

- •List of Tables
- •List of Figures
- •Table of Notation
- •Preface
- •Boolean retrieval
- •An example information retrieval problem
- •Processing Boolean queries
- •The extended Boolean model versus ranked retrieval
- •References and further reading
- •The term vocabulary and postings lists
- •Document delineation and character sequence decoding
- •Obtaining the character sequence in a document
- •Choosing a document unit
- •Determining the vocabulary of terms
- •Tokenization
- •Dropping common terms: stop words
- •Normalization (equivalence classing of terms)
- •Stemming and lemmatization
- •Faster postings list intersection via skip pointers
- •Positional postings and phrase queries
- •Biword indexes
- •Positional indexes
- •Combination schemes
- •References and further reading
- •Dictionaries and tolerant retrieval
- •Search structures for dictionaries
- •Wildcard queries
- •General wildcard queries
- •Spelling correction
- •Implementing spelling correction
- •Forms of spelling correction
- •Edit distance
- •Context sensitive spelling correction
- •Phonetic correction
- •References and further reading
- •Index construction
- •Hardware basics
- •Blocked sort-based indexing
- •Single-pass in-memory indexing
- •Distributed indexing
- •Dynamic indexing
- •Other types of indexes
- •References and further reading
- •Index compression
- •Statistical properties of terms in information retrieval
- •Dictionary compression
- •Dictionary as a string
- •Blocked storage
- •Variable byte codes
- •References and further reading
- •Scoring, term weighting and the vector space model
- •Parametric and zone indexes
- •Weighted zone scoring
- •Learning weights
- •The optimal weight g
- •Term frequency and weighting
- •Inverse document frequency
- •The vector space model for scoring
- •Dot products
- •Queries as vectors
- •Computing vector scores
- •Sublinear tf scaling
- •Maximum tf normalization
- •Document and query weighting schemes
- •Pivoted normalized document length
- •References and further reading
- •Computing scores in a complete search system
- •Index elimination
- •Champion lists
- •Static quality scores and ordering
- •Impact ordering
- •Cluster pruning
- •Components of an information retrieval system
- •Tiered indexes
- •Designing parsing and scoring functions
- •Putting it all together
- •Vector space scoring and query operator interaction
- •References and further reading
- •Evaluation in information retrieval
- •Information retrieval system evaluation
- •Standard test collections
- •Evaluation of unranked retrieval sets
- •Evaluation of ranked retrieval results
- •Assessing relevance
- •A broader perspective: System quality and user utility
- •System issues
- •User utility
- •Results snippets
- •References and further reading
- •Relevance feedback and query expansion
- •Relevance feedback and pseudo relevance feedback
- •The Rocchio algorithm for relevance feedback
- •Probabilistic relevance feedback
- •When does relevance feedback work?
- •Relevance feedback on the web
- •Evaluation of relevance feedback strategies
- •Pseudo relevance feedback
- •Indirect relevance feedback
- •Summary
- •Global methods for query reformulation
- •Vocabulary tools for query reformulation
- •Query expansion
- •Automatic thesaurus generation
- •References and further reading
- •XML retrieval
- •Basic XML concepts
- •Challenges in XML retrieval
- •A vector space model for XML retrieval
- •Evaluation of XML retrieval
- •References and further reading
- •Exercises
- •Probabilistic information retrieval
- •Review of basic probability theory
- •The Probability Ranking Principle
- •The 1/0 loss case
- •The PRP with retrieval costs
- •The Binary Independence Model
- •Deriving a ranking function for query terms
- •Probability estimates in theory
- •Probability estimates in practice
- •Probabilistic approaches to relevance feedback
- •An appraisal and some extensions
- •An appraisal of probabilistic models
- •Bayesian network approaches to IR
- •References and further reading
- •Language models for information retrieval
- •Language models
- •Finite automata and language models
- •Types of language models
- •Multinomial distributions over words
- •The query likelihood model
- •Using query likelihood language models in IR
- •Estimating the query generation probability
- •Language modeling versus other approaches in IR
- •Extended language modeling approaches
- •References and further reading
- •Relation to multinomial unigram language model
- •The Bernoulli model
- •Properties of Naive Bayes
- •A variant of the multinomial model
- •Feature selection
- •Mutual information
- •Comparison of feature selection methods
- •References and further reading
- •Document representations and measures of relatedness in vector spaces
- •k nearest neighbor
- •Time complexity and optimality of kNN
- •The bias-variance tradeoff
- •References and further reading
- •Exercises
- •Support vector machines and machine learning on documents
- •Support vector machines: The linearly separable case
- •Extensions to the SVM model
- •Multiclass SVMs
- •Nonlinear SVMs
- •Experimental results
- •Machine learning methods in ad hoc information retrieval
- •Result ranking by machine learning
- •References and further reading
- •Flat clustering
- •Clustering in information retrieval
- •Problem statement
- •Evaluation of clustering
- •Cluster cardinality in K-means
- •Model-based clustering
- •References and further reading
- •Exercises
- •Hierarchical clustering
- •Hierarchical agglomerative clustering
- •Time complexity of HAC
- •Group-average agglomerative clustering
- •Centroid clustering
- •Optimality of HAC
- •Divisive clustering
- •Cluster labeling
- •Implementation notes
- •References and further reading
- •Exercises
- •Matrix decompositions and latent semantic indexing
- •Linear algebra review
- •Matrix decompositions
- •Term-document matrices and singular value decompositions
- •Low-rank approximations
- •Latent semantic indexing
- •References and further reading
- •Web search basics
- •Background and history
- •Web characteristics
- •The web graph
- •Spam
- •Advertising as the economic model
- •The search user experience
- •User query needs
- •Index size and estimation
- •Near-duplicates and shingling
- •References and further reading
- •Web crawling and indexes
- •Overview
- •Crawling
- •Crawler architecture
- •DNS resolution
- •The URL frontier
- •Distributing indexes
- •Connectivity servers
- •References and further reading
- •Link analysis
- •The Web as a graph
- •Anchor text and the web graph
- •PageRank
- •Markov chains
- •The PageRank computation
- •Hubs and Authorities
- •Choosing the subset of the Web
- •References and further reading
- •Bibliography
- •Author Index
20.2 Crawling |
449 |
|
Doc |
|
|
|
|
|
|
URL |
|
FP’s |
|
|
|
|
|
|
set |
-DNS |
|
|
|
|
To |
|
|
|
6 |
|
|
|
|
other |
|
|
|
? |
|
|
|
|
nodes |
|
|
|
|
6 |
|
|
|
|
666 |
|
6 |
|
? |
- |
|
|
- |
|
- |
? |
- |
URL |
|
Host |
Dup |
||||
www |
Content |
|
|
|
- |
|||
Parse |
Seen? |
|
Filter |
|
splitter |
- URL |
||
- - |
|
|
- |
Elim |
||||
Fetch |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
From |
||
6 |
|
|
|
|
|
other |
||
|
|
|
|
|
nodes |
|||
|
URL Frontier |
|
|
|
|
|
||
|
|
|
|
|
|
|
||
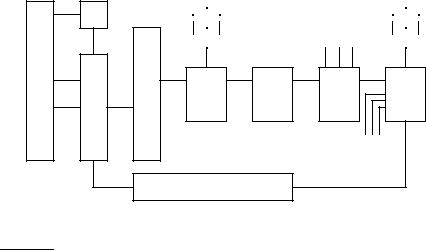
Figure 20.2 Distributing the basic crawl architecture.
gerprint/shingle (say by taking the fingerprint modulo the number of nodes). The result of this locality-mismatch is that most “Content Seen?” tests result in a remote procedure call (although it is possible to batch lookup requests).
2.There is very little locality in the stream of document fingerprints/shingles. Thus, caching popular fingerprints does not help (since there are no popular fingerprints).
3.Documents change over time and so, in the context of continuous crawling, we must be able to delete their outdated fingerprints/shingles from the content-seen set(s). In order to do so, it is necessary to save the fingerprint/shingle of the document in the URL frontier, along with the URL itself.
20.2.2DNS resolution
Each web server (and indeed any host connected to the internet) has a unique
IP ADDRESS IP address: a sequence of four bytes generally represented as four integers separated by dots; for instance 207.142.131.248 is the numerical IP address associated with the host www.wikipedia.org. Given a URL such as www.wikipedia.org in textual form, translating it to an IP address (in this case, 207.142.131.248) is
Online edition (c) 2009 Cambridge UP
450 |
20 Web crawling and indexes |
DNS RESOLUTION a process known as DNS resolution or DNS lookup; here DNS stands for Domain Name Service. During DNS resolution, the program that wishes to perform this translation (in our case, a component of the web crawler) contacts a
DNS SERVER DNS server that returns the translated IP address. (In practice the entire translation may not occur at a single DNS server; rather, the DNS server contacted initially may recursively call upon other DNS servers to complete the translation.) For a more complex URL such as en.wikipedia.org/wiki/Domain_Name_System, the crawler component responsible for DNS resolution extracts the host name
– in this case en.wikipedia.org – and looks up the IP address for the host en.wikipedia.org.
DNS resolution is a well-known bottleneck in web crawling. Due to the distributed nature of the Domain Name Service, DNS resolution may entail multiple requests and round-trips across the internet, requiring seconds and sometimes even longer. Right away, this puts in jeopardy our goal of fetching several hundred documents a second. A standard remedy is to introduce caching: URLs for which we have recently performed DNS lookups are likely to be found in the DNS cache, avoiding the need to go to the DNS servers on the internet. However, obeying politeness constraints (see Section 20.2.3) limits the of cache hit rate.
There is another important difficulty in DNS resolution; the lookup implementations in standard libraries (likely to be used by anyone developing a crawler) are generally synchronous. This means that once a request is made to the Domain Name Service, other crawler threads at that node are blocked until the first request is completed. To circumvent this, most web crawlers implement their own DNS resolver as a component of the crawler. Thread i executing the resolver code sends a message to the DNS server and then performs a timed wait: it resumes either when being signaled by another thread or when a set time quantum expires. A single, separate DNS thread listens on the standard DNS port (port 53) for incoming response packets from the name service. Upon receiving a response, it signals the appropriate crawler thread (in this case, i) and hands it the response packet if i has not yet resumed because its time quantum has expired. A crawler thread that resumes because its wait time quantum has expired retries for a fixed number of attempts, sending out a new message to the DNS server and performing a timed wait each time; the designers of Mercator recommend of the order of five attempts. The time quantum of the wait increases exponentially with each of these attempts; Mercator started with one second and ended with roughly 90 seconds, in consideration of the fact that there are host names that take tens of seconds to resolve.
Online edition (c) 2009 Cambridge UP

20.2 Crawling |
451 |
20.2.3The URL frontier
The URL frontier at a node is given a URL by its crawl process (or by the host splitter of another crawl process). It maintains the URLs in the frontier and regurgitates them in some order whenever a crawler thread seeks a URL. Two important considerations govern the order in which URLs are returned by the frontier. First, high-quality pages that change frequently should be prioritized for frequent crawling. Thus, the priority of a page should be a function of both its change rate and its quality (using some reasonable quality estimate). The combination is necessary because a large number of spam pages change completely on every fetch.
The second consideration is politeness: we must avoid repeated fetch requests to a host within a short time span. The likelihood of this is exacerbated because of a form of locality of reference: many URLs link to other URLs at the same host. As a result, a URL frontier implemented as a simple priority queue might result in a burst of fetch requests to a host. This might occur even if we were to constrain the crawler so that at most one thread could fetch from any single host at any time. A common heuristic is to insert a gap between successive fetch requests to a host that is an order of magnitude larger than the time taken for the most recent fetch from that host.
Figure 20.3 shows a polite and prioritizing implementation of a URL frontier. Its goals are to ensure that (i) only one connection is open at a time to any host; (ii) a waiting time of a few seconds occurs between successive requests to a host and (iii) high-priority pages are crawled preferentially.
The two major sub-modules are a set of F front queues in the upper portion of the figure, and a set of B back queues in the lower part; all of these are FIFO queues. The front queues implement the prioritization, while the back queues implement politeness. In the flow of a URL added to the frontier as it makes its way through the front and back queues, a prioritizer first assigns to the URL an integer priority i between 1 and F based on its fetch history (taking into account the rate at which the web page at this URL has changed between previous crawls). For instance, a document that has exhibited frequent change would be assigned a higher priority. Other heuristics could be application-dependent and explicit – for instance, URLs from news services may always be assigned the highest priority. Now that it has been assigned priority i, the URL is now appended to the ith of the front queues.
Each of the B back queues maintains the following invariants: (i) it is non-
empty while the crawl is in progress and (ii) it only contains URLs from a single host1. An auxiliary table T (Figure 20.4) is used to maintain the mapping from hosts to back queues. Whenever a back-queue is empty and is being re-filled from a front-queue, table T must be updated accordingly.
1. The number of hosts is assumed to far exceed B.
Online edition (c) 2009 Cambridge UP
452 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 Web crawling and indexes |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Prioritizer |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PP |
|
P |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
P |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PP |
PPP |
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
1) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
PPqF |
|||||||||||||||||||
|
|
2) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
F front queues |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
r |
|
|
|
r |
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
HH |
|
|
|
HH |
HH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
HH |
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
H |
|
|
HH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
HH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
HH |
HH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
HjH |
HjH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Biased front queue selector |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Back queue router |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
XXX |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
XXXX |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
XXX |
|
|
|
|
|
|
|
|||||||||||||||||||||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
XX |
|
|
|
|
B |
||||||||||||||
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
XzX |
||||||||||||||
|
9 |
|
|
|
9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B back queues |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Single host on each |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
r |
|
|
|
|
|
r |
|
|
|
r |
|
|
|
r |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
XXXXXXXX |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
XXXXXXXX |
|
|
|
|
|
|
9 |
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
XXXXzXXXXz |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Back queue |
|
|
|
|
|
|
|
|
|
|
|
|
|
@ |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
selector |
|
|
|
|
|
|
|
|
|
|
|
|
Heap@ |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
@ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
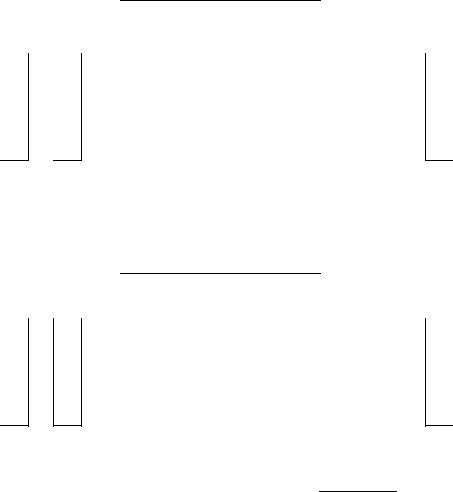
Figure 20.3 The URL frontier. URLs extracted from already crawled pages flow in |
|
|||||||||||||||||||||||||||||||||||||||||
at the top of the figure. A crawl thread requesting a URL extracts it from the bottom of |
|
|||||||||||||||||||||||||||||||||||||||||
the figure. En route, a URL flows through one of several front queues that manage its |
|
|||||||||||||||||||||||||||||||||||||||||
priority for crawling, followed by one of several back queues that manage the crawler’s |
|
|||||||||||||||||||||||||||||||||||||||||
politeness. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Online edition (c) 2009 Cambridge UP

20.2 Crawling |
453 |
||
|
|
|
|
|
Host |
Back queue |
|
|
|
|
|
|
stanford.edu |
23 |
|
|
microsoft.com |
47 |
|
|
acm.org |
12 |
|
Figure 20.4 Example of an auxiliary hosts-to-back queues table.
In addition, we maintain a heap with one entry for each back queue, the entry being the earliest time te at which the host corresponding to that queue can be contacted again.
A crawler thread requesting a URL from the frontier extracts the root of this heap and (if necessary) waits until the corresponding time entry te. It then takes the URL u at the head of the back queue j corresponding to the extracted heap root, and proceeds to fetch the URL u. After fetching u, the calling thread checks whether j is empty. If so, it picks a front queue and extracts from its head a URL v. The choice of front queue is biased (usually by a random process) towards queues of higher priority, ensuring that URLs of high priority flow more quickly into the back queues. We examine v to check whether there is already a back queue holding URLs from its host. If so, v is added to that queue and we reach back to the front queues to find another candidate URL for insertion into the now-empty queue j. This process continues until j is non-empty again. In any case, the thread inserts a heap entry for j with a new earliest time te based on the properties of the URL in j that was last fetched (such as when its host was last contacted as well as the time taken for the last fetch), then continues with its processing. For instance, the new entry te could be the current time plus ten times the last fetch time.
The number of front queues, together with the policy of assigning priorities and picking queues, determines the priority properties we wish to build into the system. The number of back queues governs the extent to which we can keep all crawl threads busy while respecting politeness. The designers of Mercator recommend a rough rule of three times as many back queues as
crawler threads.
On a Web-scale crawl, the URL frontier may grow to the point where it demands more memory at a node than is available. The solution is to let most of the URL frontier reside on disk. A portion of each queue is kept in memory, with more brought in from disk as it is drained in memory.
?Exercise 20.1
Why is it better to partition hosts (rather than individual URLs) between the nodes of a distributed crawl system?
Exercise 20.2
Why should the host splitter precede the Duplicate URL Eliminator?
Online edition (c) 2009 Cambridge UP