

- •List of Tables
- •List of Figures
- •Table of Notation
- •Preface
- •Boolean retrieval
- •An example information retrieval problem
- •Processing Boolean queries
- •The extended Boolean model versus ranked retrieval
- •References and further reading
- •The term vocabulary and postings lists
- •Document delineation and character sequence decoding
- •Obtaining the character sequence in a document
- •Choosing a document unit
- •Determining the vocabulary of terms
- •Tokenization
- •Dropping common terms: stop words
- •Normalization (equivalence classing of terms)
- •Stemming and lemmatization
- •Faster postings list intersection via skip pointers
- •Positional postings and phrase queries
- •Biword indexes
- •Positional indexes
- •Combination schemes
- •References and further reading
- •Dictionaries and tolerant retrieval
- •Search structures for dictionaries
- •Wildcard queries
- •General wildcard queries
- •Spelling correction
- •Implementing spelling correction
- •Forms of spelling correction
- •Edit distance
- •Context sensitive spelling correction
- •Phonetic correction
- •References and further reading
- •Index construction
- •Hardware basics
- •Blocked sort-based indexing
- •Single-pass in-memory indexing
- •Distributed indexing
- •Dynamic indexing
- •Other types of indexes
- •References and further reading
- •Index compression
- •Statistical properties of terms in information retrieval
- •Dictionary compression
- •Dictionary as a string
- •Blocked storage
- •Variable byte codes
- •References and further reading
- •Scoring, term weighting and the vector space model
- •Parametric and zone indexes
- •Weighted zone scoring
- •Learning weights
- •The optimal weight g
- •Term frequency and weighting
- •Inverse document frequency
- •The vector space model for scoring
- •Dot products
- •Queries as vectors
- •Computing vector scores
- •Sublinear tf scaling
- •Maximum tf normalization
- •Document and query weighting schemes
- •Pivoted normalized document length
- •References and further reading
- •Computing scores in a complete search system
- •Index elimination
- •Champion lists
- •Static quality scores and ordering
- •Impact ordering
- •Cluster pruning
- •Components of an information retrieval system
- •Tiered indexes
- •Designing parsing and scoring functions
- •Putting it all together
- •Vector space scoring and query operator interaction
- •References and further reading
- •Evaluation in information retrieval
- •Information retrieval system evaluation
- •Standard test collections
- •Evaluation of unranked retrieval sets
- •Evaluation of ranked retrieval results
- •Assessing relevance
- •A broader perspective: System quality and user utility
- •System issues
- •User utility
- •Results snippets
- •References and further reading
- •Relevance feedback and query expansion
- •Relevance feedback and pseudo relevance feedback
- •The Rocchio algorithm for relevance feedback
- •Probabilistic relevance feedback
- •When does relevance feedback work?
- •Relevance feedback on the web
- •Evaluation of relevance feedback strategies
- •Pseudo relevance feedback
- •Indirect relevance feedback
- •Summary
- •Global methods for query reformulation
- •Vocabulary tools for query reformulation
- •Query expansion
- •Automatic thesaurus generation
- •References and further reading
- •XML retrieval
- •Basic XML concepts
- •Challenges in XML retrieval
- •A vector space model for XML retrieval
- •Evaluation of XML retrieval
- •References and further reading
- •Exercises
- •Probabilistic information retrieval
- •Review of basic probability theory
- •The Probability Ranking Principle
- •The 1/0 loss case
- •The PRP with retrieval costs
- •The Binary Independence Model
- •Deriving a ranking function for query terms
- •Probability estimates in theory
- •Probability estimates in practice
- •Probabilistic approaches to relevance feedback
- •An appraisal and some extensions
- •An appraisal of probabilistic models
- •Bayesian network approaches to IR
- •References and further reading
- •Language models for information retrieval
- •Language models
- •Finite automata and language models
- •Types of language models
- •Multinomial distributions over words
- •The query likelihood model
- •Using query likelihood language models in IR
- •Estimating the query generation probability
- •Language modeling versus other approaches in IR
- •Extended language modeling approaches
- •References and further reading
- •Relation to multinomial unigram language model
- •The Bernoulli model
- •Properties of Naive Bayes
- •A variant of the multinomial model
- •Feature selection
- •Mutual information
- •Comparison of feature selection methods
- •References and further reading
- •Document representations and measures of relatedness in vector spaces
- •k nearest neighbor
- •Time complexity and optimality of kNN
- •The bias-variance tradeoff
- •References and further reading
- •Exercises
- •Support vector machines and machine learning on documents
- •Support vector machines: The linearly separable case
- •Extensions to the SVM model
- •Multiclass SVMs
- •Nonlinear SVMs
- •Experimental results
- •Machine learning methods in ad hoc information retrieval
- •Result ranking by machine learning
- •References and further reading
- •Flat clustering
- •Clustering in information retrieval
- •Problem statement
- •Evaluation of clustering
- •Cluster cardinality in K-means
- •Model-based clustering
- •References and further reading
- •Exercises
- •Hierarchical clustering
- •Hierarchical agglomerative clustering
- •Time complexity of HAC
- •Group-average agglomerative clustering
- •Centroid clustering
- •Optimality of HAC
- •Divisive clustering
- •Cluster labeling
- •Implementation notes
- •References and further reading
- •Exercises
- •Matrix decompositions and latent semantic indexing
- •Linear algebra review
- •Matrix decompositions
- •Term-document matrices and singular value decompositions
- •Low-rank approximations
- •Latent semantic indexing
- •References and further reading
- •Web search basics
- •Background and history
- •Web characteristics
- •The web graph
- •Spam
- •Advertising as the economic model
- •The search user experience
- •User query needs
- •Index size and estimation
- •Near-duplicates and shingling
- •References and further reading
- •Web crawling and indexes
- •Overview
- •Crawling
- •Crawler architecture
- •DNS resolution
- •The URL frontier
- •Distributing indexes
- •Connectivity servers
- •References and further reading
- •Link analysis
- •The Web as a graph
- •Anchor text and the web graph
- •PageRank
- •Markov chains
- •The PageRank computation
- •Hubs and Authorities
- •Choosing the subset of the Web
- •References and further reading
- •Bibliography
- •Author Index
480 |
21 Link analysis |
Exercise 21.20
How would you interpret the entries of the matrices AAT and AT A? What is the connection to the co-occurrence matrix CCT in Chapter 18?
Exercise 21.21
What are the principal eigenvalues of AAT and AT A?
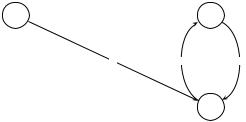
d1  d2
d2
d3
Figure 21.7 Web graph for Exercise 21.22.
Exercise 21.22
For the web graph in Figure 21.7, compute PageRank, hub and authority scores for each of the three pages. Also give the relative ordering of the 3 nodes for each of these scores, indicating any ties.
PageRank: Assume that at each step of the PageRank random walk, we teleport to a random page with probability 0.1, with a uniform distribution over which particular page we teleport to.
Hubs/Authorities: Normalize the hub (authority) scores so that the maximum hub (authority) score is 1.
Hint 1: Using symmetries to simplify and solving with linear equations might be easier than using iterative methods.
Hint 2: Provide the relative ordering (indicating any ties) of the three nodes for each of the three scoring measures.
21.4References and further reading
Garfield (1955) is seminal in the science of citation analysis. This was built on by Pinski and Narin (1976) to develop a journal influence weight, whose definition is remarkably similar to that of the PageRank measure.
The use of anchor text as an aid to searching and ranking stems from the work of McBryan (1994). Extended anchor-text was implicit in his work, with systematic experiments reported in Chakrabarti et al. (1998).
Kemeny and Snell (1976) is a classic text on Markov chains. The PageRank measure was developed in Brin and Page (1998) and in Page et al. (1998).
Online edition (c) 2009 Cambridge UP
21.4 References and further reading |
481 |
A number of methods for the fast computation of PageRank values are surveyed in Berkhin (2005) and in Langville and Meyer (2006); the former also details how the PageRank eigenvector solution may be viewed as solving a linear system, leading to one way of solving Exercise 21.16. The effect of the teleport probability α has been studied by Baeza-Yates et al. (2005) and by Boldi et al. (2005). Topic-specific PageRank and variants were developed in Haveliwala (2002), Haveliwala (2003) and in Jeh and Widom (2003). Berkhin (2006a) develops an alternate view of topic-specific PageRank.
Ng et al. (2001b) suggests that the PageRank score assignment is more robust than HITS in the sense that scores are less sensitive to small changes in graph topology. However, it has also been noted that the teleport operation contributes significantly to PageRank’s robustness in this sense. Both PageRank and HITS can be “spammed” by the orchestrated insertion of links into
LINK FARMS the web graph; indeed, the Web is known to have such link farms that collude to increase the score assigned to certain pages by various link analysis algorithms.
The HITS algorithm is due to Kleinberg (1999). Chakrabarti et al. (1998) developed variants that weighted links in the iterative computation based on the presence of query terms in the pages being linked and compared these to results from several web search engines. Bharat and Henzinger (1998) further developed these and other heuristics, showing that certain combinations outperformed the basic HITS algorithm. Borodin et al. (2001) provides a systematic study of several variants of the HITS algorithm. Ng et al. (2001b) introduces a notion of stability for link analysis, arguing that small changes to link topology should not lead to significant changes in the ranked list of results for a query. Numerous other variants of HITS have been developed by a number of authors, the best know of which is perhaps SALSA (Lempel and Moran 2000).
Online edition (c) 2009 Cambridge UP
Online edition (c) 2009 Cambridge UP