

§ 6.10. Итеративные коды
Для итеративных кодов характерно, что операции кодирования проводятся над совокупностью информационных символов, располагаемых по нескольким, например q, координатам. В связи с этим итеративные коды также называют многомерными, многостепенными. Число информационных символов в кодовом векторе q-степенного кода

где mγ — число информационных символов по координате γ. Последовательности информационных символов по каждой из координат кодируются каким-либо линейным кодом. В общем случае каждый информационный символ входит одновременно в q различных кодовых векторов.
Классические итеративные коды.Идея создания рассматриваемых кодов принадлежит П. Элайесу.
В этом случае определенным линейным кодом кодируется каждая из отдельных последовательностей информационных символов по координате γ, (например, каждая строка). Получаемый итеративный код также является линейным.
П ростейший
из таких кодов является двухстепенной
(двумерный) код с проверкой на четность
по строкам и столбцам, который широко
используется на практике для обнаружения
ошибок на магнитной ленте. Расположение
информационных и проверочных символов
приведено на рис. 6.25.
ростейший
из таких кодов является двухстепенной
(двумерный) код с проверкой на четность
по строкам и столбцам, который широко
используется на практике для обнаружения
ошибок на магнитной ленте. Расположение
информационных и проверочных символов
приведено на рис. 6.25.
Значения проверочных символов, располагающихся в крайнем правом (или в любом другом) столбце и нижней строке, определяются уравнениями

Передачу символов такого кода обычно осуществляют последовательно символ за символом, от одной строки к другой, либо параллельно целыми строками. Декодирование начинают сразу, не ожидая поступления всего блока информации.
Проверка справедливости соотношения (6.55) при декодировании позволяет исправить любое нечетное число искаженных символов, расположенных в одной строке или в одном столбце. Действительно, строка (столбец) с нечетным числом искаженных символов будет выявлена неудовлетворительным результатом проверки ее на четность, а искаженные символы конкретно будут указаны при проверках по столбцам (строкам). Большинство ошибок другой конфигурации этим кодом может быть обнаружено. Необнаруженными оказываются только ошибки, имеющие четное число искаженных символов, как по строкам, так и по столбцам. Простейшая не обнаруживаемая ошибка содержит четыре искаженных символа, расположенных в вершинах прямоугольника (рис. 6.26).
Число ошибок такого вида в4 для блока изlхn символов равно
![]()
Общее число четырехкратных ошибок составляет
![]()
Таким образом, отношение числа не обнаруживаемых четырехкратных ошибок к общему числу таких ошибок
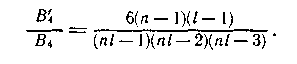
Определим минимальный вес ненулевого вектора рассматриваемого итеративного кода (двумерной кодовой комбинации). Такой вектор должен содержать только одну ненулевую вектор-строку, минимальный вес, которой равен 2. Проверка на четность каждого из ненулевых столбцов также дает вектор веса 2. Следовательно, минимальный вес ненулевого вектора итеративного кода с двойной проверкой на четность равен 2*2 = 4.
Аналогично можно показать, что в общем случае минимальный вес вектора итеративного кода равен произведению минимальных весов векторов итерируемых кодов. Так как минимальное кодовое расстояние для линейного кода равно минимальному весу его ненулевых векторов, то минимальное расстояние итеративного кода равно
![]()
где dγ — кодовое расстояние линейного кода по координате γ.
Коррекция ошибок проводится последовательно. Сначала исправляют ошибки по одной координате, затем осуществляют исправление оставшихся ошибок по другой координате и т. д.
Такая процедура проста, но снижает корректирующую способность итеративного кода, поскольку оказывается невозможным исправить часть ошибок кратности (d-l)/2.
Поясним это на примере итерации двух кодов Хэмминга (7, 4). Результирующий итеративный код (49, 16) имеет минимальное кодовое расстояние, равное 3x3 = =9, и, следовательно, потенциально, как любой линейный код, способен исправлять все ошибки кратности 4 и менее. Однако, применяя указанную выше процедуру декодирования, невозможно исправить четырехкратные ошибки с расположением искаженных символов в вершинах прямоугольника (рис. 6.26).
Специальные двухстепенные коды. Специальные двухстепенные коды нашли широкое применение для обнаружения и исправления ошибок, возникающих при записи, хранении и считывании цифровой информации с накопителей на магнитном носителе, например на магнитной ленте. Разработанные коды базируются на исследованиях статистики ошибок. Опубликованные данные показывают, что при эксплуатации магнитных носителей преобладают пачки ошибок вдоль дорожек (столбцов), причем вероятность возникновения двух пачек ошибок и более на разных дорожках в кадре информации из нескольких десятков строк достаточно мала.
Рассмотрим один из таких кодов [4].
Стандартный
код для записи информации на магнитную
ленту. В
каждом кадре информации формируется
одна дополнительная строка. Проверочные
символы на дополнительной дорожке
определяются из условия обеспечения
нечетности числа единиц вдоль данной
строки. В направлении дорожек используется
параллельный циклический код, позволяющий
определить номер дорожки, на которой
возникла пачка ошибок. Зная номер дорожки
с искаженными символами и используя
результаты проверок по с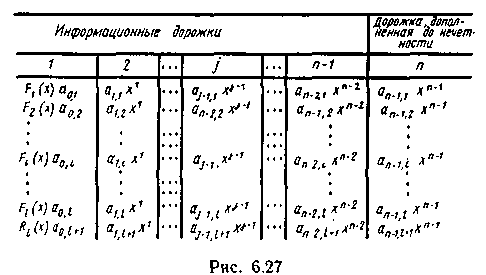 трокам,
можно произвести их исправление.
трокам,
можно произвести их исправление.
Расположение кодируемого кадра информации на ленте показано на рис. 6.27.
Кодирование циклическим кодом осуществляется следующим образом. Многочлен F1(x), соответствующий информации перкой строки, умножается на x и результат приводится по модулю образующего многочлена g(x) степени n, где n — число дорожек, включая контрольную [например, для 9 дорожек g(x) = (х + 1)(х8 + + х4 + х3 + x2 + 1)]. Полученный остаток Ri(x) суммируется по модулю два с многочленом F2(x), соответствующим информации второй строки. Сумма снова умножается на x и далее приводится по модулю g(x), в результате чего определяется остаток R2(x). Применив этот алгоритм последовательно ко всем строкам кодируемого кадра информации, получим R1(x) — многочлен степени не выше n-1, который и записывается в конце кадра (при нечетном числе строк в нем), в качестве символов контроля по дорожкам
![]()
где Ri(x) mod (x) означает величину Ri(x), приведенную по модулю g(x).
Декодирование производится аналогично кодированию, причем участвует и контрольная строка — Ri(x). Процесс декодирования можно записать следующим образом:

где Ε (x) — некоторый многочлен, определяющий ошибку. Выражение M(х) можно представить в виде
![]()
Сравнивая его с выражением (6.58), можно заключить, что при отсутствии ошибки будет фиксироваться значение R'(x), равное нулю. Случай R'(x) неравна 0 соответствует обнаружению ошибки. Если имела место пачка ошибок вдоль одной из дорожек, то она может быть исправлена. Многочлен ошибки в этом случае имеет вид Ε (x) = xje(х), где е(х) отражает поразрядную структуру, а хj — адрес ошибки. Так как справедливо равенство (6.59), то
![]()
причем е(х) определяется по результатам проверок строк на нечетность.
Номер дорожки с искаженными символами может быть найден теперь, исходя из следующих соображений. Предположив, что на ленте была записана информация, состоящая из одних нулей, т. е. F1(x) = 0...Fl(x) = 0, Rl(x) = 0 и при считывании на дорожке с выбранным известным номером n возникла пачка ошибок с точно такой же структурой е(х), в результате декодирования получим некоторый многочлен R"(x), причем
![]()
где k — число дорожек, на которое отстоит дорожка с известным номером η от дорожки, где возникла пачка ошибок.
Таким образом, если пачка ошибок возникла только по одной дорожке, то, умножив R'(x) на xk с приведением по модулю g(x), получим R"(x). Поэтому при декодировании одновременно с вычислением R'(x) осуществляется вычисление R"(x). Для определения номера дорожки с искаженными символами производится последовательное домножение R'(x) на х, х2, ..., хn-1.
На каждом шаге, начиная с R'(x), результат приводится по модулю g(x) и затем сравнивается с R"(x). Процесс прекращается, как только на каком-либо i-м шаге зафиксировано равенство (в этом случае k = i— 1 и известная величина n определяет номер искомой дорожки) или после проведения n сравнений. В последнем случае фиксируется наличие неисправимой ошибки.
При четном числе строк кодируемой информации l образующий многочлен типа g(x) = (х + 1 )g'(x) обеспечивает Rl(x) всегда с четным числом членов. Суммирование этого многочлена с g'(x) позволяет получить результирующий многочлен R'l(x), удовлетворяющий проверке по нечетности вдоль строки.
Описанные коды способны исправлять все пачки ошибок, возникающие по одной дорожке, за исключением пачек вила
![]()
где L(x) — произвольный многочлен.
Кодирование и декодирование информации с использованием рассматриваемых кодов относительно просто реализуется как программными, так и аппаратными средствами [4].