первой строке – не активизировать.
Выходной интервал – ячейка с параметрами D3.
Н
 овый
рабочий лист / Новая рабочая книга
– не активизировать (рис. 8.33) ОК.
овый
рабочий лист / Новая рабочая книга
– не активизировать (рис. 8.33) ОК.
Рис. 8.33. Окно «Корреляция» с заданными параметрами
В результате работы алгоритма Excel выдает оценку тесноты связи факторного и результативного признаков (табл. 8.61).
Таблица 8.61
Значение линейного коэффициента корреляции
|
|
Столбец 1 |
Столбец 2 |
|
Столбец 1 |
1 |
|
|
Столбец 2 |
0,912292 |
1 |
Простым линейным уравнением регрессии является выражение:
![]() =a0+a1x
=a0+a1x
где
![]() - теоретические расчетные значения
результативного признака, полученные
по уравнению регрессии; а0,
а1
– независимые параметры уравнения
регрессии:
- теоретические расчетные значения
результативного признака, полученные
по уравнению регрессии; а0,
а1
– независимые параметры уравнения
регрессии:
 ;
;
![]() .
.
Теснота
корреляционной связи между переменными
х и у, которая измеряется эмпирическим
корреляционным отношением
![]() ,
когда
,
когда
![]() (межгрупповая дисперсия) характеризует
отклонения групповых средних
результативного признака от общей
дисперсии:
(межгрупповая дисперсия) характеризует
отклонения групповых средних
результативного признака от общей
дисперсии:

Подкоренное выражение корреляционного отношения представляет собой коэффициент детерминации (меры определенности, причинности).
Коэффициент детерминации показывает долю вариации результативного признака под влиянием вариации признака-фактора.
Кроме того, при линейной форме уравнения применяется другой показатель тесноты связи – линейный коэффициент корреляции, который находится по формуле:
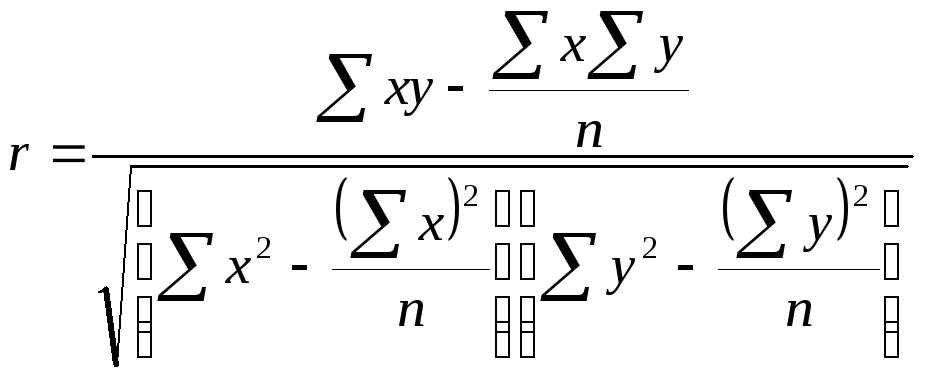
Значение
линейного коэффициента корреляции
важно для исследования социально-экономических
явлений и процессов, распределение
которых близко к нормальному. Он принимает
значение в интервале: - 1
![]() r
r
![]() 1.
1.
Отрицательное
значение указывает на обратную связь,
положительное на прямую. При r
= 0 линейная связь отсутствует. Чем ближе
коэффициент корреляции по абсолютной
величине к единице, тем теснее связь
между признаками. При r
=
![]() 1
связь функциональная.
1
связь функциональная.
Для оценки значимости коэффициента корреляции r используют t-критерий Стьюдента, который применяется при t – распределении, отличном от нормального.
t-критерий рассчитывается по формуле:
![]()
где
(n-2)
– число степеней свободы при заданном
уровне значимости
![]() и объеме выборкиn.
и объеме выборкиn.
Рассмотрим следующий конкретный пример анализа маркетинговой информации. Проведем обработку результатов маркетинговых исследований с построением модели для предсказания объема реализации одного из продуктов фирмы.
Примем обозначения. Объем выпуска, шт. - это зависимая переменная Y. В качестве независимых, объясняющих переменных выбраны: затраты на рекламу, тыс. руб. -Х 1 ; цена, тыс.руб.- Х2 ; суммарные расходы потребителя, тыс. руб.-Х3 ; численность персонала, чел – Х4. Построим систему показателей (факторов) и проанализируем матрицу коэффициентов парной корреляции. Статистические данные по всем переменным приведены в табл. 8.62.
В этом примере число статистических уровней n =7, число независимых факторов m = 4.
Таблица 8.62
Исходные статистические данные
|
Года |
Объем выпуска, шт. |
Затраты на рекламы, тыс. руб. |
Цена, тыс.руб. |
Суммарные расходы потребителя, тыс. руб. |
Численность персонала, чел. |
|
|
Y |
X1 |
X2 |
X3 |
Х |
|
2002 |
7050 |
125 000 |
43 300 |
17 700 |
957 |
|
2003 |
8 000 |
159 700 |
51 700 |
20 900 |
1 000 |
|
2004 |
10025 |
179 749 |
54 500 |
25 400 |
1 027 |
|
2005 |
12100 |
200 157 |
56 000 |
27 100 |
1 077 |
|
2006 |
14170 |
220 565 |
60 100 |
30 500 |
1 127 |
|
2007 |
16159 |
227 456 |
64 500 |
35 000 |
1 170 |
|
2008 |
18188 |
300 000 |
68 700 |
37 500 |
1 215 |
Для проведения корреляционного анализа выполним следующие действия: данные для корреляционного анализа должны располагаться в смежных диапазонах ячеек; выбрать команду Сервис =>Анализ данных. В диалоговом окне Анализ данных выбрать инструмент Корреляция (рис. 8.34), а затем щелкнуть на кнопке ОК:

Рис. 8.34. Выбор инструмента корреляция
В диалоговом окне Корреляция в поле «Входной интервал» необходимо ввести диапазон ячеек, содержащих исходные данные. Если выделены и заголовки столбцов, то установить флажок «Метки в первой строке» (рис. 8.35); выбрать параметры вывода. В данном примере установить переключатель «Новый рабочий лист»; нажать ОК.

Рис. 8.35. Диалоговое окно корреляция подготовлено к выполнению
анализа данных
В итоге компьютер напечатает на экране матрицу коэффициентов парной корреляции, которая отражает тесноту связи между показателями (рис. 8.36).

Рис. 8.36. Матрица коэффициентов парной корреляции
Анализ
матрицы коэффициентов парной корреляции,
показывает, что зависимая переменная,
т.е. объем выпуска, имеет сильную связь
с численностью персонала (ryx![]() = 0,997); с суммарными расходами потребителя
( ryx
= 0,997); с суммарными расходами потребителя
( ryx![]() = 0,992); с ценой (ryx
= 0,992); с ценой (ryx![]() = 0, 969); с затратами на рекламу ( ryx
= 0, 969); с затратами на рекламу ( ryx![]() = 0,962).
= 0,962).
Одним из условий регрессионной модели является предположение о линейной независимости объясняющих переменных, т.е. решение задачи возможно лишь тогда, когда столбцы и строки матрицы исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется мулътиколлинеарностью и приводит к линейной зависимости нормальных уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров модели. Считают явление мультиколлинеарности в исходных данных установленным, если коэффициент парной корреляции между двумя переменными больше 0.8. В нашем примере факторы X3 и X4 тесно связаны между собой (rх3x4 = 0,979), что свидетельствует о наличии мультиколлинеарности. Чтобы избавиться от мультиколлинеарности, в модель включим лишь один из линейно связанных между собой факторов, причем тот, который в большей степени связан с зависимой переменной.- X4. После исключения факторов Х1 ,X2 ,X3 получим n= 4, k = 1.
Для проведения регрессионного анализа выполняются следующие действия: выбрать команду Сервис =>Анализ данных; в диалоговом окне Анализ данных выбрать инструмент Регрессия (рис. 8.37), а затем щелкнуть на кнопке Ок;

Рис. 8.37. Диалоговое окно анализ данных
Далее:
в диалоговом окне Регрессия в поле «Входной интервал Y» вводится адрес диапазона ячеек, который представляет зависимую переменную. В поле «Входной интервал Х» вводится адрес диапазона ячеек, который содержит значения независимой переменной (рис. 8.39);
установить флажок Метки в первой строке, т.к. мы выделяем заголовки столбцов.
Выбрать параметры вывода. В данном примере – установить переключатель «Новая рабочая книга».
В поле «Остатки» поставить необходимые флажки и нажать Ок.

Рис. 8.39. Диалоговое окно Регрессия подготовлено к выполнению анализа данных
Проведем оценку качества и адекватности построенной модели (табл. 8.63).
Таблица 8.63
|
Вывод итогов | |
|
Регрессионная статистика | |
|
Множественный R |
0,997347696 |
|
R-квадрат |
0,994702427 |
|
Нормированный R-квадрат |
0,993642912 |
|
Стандартная ошибка |
332,4291594 |
|
Наблюдения |
7 |
Пояснения к таблице 8.63.
|
Регрессионная статистика | |||
|
№ |
Наименование в отчете EXCEL |
Принятые наименования |
Формула |
|
1 |
Множественный R |
Коэффициент множественной корреляции, индекс корреляции |
R
= |
|
2 |
R-квадрат |
Коэффициент детерминации, R2 |
R2
= 1- |
|
3 |
Нормированный R-квадрат |
Скорректированный R2 |
R2
= 1- (1- R2 )
|
|
4 |
Стандартная ошибка |
Стандартная ошибка оценки |
Se
=
|
|
5 |
Наблюдения |
Количество наблюдений,n |
n |

Коэффициент парной корреляции (множественный R) показывает, что зависимость наблюдениями в выборке положительная, т.е. с увеличением численности персонала произойдет рост объема выпуска. Коэффициент детерминации, R2=0,994702427, означает, что не менее 99,4% вариации объема выпуска (т.е. доли его изменения) объясняется вариацией численности персонала. Следовательно, численность персонала является весомым фактором, способным помочь в прогнозировании объема. Нормированный R2 показывает, насколько добавление новой переменной может улучшить качество товаров, однако в качестве диагностической величины с целью экономии трудозатрат этот фактор используется крайне редко потому, что при увеличении количества переменных и числа наблюдений его значение не всегда может меняться в сторону повышения. Стандартная ошибка дает лишь общую оценку степени точности коэффициента регрессии, но она не несет информации о том, где находится полученное отклонение: в конце или середине распределения, и поэтому, относительно неточна.
Дальнейший анализ используется для определения значимости совместного вклада группы переменных (табл. 8.64).
Таблица 8.64
Расчетная таблица
|
Дисперсионный анализ | |||||
|
|
df |
SS |
MS |
F |
Значимость F |
|
Регрессия |
1 |
103749123,7 |
103749123,7 |
938,8283903 |
6,94856E-07 |
|
Остаток |
5 |
552545,7302 |
110509,146 |
|
|
|
Итого |
6 |
104301669,4 |
|
|
|
Пояснения к таблице 8.64:
|
Показатели |
Df- число степеней свободы |
SS- сумма квадратов |
MS |
F- критерий Фишера |
|
Регрессия |
k=1 |
|
|
F=
|
|
Остаток |
n-k-1=5 |
|
|
|
|
Итого |
n-1=6 |
|
|
|
Для проверки значимости модели регрессии используется F- критерий Фишера. Расчетное значение F сравнивается с табличным Fтабл. Значение величины Fтабл с 1 и 5 степенями свободы (Df), при α = 0,05 , равно 6,61.
F=
![]() .
.
Так как F> Fтабл., то уравнение модели признается значимым.
В таблице 8.65 содержится информация для построения зависимости общего объема выпуска от численности персонала, причем во втором столбце содержатся коэффициенты уравнения регрессии а0, и а1. В третьем столбце содержатся стандартные ошибки коэффициентов уравнения регрессии, а в четвертом - t-статистика используемая для проверки значимости коэффициентов уравнения регрессии и представляющая собой оценку коэффициента, деленную на ее стандартную ошибку.
Таблица 8.65
Таблица построения регрессии
|
Параметры |
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
Y-пересечение |
-35688,73138 |
1569,331 |
-22,74135 |
3,0568E-06 |
-39722,82738 |
-31654,6 |
-39722,8 |
-31654,63 |
|
Х - численность персонала, чел. |
44,3038584 |
1,445933 |
30,64030 |
6,94856E-07 |
40,58696 |
48,020 |
40,5869 |
48,02074 |
Линейное уравнение регрессии зависимости общего объема выпуска Y от численности персонала Х1, полученное с помощью EXCEL, имеет вид:
Y = -35688,73138+44,3038584 Х1
Расчетные значения Y определяются путём последовательной подстановки в эту модель значений факторов X1, взятых для каждого момента времени t. Оценить качество модели, проследить степень ее точности, помогут вычисленные отклонения и предсказанные значения исследуемой переменной Y (таблица 8.66)
Таблица 8.66
Вычисленные по модели значения Y и значения остаточной компоненты
|
Вывод остатка | ||
|
Наблюдение |
Предсказанный объем выпуска, шт. |
Остатки |
|
1 |
6710,061108 |
339,9388916 |
|
2 |
8615,12702 |
-615,1270196 |
|
3 |
9811,331196 |
213,6688036 |
|
4 |
12026,52412 |
73,47588365 |
|
5 |
14241,71704 |
-71,71703631 |
|
6 |
16146,78295 |
12,21705252 |
|
7 |
18140,45658 |
47,54342456 |
Качество модели оценивается стандартным для математических моделей образом, по адекватности на основе анализа остатков регрессии. Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов.
Независимость остатков проверяется с помощью критерия Дарбина-Уотсона.
d=
![]()
Расчет коэффициента Дарбина – Уотсона приведен на рис. 8.40.

Рис. 8.40. Расчет коэффициента Дарбина – Уотсона
Если d >2, то возникает предположение об отрицательной автокорреляции в остатках и тогда с критическими значениями сравнивается не d, а 4- d и делаются аналогичные выводы. В нашем случае значение d =2,63, т.е. можно предположить отрицательную автокорреляцию в остатках.
Построим график остатков с добавление тренда на 2 периода вперед (рис. 8.41). Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. График остатков показывает, что отклонений от модели наблюдения нет.

Рис. 8.41. График остатков
Для наглядного сравнения истинных и предсказанных по модели величин необходимо построить график подбора (рис. 8.42).

Рис. 8.42. График подбора
Рассчитанный по модели объем выпуска, достаточно близко отражает колебания реальной величины, одновременно сглаживая её резкие изменения. Графическое изображение наблюдаемого и предсказанного объемов реализации, доказывает точность полученной модели, что позволит её использовать в целях прогнозирования объемов выпуска товара. Было бы весьма интересно оценить прогнозную силу модели на практике, но в любом случае, предприятию совершенно нельзя придерживаться какой-либо единственной точки зрения или рекомендации, поскольку наиболее успешным результатом станет лишь объединение их максимального числа.