

Тема 28. Методы первичной статистической обработки
Цель:
Вычисление средней арифметической.
Определение моды и медианы.
Определение дисперсии, стандартного отклонения, асимметрии.
Установление распределения данных.
На первой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы, а для наглядного представления данных строятся различные диаграммы и графики. Все эти манипуляции позволяют, во-первых, обнаружить и ликвидировать ошибки, совершенные при фиксации данных, и, во-вторых, выявить и изъять из общего массива нелепые данные, полученные в результате нарушения процедуры обследования, несоблюдения испытуемыми инструкции и т. п.
Прежде всего, для полученных данных определяют меры центральной тенденции, а именно среднее арифметическое значение на данной выборке, а так же моду, медиану и дисперсию.
1. Среднее арифметическое – это сумма всех значений, полученная на данной выборке испытуемых, и деленная на количество этих значений. Данная величина вычисляется по формуле:
![]() =
=
![]() =
=
![]()
![]() (Х1+
Х2+
…+ХN)
(Х1+
Х2+
…+ХN)
где
–
Среднее значение; N
– Количество значений;
![]() –
сумма всех значений
–
сумма всех значений
2. Медиана (Ме)– Медианой называется значение, которое делит ряд возрастающих (или убывающих) значений на две части, равные по числу значений. Если количество значений ряда нечетно (2n+1), то медиана=Xn+1, при четном (2n) медиана равна (Xn+Xn+1)/2. Например: в существующем множестве (3344455) Ме = 4
Мода (Мо) – типичное значение, которое встречается наиболее часто. Например: в существующем множестве (3344555) Мо = 5
Среднее значение, медиана и мода служат одной цели, а именно, обеспечению одного значения, обобщающего все значения выборки. Однако, каждое из них представляет выборку по разному. Обычно чаще всего используется среднее значение выборки. Поскольку при вычислении среднего значения делается суммирование всех значений выборки, оно является действительно отражением всех элементов выборки. Основным недостатком среднего значения является чувствительность к одному экстремальному значению. Например, пусть в некой фирме "Уидгeт" заработок владельца составляет 100000 долларов в год, а заработок каждого из девяти рабочих составляет 10 000 долларов в год. Средний заработок в этой фирме будет равен 19 000долларов в год, однако эта цифра недостаточно правильно описывает ситуацию в фирме.
В случаях, аналогичных описанному, иногда вместо среднего значения используется мода. Мода заработков в фирме "Уидгeт" равна 10 000 долларов в год и эта цифра более правильно отражает реальную ситуацию в фирме. Однако, мода также может вводить в заблуждение. Пусть некоторая автомобильная фирма производит автомобили пяти различных цветов. За некоторую неделю было получено: - 100 зеленых автомобилей; - 100 оранжевых автомобилей; - 150 синих автомобилей; - 200 черных автомобилей; - 190 белых автомобилей.
Здесь модой выборки являются черные автомобили, поскольку было произведено 200 черных автомобилей, что превышает число автомобилей любого другого цвета. Однако, неправильно делать вывод о том, что автомобильная фирма производит в основном автомобили черного цвета.
Медиана представляет интерес для тех случаев, когда оправдано предположение о нормальном распределении. Например, если выборка представляет собой следующий набор: 1 2 3 4 5 6 7 8 9 10
то медианой будет 5 или 6, а среднее значение 5,5. В этом случае медиана близка к среднему значению. Однако, в следующей выборке 1 1 1 1 5 100 100 100 100 медиана по-прежнему равна 5, а среднее значение приблизительно равно 46.
В определенных случаях ни среднее значение, ни медиана, ни мода не могут дать достоверную картину. Это приводит к использованию двух наиболее важных статистических величин - дисперсии и стандартного отклонения.
3. Дисперсия (variance)
На практике часто требуется оценить рассеяние возможных значений случайной величины вокруг ее среднего значения. Дисперсией (рассеянием) случайной величины называют математическое ожидание (среднее) квадрата отклонения случайной величины от ее математического ожидания (среднего). Термин впервые введен Фишером в 1918 году. Дисперсия вычисляется по формуле:
![]()
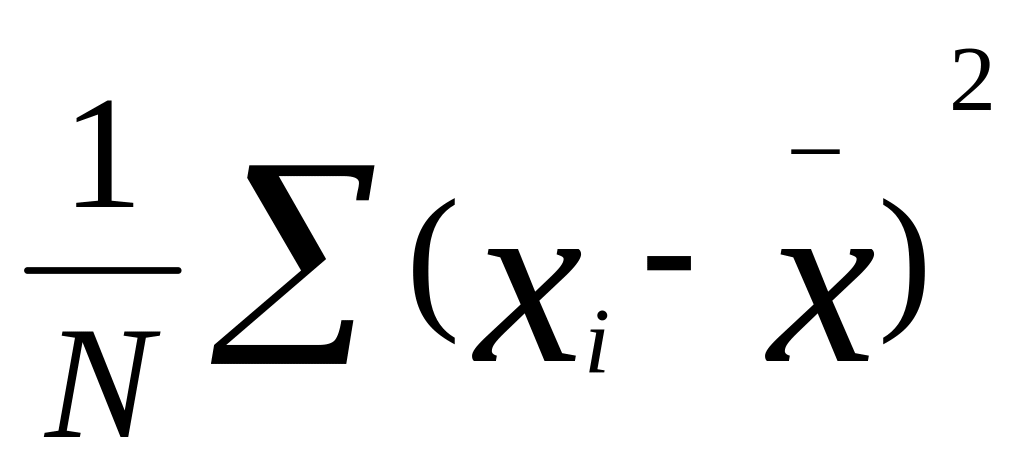
![]()
где
![]() — среднее арифметическое, N — число
значений в выборке.
— среднее арифметическое, N — число
значений в выборке.
Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает отсутствие изменчивости, т.е. отсутствие разброса значений на выборке, а именно, когда значения переменной постоянны.
Стандартное отклонение, среднее квадратическое отклонение (от английского standard deviation) вычисляется как корень квадратный из дисперсии. Стандартное отклонение более значимая величина, чем диспепсия. Чем выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего.
![]()
Пример:
Классы |
|
|
|
Экспериментальный |
19 |
1 |
1 |
Контрольный |
19 |
48,5 |
8 |
Это означает, что в одном классе посещаемость высокая, стабильная, а в другом - отличается непостоянством.
Ассиметрия – это свойство распределения выборки, которое характеризует несимметричность распределения. На практике симметричные распределения встречаются редко и чтобы выявить и оценить степень асимметрии, вводят следующую меру:
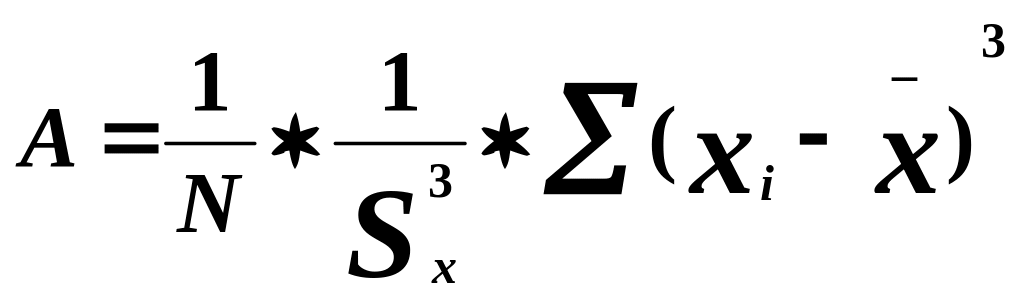
Асимметрия бывает положительной и отрицательной. Положительная сдвигается влево, а отрицательная – вправо. Т.е. асимметрия это мера несимметричности графика распределения.
Эксцесс – это мера крутости кривой распределения. Симметричное отклонение, деформация графика распределения. Эксцесс равен:
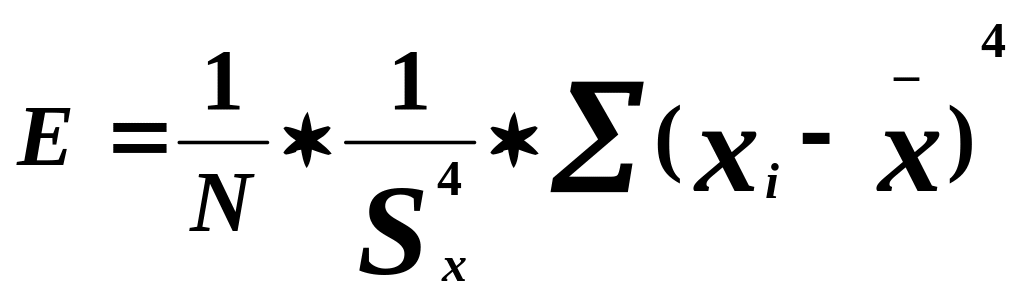
Кривая распределения может быть островершинной, плосковершинной, средне вершинной. Эти четыре момента составляют набор особенностей распределения при анализе данных. Для нормального распределения А=0, Е=3.
4. Кроме того, первично обработанные данные, представляют в удобной для обозрения форме, в виде графиков. Это дает исследователю в первом приближении представление о характере всей совокупности данных в целом: об их однородности – неоднородности, компактности - разбросанности, четкости – размытости и т. д. Эта информация хорошо читается на наглядных формах представления данных и связана с понятием «распределение данных».
Нормальное распределение данных считается в том случае если относительно вертикальной черты, характеризующей среднее значение на данной выборке, существует симметричное распределение данных (т.е. полигон (площадь) данных по обе стороны среднего значения выборки примерно одинаков). Под выборкой понимается все множество полученных в исследовании значений изучаемого признака (свойства, качества, состояния) объекта.
Н апример:
апример:
Относительно среднего значения 4.5, мы видим, что кривая графика (линия 1 и плавно повторяющая ее – линия 2) не является симметричной, но при ориентации на полигон данных, который размещен по обе стороны от среднего значения, видно, что площади примерно равны. Это означает, нормальное распределение данных
Если А<0 тогда графически область (площадь, полигон) с левой стороны от среднего значения данных, будет больше чем с правой стороны. Если А>0 тогда графически область (площадь, полигон) с правой стороны от среднего значения данных, будет больше чем с левой стороны.
При А=0 графически полигон значений относительно среднего значения, будет одинаков.
Если Е=3, то это считается нормой, если Е<3 тогда график распределения данных будет выглядеть излишне плосковершинным, что будет говорить о большом разбросе данных. Если Е>3, то график будет островершинным, что говорит о малом разбросе и большом количестве одинаковых данных.