

Основные этапы статистического исследования
Процесс статистического исследования состоит из шести этапов (Малхотра).
Этап 1. Определение проблемы Первый этап любого статистического исследования заключается в выяснении проблемы. При ее определении исследователь должен принимать во внимание цель исследования, соответствующую исходную информацию, какая информация необходима и как она будет использована при принятии решения. Определение проблемы включает в себя ее обсуждение с лицами, принимающими решения (топ-менеджерами), интервью с экспертами в данной сфере бизнеса, анализ вторичных данных и. возможно, проведение отдельных качественных исследований, например фокус-групп. Как только проблема точно установлена, можно разрабатывать план статистического исследования и приступать к его проведению.
Этап 2. Разработка подхода к решению проблемы Разработка подхода к решению проблемы включает в себя формулировку теоретических рамок исследования, аналитических моделей, поисковых вопросов, гипотез, а также определение факторов, которые могут влиять на план исследования. Этот этап характеризуется следующими действиями: обсуждение с руководством компании-клиента и экспертами по данной сфере, изучение ситуаций и моделирование, анализ вторичных данных. качественные исследования и прагматические соображения.
Этап 3. Разработка плана исследования План статистического исследования детализирует ход выполнения процедур, необходимых для получения нужной информации. Он необходим для того, чтобы разработать план проверки гипотез, определить возможные ответы на поисковые вопросы и выяснить, какая информация необходима для принятия решения. Проведение поискового исследования, точное определение переменных и определение соответствующих шкал для их измерения — все это тоже входит в план статистического исследования. Необходимо определить. каким образом должны быть получены данные от респондентов (например, проведение опроса или эксперимента). Одновременно необходимо составить анкету и план выборочного наблюдения. Более строго разработка плана статистического исследования состоит из следующих этапов.
Анализ вторичной информации.
Качественные исследования.
Сбор количественных данных (опрос, наблюдение и проведение экспериментов).
Измерение и методы шкалирования.
Разработка анкеты.
Определение размера выборки и проведение выборочного наблюдения.
План анализа данных.
Этап 4. Полевые работы или сбор данных Сбор данных осуществляется персоналом по проведению полевых работ, которые работают либо в полевых условиях, как в случае личного интервьюирования (в домах по местожительства. в местах покупок или с помощью компьютера), либо нз офиса с помощью телефона (телефонное или компьютерное интервьюирование), либо по почте (традиционная почта и почтовые панельные исследования с предварительно выбранными семьями), либо с помощью электронных средств (электронная почта или Ьнете^. Надлежащий отбор, обучение, контроль н опенка сотрудников, принимающих участие в полевых работах, минимизирует ошибки при сборе данных.
Этап 5. Подготовка данных и их анализ Подготовка данных включает в себя редактирование, кодирование, расшифровку и проверку данных. Каждая анкета или форма наблюдения проверяются или редактируются н. если необходимо, корректируются. Каждому ответу на вопрос анкеты присваиваются числовые или буквенные коды. Данные анкет расшифровываются или набиваются на магнитной
ленте или на диске нлн вводятся непосредственно в компьютер. Проверка дает возможность удостовериться, что данные с оригиналов анкет расшифрованы точно. Для анализа данных используются одномерные методы статистического анализа в том случае, если элементы выборки измеряются по одному показателю, нлн когда имеется несколько показателей, но каждая переменная анализируется отдельно. С другой стороны, если имеется два или более измерений каждого элемента выборки, а переменные анализируются одновременно, то для анализа данных используются многомерные методы.
Этап б. Подготовка отчета и его презентация Ход н результаты статистических исследований должны быть изложены письменно в виде отчета, в котором четко обозначены конкретные вопросы исследования, описан метод и план исследования, процедуры сбора данных и их анализа, результаты и выводы. Полученные выводы должны быть представлены в виде, удобном для использования при принятии управленческих решений. Кроме того, руководству компании-клиента должна быть сделана и устная презентация с использованием таблиц, цифр и диаграмм, чтобы повысить доходчивость и воздействие на аудиторию.
6.SPSS
SPSS «Statistical Package for the Social Sciences» является самой распространённой программой для обработки статистической информации. В настоящем разделе описан путь этой программы к такому выдающемуся успеху. Затем приведен обзор отдельных модулей программы.
В отличие от Экселя не имеет столбиков и строк. Первая страница:
- данные
- признаки
Редактор данных это приложение, напоминающее электронную таблицу. Под электронной таблицей подразумевается рабочий лист, разделенный на строки и столбцы, который позволяет про сто и эффективно вводить данные. Отдельные строки таблицы соответствуют отдельным наблюдениям. Например, при обработке данных опроса одна строка содержит данные одного респондента. Отдельные столбцы соответствуют отдельным переменным. При обработке данных наблюдений анкеты в одной переменной хранятся ответы на отдельный вопрос. Отдельные ячейки таблицы содержат значения переменных для каждого отдельного наблюдения; в каждой ячейке хранится одно значение переменной.
3.4.1 Определение переменных Начнем с определения переменных. Переменную можно определить следующим образом:
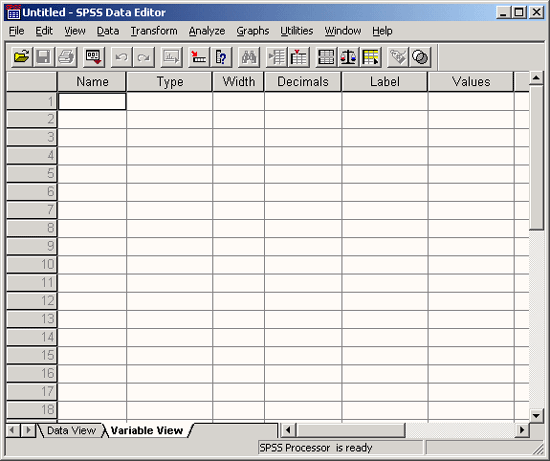
В редакторе данных дважды щелкните на ячейке с надписью var или щелкните на ярлычке Variable view (Просмотр переменных) на нижнем краю таблицы.
В обоих случаях вы перейдете в режим просмотра переменных, который обеспечивает редактор данных (см. рис. 3.2). Здесь мы можем последовательно, строка за строкой определить необходимые переменные.
Имя переменной Чтобы задать имя переменной, поступите следующим образом:
Введите в текстовом поле Name (Имя) выбранное имя переменной. В нашем примере мы сначала определим переменную fragebnr. Для этого введите в поле Name текст "fragebnr".
При выборе имени переменной следует соблюдать определенные правила:
 Имена
переменных могут содержать буквы
латинского алфавита и цифры. Кроме
того, допускаются специальные символы
_ (подчеркивание), . (точка), а также
символы @ и #. Не разрешаются, например,
пробелы, знаки других алфавитов и
специальные символы, такие как !, ?,"
и *.
Имена
переменных могут содержать буквы
латинского алфавита и цифры. Кроме
того, допускаются специальные символы
_ (подчеркивание), . (точка), а также
символы @ и #. Не разрешаются, например,
пробелы, знаки других алфавитов и
специальные символы, такие как !, ?,"
и *.
Имя переменной должно начинаться с буквы.
Последний символ имени не может быть точкой или знаком подчеркивания (_).
Длина имени переменной не должна превышать восьми символов.
Рис. 3.2: Редактор данных: просмотр переменных
Имена переменных нечувствительны к регистру, то есть прописные и строчные буквы не различаются.
Примеры допустимых имен переменных:
budget99
gender
zarplata
quest_13
var3_1_2
Примеры недопустимых имен переменных:
1nа1 |
Имя начинается не с буквы |
Assignment |
Имя длиннее 8 символов |
Прибыль |
Имя содержит символы другого алфавита |
State 94 |
Имя содержит пробел |
None! |
Символ "!" не разрешается |
Нажмите на клавишу <Таb>, чтобы подтвердить ввод и перейти к установке типа переменной.
Тип переменной
К ак
видно из электронной таблицы, вновь
созданные в SPSS переменные по умолчанию
являются численными с максимальной
длиной восемь знаков, причем дробная
часть состоит из двух знаков (формат
F8.2).
ак
видно из электронной таблицы, вновь
созданные в SPSS переменные по умолчанию
являются численными с максимальной
длиной восемь знаков, причем дробная
часть состоит из двух знаков (формат
F8.2).
• Если требуется
изменить тип переменной, щелкните в
ячейке на кнопке с тремя точками:
![]()
Откроется диалоговое окно Define Variable Type (Определение типа переменной). Рис. 3.3: Диалоговое окно Define Variable Type (для численной переменной)
В SPSS существуют следующие типы переменных:
Numeric (Численный) |
К допустимым значениям относятся цифры, перед которыми стоит знак плюс или минус и десятичный разделитель. Знак плюс перед числом, в отличие от минуса, не отображается. В текстовом поле Length (Длина) задается максимальное количество знаков, включая позицию для десятичного разделителя. В текстовом поле Decimals (Десятичные разряды) вводится количество отображаемых знаков дробной части. |
Comma (Запятая) |
К допустимым значениям относятся цифры, перед которыми стоит знак плюс или минус, точка, как десятичный разделитель и одна или несколько запятых в качестве разделителей групп разрядов. Если запятые опускаются при вводе, они вставляются автоматически. Длина такой переменной равна максимальному количеству знаков, включая десятичный разделитель и запятые между группами разрядов. |
Dot (Точка) |
К допустимым значениям относятся цифры, перед которыми стоит знак плюс или минус, запятая, как десятичный разделитель и одна или несколько точек в качестве разделителей групп разрядов. Если точки опускаются при вводе, они вставляются автоматически. |
Scientific notation (Экспоненциальное представление) |
При вводе данных разрешаются все допустимые численные значения, включая экспоненциальное представление, о котором свидетельствует содержащаяся в числе буква Е или D, а также знак плюс или минус. |
Date (Дата) |
Допустимые значения — дата и/или время. |
Dollar (Доллар) |
К допустимым значениям относятся: знак доллара, точка, как десятичный разделитель и запятые, как разделители групп разрядов. Если знак доллара или запятые опускаются при вводе, они вставляются автоматически. |
Special currency (Специальная валюта) |
Пользователь может задавать собственные форматы валюты. В поле Length в этом случае задается максимальное количество знаков, включая все знаки, заданные пользователем. Обозначение валюты при вводе не указывается; оно вставляется автоматически. |
String (Строка) |
Строка символов. К допустимым значениям относятся: буквы, цифры и специальные символы. Различаются короткие и длинные строковые переменные. Короткие строковые переменные могут содержать не более восьми знаков. В большинстве процедур SPSS применение длинных строковых переменных ограничивается или вообще не допускается. |
При вводе и выводе данных надо учитывать следующие особенности:
Численные форматы: В численных форматах десятичным разделителем может быть либо точка, либо запятая. Тип десятичного разделителя зависит от настроек диалогового окна Язык и стандарты (Regional Settings) на панели управления Windows. Точное значение переменной хранится внутри программы, а Редактор данных отображает на экране лишь заданное число десятичных разрядов. Значения, которые имеют больше десятичных разрядов, округляются. Для вычислений применяется точное значение.
Строковые форматы: В длинных строковых переменных значения дополняются пробелами до максимальной длины. Например, в строковой переменной длины 10 значение "SPSS" хранится внутри программы как "SPSS
Форматы даты и времени: В форматах даты в качестве разделителей между значениями дня, месяца и числа могут применяться косая черта, дефис, пробел, запятая или точка. Можно выбрать один из нескольких форматов даты (dd-mm-yyyy, dd-mmm-yy, mm/dd/yyyy и т.д.). Дата в формате dd-mmm-yy отображается с разделителем-дефисом и сокращением названия месяца из трех букв. Дата в форматах dd/mm/yy и mm/dd/yy отображается с разделителем-косой чертой и номером месяца вместо названия.
Всего доступно 27 различных форматов даты и времени, которые отображаются в разворачивающемся списке. В форматах времени в качестве разделителей между значениями часов, минут и секунд могут использоваться двоеточие, точка или пробел.
Специальная валюта: Форматы отображения валюты ССА, ССВ, ССС, CCD и ССЕ задаются с помощью вкладки Currency (Валюта), которая открывается командой меню Edit (Правка) Options... (Параметры...)
Установите для переменной fragebnr тип String и длину пять символов и щелкните на кнопке ОК.
Р ис.
3.4: Диалоговое
окно Define Variable Type (для строковой переменной).
ис.
3.4: Диалоговое
окно Define Variable Type (для строковой переменной).
Переменная fragebnr получила строковый тип. С такими переменными нельзя выполнять никаких вычислительных операций, но можно проводить, например, подсчеты повторяемости. Кроме того, становится возможным ввод букв, например, "W" для старых федеральных земель и "О" — для новых. Мы выбрали длину пять символов, чтобы можно было кодировать до 999 анкет для обеих групп земель. В этом случае для анкет в старых федеральных землях можно будет задавать номера анкет от "W-001" до "W-999", а для новых федеральных земель — от "О-001" до "О-999".
Нажмите клавишу <ТаЬ>, чтобы перейти к установке формата столбца.
Формат столбца (Width)
Для переменной fragebnr задано число позиций в столбце, равное "5". Это значение следует из длины переменной, указанной в диалоге Define Variable Type.
Чтобы изменить этот формат представления переменной, перенесенный из диалога Define Variable Type, щелкните на кнопке лифта:

В этом случае выбранное значение ширины подтверждается клавишей <Таb>.
Десятичные разряды (Decimals)
Так как переменная fragebnr является строковой, для нее задано количество десятичных разрядов "0". Увеличение или уменьшение этого значения, определенного настройкой в диалоге Define Variable Type, также производится при помощи кнопки лифта: Подтвердите значение "0", нажав клавишу <Таb>.
Метка переменной (Label)
Метка переменной — это название, позволяющая описать переменную более подробно. Метка переменной может содержать до 256 символов. В метках переменных различаются прописные и строчные буквы. Они отображаются в том виде, в каком были введены. Для переменной fragebnr введите в качестве метки в поле Variable label текст "Номер анкеты".
Метки значений (Values)
Метки значений — это название, позволяющее более подробно описать возможные значения переменной. Так, например, в случае переменной sex можно задать метку "женский" для значения "1" и метку "мужской" для значения "2". Подтвердите настройку по умолчанию None (Нет) клавишей <Таb>. Впрочем, ввод данных также можно подтвердить клавишей <Enter>.
Пропущенные значения (Missing values)
В SPSS допускаются два вида пропущенных значений:
Пропущенные значения, определяемые системой (System-defined missing values): Если в матрице данных есть незаполненные численные ячейки, система SPSS самостоятельно идентифицирует их как пропущенные значения. Этот факт отображается в матрице данных с помощью запятой (,).
Пропущенные значения, задаваемые пользователем ( User-defined missing values): Если в определенных случаях у переменных отсутствуют значения, например, если на вопрос не был дан ответ, ответ неизвестен, или существуют другие причины, пользователь может с помощью кнопки Missing объявить эти значения как пропущенные. Пропущенные значения можно исключить из последующих вычислений. В нашем примере пропущенным значением, определяемым пользователем мы объявим вариант ответа "0" (нет данных) для переменной sex.
Подтвердите настройку по умолчанию None (Нет) клавишей <Enter>.
7.
Сжатие данных (англ. data compression) — алгоритмическое преобразование данных, производимое с целью уменьшения их объёма. В статистике, математике, прикладной статистике, математических методах часто применяется сжатие данных, для более удобной работы с ними. При этом, сжатие сопровождается потерей информации, так как чем более полно будет описание выборки тем лучше, однако сжатие предусматривает сокращение выборки и тем самым упускает некоторые моменты. Эти моменты, относительно окончательного результата, незначительны, но все же они есть.
Сжатие основано на устранении избыточности, содержащейся в исходных данных. Простейшим примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности ссылкой на уже закодированный фрагмент с указанием его длины. Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других. Сокращение объёма данных достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких — длинными. Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или шум, зашифрованные сообщения), принципиально невозможно без потерь.
Допустимость потерь: Основным критерием различия между алгоритмами сжатия является описанное выше наличие или отсутствие потерь. В общем случае алгоритмы сжатия без потерь универсальны в том смысле, что их применение безусловно возможно для данных любого типа, в то время как возможность применения сжатия с потерями должна быть обоснована. Для некоторых типов данных искажения не допустимы в принципе. В их числе
символические данные, изменение которых неминуемо приводит к изменению их семантики: программы и их исходные тексты, двоичные массивы и т. п.;
жизненно важные данные, изменения в которых могут привести к критическим ошибкам: например, получаемые с медицинской измерительной аппаратуры или контрольных приборов летательных, космических аппаратов и т. п.;
многократно подвергаемые сжатию и восстановлению промежуточные данные при многоэтапной обработке графических, звуковых и видеоданных.
Одним из способов сжатия данных – метод Фибоначи. Суть подхода в том, что в процессе уплотнения информации блок цифровых данных какой-либо протяженности, рассматривается как слишком большое целое положительное число, которое является набором из трех небольших чисел. Такое представление чисел является линейной формой Фибоначи.
Способы (виды) сжатия данных: 1. Статическое сжатие данных (static data compression) — используется для длительного хранения и архивации; выполняется при помощи специальных сервисных программ-архиваторов, например ARJ, PKZIP/PKUNZIP. После восстановления (декомпрессии) исходная запись восстанавливается. 2. Динамическое сжатие (сжатие в реальном времени; dynamic compression, compression in real time) — предназначено для сокращения занимаемой области дисковой памяти данными, требующими оперативного доступа и вывода на внешние устройства ЭВМ (в том числе на экран монитора). Динамическое сжатие данных и их восстановление производится специальными программными средствами автоматически и «мгновенно». 3. Физическое сжатие (physical compression) — методология сжатия, при которой данные перестраиваются в более компактную форму «формально», то есть без учета характера содержащейся в них информации. 4. Логическое сжатие (logical compression) — методология, в соответствии с которой один набор алфавитных, цифровых или двоичных символов заменяется другим. При этом смысловое значение исходных данных сохраняется. Примером может служить замена словосочетания его аббревиатурой. Логическое сжатие производится на символьном или более высоком уровне и основано исключительно на содержании исходных данных. Логическое сжатие не применяется для изображений. 5. Симметричное сжатие (symmetric compression) — методология сжатия, в соответствии с которой принципы построения алгоритмов упаковки и распаковки данных близки или тесно взаимосвязаны. При использовании симметричного сжатия время, затрачиваемое на сжатие и распаковку данных, соизмеримо. В программах обмена данными обычно используется симметричное сжатие. 6. Асимметричное сжатие (asymmetric compression) — методология, в соответствии с которой при выполнении работ «в одном направлении» времени затрачивается больше, чем при выполнении работ в другом направлении. На сжатие изображений обычно затрачивается намного больше времени и системных ресурсов, чем на их распаковку. Эффективность этого подхода определяется тем, что сжатие изображений может производиться только один раз, а распаковываться с целью их отображения – многократно. Алгоритмы асимметричные «в обратном направлении» (на сжатие данных затрачивается меньше времени, чем на распаковку) используется при выполнении резервного копирования данных. 7. Адаптивное кодирование (adaptive encoding) — методология кодирования при сжатии данных, которая заранее не настраивается на определенный вид данных. Программы, использующие адаптивное кодирование, настраиваются на любой тип сжимаемых данных, добиваясь максимального сокращения их объема. 8. Неадаптивное кодирование (nonadaptive encoding) — методология кодирования, ориентированная на сжатие определенного типа или типов данных. Кодировщики, построенные по этому принципу, имеют в своем составе статические словари «предопределенных подстрок», о которых известно, что они часто появляются в кодируемых данных. Примером может служить метод сжатия Хаффмена. 9. Полуадаптивное кодирование (half-adaptive coding) — методология кодирования при сжатии данных, которая использует элементы адаптивного и неадаптивного кодирования. Принцип действия полуадаптивного кодирования заключается в том, что кодировщик выполняет две группы операций: вначале — просмотр массива кодируемых данных и построение для них словаря, а затем — собственно кодирование. 10. Сжатие без потерь (lossless compression) — методология сжатия, при которой ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. 11. Сжатие с потерями (lossy compression) — методология, при которой для обеспечения максимальной степени сжатия исходного массива часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемой. Однако для программ, работающих с графикой, это часто бывает целесообразно. Качество восстановленного изображения зависит от характера графического материала и корректности реализованного в программе алгоритма сжатия.
12. Существует ряд алгоритмов сжатия, учитывающих допустимые уровни потерь исходного графического образа в конкретных вариантах использования его восстановленного изображения, например, путем просмотра его на экране монитора, распечатки принтером, в полиграфии. Эти методы имеют общее наименование «сжатия с минимизацией потерь». 1)Сжатие изображения (image compression) — технический прием или метод сокращения объема (размеров) записи графических изображений (рисунков, чертежей, схем) на их носителе (например, на магнитном диске, магнитной ленте). По существу «сжатие изображения» является разновидностью динамического сжатия. Для его реализации используются различные способы кодирования данных, которые ориентированы на элементы графики, составляющие изображение, включая и движущиеся объекты. Применяется также при передаче факсимильной информации по каналам связи, в системах мультимедиа, видеофонах. 2)Сжатие диска (disk compression) — технический прием, основанный на динамическом сжатии в процессе их записи на диск, а при считывании — их автоматическом восстановлении в исходную форму. Сжатие диска используется с целью увеличения емкости диска. В зависимости от характера записей емкость диска может быть увеличена примерно от 1,5 до 5 раз. Сжатие диска осуществляется специальными прикладными программами, например DoubleSpace, Stacker, SuperStor.
Ранжированный ряд - это распределение отдельных единиц совокупности в порядке возрастания или убывания исследуемого признака. Ранжирование позволяет легко разделить количественные данные по группам, сразу обнаружить наименьшее и наибольшее значения признака, выделить значения, которые чаще всего повторяются.
Сортировка данных — это средство, интегрированное в анализ данных. Может понадобиться расположить в алфавитном порядке фамилии в списке или составить перечень продуктов в порядке убывания их количества на складе. Сортировка данных помогает лучше осмысливать данные, организовывать и находить необходимые сведения и в результате принимать более эффективные решения.
Частота – это численность отдельных вариантов, т.е. число, показывающее как число раз (как часто) встречается те или иные варианты. Например, если рассматривать ответы испытуемых по результатам тестирования, то частота будет то количество ответ которое пришлось на определенный номер теста. Таким образом, выглядеть распределение частот будет следующим образом:
Хі 2 5 7
f 4 8 9
Хі – вариант (т.е.отдельное значение признака), f – частота варианта. Совокупность частот – это совокупность выборки.
Ряд распределения по дискретному признаку, имеющ огранич число вариантов строится след образом:
Все имеющ варианты заполняются в процессе возрастания или убывания, т.е. производится ранжирование.
Подсчитываются частоты (поторяемость)каждого варианта, кот записываются напротив этого варианта.
Пропущенными значениями могут быть кумулятивные частоты, кот надо считать и относит частоты, кот заполняются также рядом в столбик в табл. В конце табл подсчитывается итог.
8.
Квантильная стандартизация. Примером квантильной стандартизации служит процентильная стандартизация, когда отметке «сырой» шкалы у присваивается новое значение ее процентильного ранга PR(у). Квантиль является общим понятием, частными случаями которого могут быть, например, кроме процентилей, квартили, квинтели и децили. Три квартильные отметки (Q1, Q2, Q3) разбивают эмпирическое распределение тестовых оценок на 4 части (кварты) таким образом, что 25% испытуемых располагаются ниже Q1, 50% — ниже Q2 и 75% — ниже Q3. Четыре квинтеля (K1, К2, Кз, К4) делят выборку аналогичным образом на 5 частей с шагом 20% и девять децилей (D1, ..., D9) разбивают выборку на десять частей с шагом 10%. Номер соответствующего квантиля используется в качестве новой преобразованной тестовой оценки. Квантильная шкала отличается тем, что ее построение никак не связано с видом распределения первичных тестовых оценок, которое может быть нормальным или иметь любую другую форму. Единственным условием для ее построения является возможность ранжирования испытуемых по величине у. Квантильные ранги имеют прямоугольное распределение, то есть в каждом интервале квантильнои шкалы содержится одинаковая доля обследованных лиц. Стандартизация тестовых оценок путем их перевода в квантильную шкалу стирает различия в особенностях распределения психодиагностических показателей, так как сводит любое распределение к прямоугольному. Поэтому с позиции теории измерений квантильные шкалы относятся к шкалам порядка: они дают информацию, у кого из испытуемых сильнее выражено тестируемое свойство, но ничего не позволяют сказать о том, насколько или во сколько раз сильнее. Построенная диагностическая модель может считаться психодиагностическим тестом только после прохождения всесторонних испытаний на предмет оценки психометрических свойств. Основными психометрическими свойствами психодиагностических методик, кроме стандартизированности, являются надежность и валидность. Надежность теста — это характеристика методики, отражающая точность психодиагностических измерений, а также устойчивость результатов теста к действию посторонних случайных факторов. Результат психологического исследования обычно подвержен влиянию большого количества неучитываемых факторов (например, эмоциональное состояние и утомление, если они не входят в круг исследуемых характеристик, освещенность, температура и другие особенности помещения, в котором проводится тестирование, уровень мотивированности испытуемых и т. д.). Поэтому любая эмпирически полученная оценка по тесту yi представляется как сумма истинной оценки у и ошибки измерения ε: yi=у + е.
Шкала процентильных рангов. Процентили позволяют установить ранг первичного показателя испытуемого в нормативной группе. Процентильный ранг, соответствующий данному первичному баллу, показывает процент испытуемых в нормативной выборке, результаты которых не выше данного первичного балла.
Процентили не следует смешивать с процентными показателями, представляющими процент правильно выполненных заданий испытуемым группы. В отличие от последнего — первичного — процентиль является производным показателем, указывающим на долю от общего числа испытуемых группы.
Помимо удобств, связанных с простотой интерпретации, процентильные ранги имеют существенные недостатки. Шкала процентильных рангов нелинейна, т.е. в различных областях шкалы первичных баллов увеличение на 1 балл может соответствовать различным увеличениям на шкале процентилей. Поэтому процентили не только не отражают, а даже искажают реальные различия результата выполнения теста.
Поэтому использование процентилей довольно ограничено. В силу удобства и простоты их применяют в основном в нормативно-ориентированных тестах для самооценки знаний учащихся, сообщения результатов самим учащимся и их родителям.
В SPSS: Выберите в меню команды Transform (Преобразовать) Rank Cases... (Присвоить ранги наблюдениям) Откроется диалоговое окно Rank Cases.
Р ис.
8.10: Диалоговое
окно Rank Cases
ис.
8.10: Диалоговое
окно Rank Cases
В поле By: (По) можно задать группирующую переменную. В этом случае назначение рангов будет выполнено раздельно по группам, образуемым этой переменной.
Присвоим переменной (с максимальным значением переменной tju1) ранг 1; для этого щелкните в поле Assign Rank I to (Присвоить ранг 1) на опции Largest value (Максимальное значение).
Щелкнув на кнопке Rank types... (Типы рангов), можно увидеть стандартную настройку Rank. Пока оставим ее без изменений.
Кнопка Ties... (Связки) открывает диалоговое окно Rank Cases: Ties.
Его настройки указывают, как программа будет поступать при появлении одинаковых измеренных величин. По умолчанию принято (и, как правило, это наилучший вариант), что присваивается среднее (Mean) из значений рангов этих величин. При установке Low все значения получают наименьший, при установке High — наибольший из этих рангов. При выбранной опции Sequential ranks to unique values (Присваивать последовательные ранги) все связанные наблюдения получают одинаковый ранг; следующему наблдению присваивается следующее по порядку целое число. Поэтому максимальный присвоенный ранг равен не общему количеству значений, а количеству различных значений.
В файл данных будет добавлена переменная rtju1, содержащая ранги, присвоенные значениям переменной tju1. Для обозначения ранговой переменной к имени исходной переменной спереди дописывается буква г.
Затем отсортируем файл данных по этой ранговой переменной.
Ряд распределения – упорядоченное распределение единиц совокупности оп определенному варьирующему признаку; это простая группировка, в кот известна численность едениц в группировках или удельный вес каждой группы в общем итоге. Ряды распр имеют 2 осн признака: 1. значение груп.признака (вариант Х), 2. частота- f или частость –w. Частота- f- численность отдельных вариантов, т.е.число, показывающее какое число раз (как часто встречается те или иные варианты. сумм f=N (N общий объем выборки). Частость— относительными частотами.–w-частота выраженная в % к итогу. W= f/ сумм f. Т.е. Относительные частоты – отношение частоты к объему выборки. Для создания частотной табл в SPSS: Выберите в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Frequencies (Частоты) Появится диалоговое окно Frequencies. Пример: Психическое состояние
|
|
Частота |
Проценты |
Допус- тимые проценты |
Нако- пленные проценты |
|
Крайне неустой- чивое |
20 |
18,5 |
18,7 |
18,7 |
|
Неустой- чивое |
40 |
37,0 |
37,4 |
56,1 |
Допус- тимые |
Устойчивое |
41 |
38,0 |
38,3 |
94,4 |
|
Очень устойчивое |
6 |
5,6 |
5,6 |
100,0 |
|
Всего |
107 |
99,1 |
100,0 |
|
Отсут-ствующие |
нет данных |
1 |
,9 |
|
|
Всего |
|
108 |
100,0 |
|
|
Каждая строка частотной таблицы описывает одно возможное значение. Строка с пометкой нет данных представляет наблюдения, в которых не было дано никакого ответа. Всего имеется 107 допустимых ответов, а также одно наблюдение, в котором психическое состояние неизвестно (данные отсутствуют либо утеряны). Первый столбец содержит метки отдельных значений (крайне неустойчивое, неустойчивое, устойчивое, ...). Во втором столбце под заголовком «Частота» приведена частота каждого из вариантов ответа на вопрос из теста. Так, к примеру, 20 человек на вопрос о психическом состоянии дали ответ: «крайне неустойчивое», а 40 человек — «неустойчивое». В третьем столбце показана процентная частота каждого ответа. Процентная частота соответствует отношению каждого из вариантов ответа к общему количеству опрашиваемых, включая утерянные значения. В четвертом столбце дано допустимое процентное значение. При определении этого значения утерянные данные исключаются. Последний столбец содержит накопленные процентные значения. Накопленные проценты — это сумма процентных частот допустимых ответов. Так, например, процент респондентов, которые дали ответ крайне неустойчивое или неустойчивое, составляет 56,1%. Это число определяется выражением: 18,7% + 37,4% = 56,1%. В последней строке содержится сумма всех столбцов (Всего).
Пропущенные значения (Missing values)
В SPSS допускаются два вида пропущенных значений:
Пропущенные значения, определяемые системой (System-defined missing values): Если в матрице данных есть незаполненные численные ячейки, система SPSS самостоятельно идентифицирует их как пропущенные значения. Этот факт отображается в матрице данных с помощью запятой (,).
Пропущенные значения, задаваемые пользователем ( User-defined missing values): Если в определенных случаях у переменных отсутствуют значения, например, если на вопрос не был дан ответ, ответ неизвестен, или существуют другие причины, пользователь может с помощью кнопки Missing объявить эти значения как пропущенные. Пропущенные значения можно исключить из последующих вычислений. В нашем примере пропущенным значением, определяемым пользователем мы объявим вариант ответа "0" (нет данных) для переменной sex.
Подтвердите настройку по умолчанию None (Нет) клавишей <Enter>.
9.
Под распределением понимают соответствие между наблюдаемыми вариантами и их частотами, или относительными частотами. Пр.: Задано распределение частот выборки объема = 20: 2 6 12 3 10 7 Написать распределение относительных частот. Решение. Найдем относительные частоты, для чего разделим частоты на объем выборки: =3/20 = 0,15, W2= 10/20 = 0,50, W3 = 7/20 = 0,35. Напишем распределение относительных частот: xi 2 6 12 Wi 0,15 0,50 0,35 Проверка: 0,15+0,50+ 0,35= 1. |
Кумулятивная частота – накопленная частота (включает в себя помимо частоты своего варианта еще частоту последующей нижней границы: Пр.: для 2 – частота=3, для 6-13, для 12 – 20). Иногда выражается в %.
Ряд распределения по дискретному признаку, имеющ огранич число вариантов строится след образом:
Все имеющиеся варианты заполняются в процессе возрастания или убывания, т.е. производится ранжирование.
Подсчитываются частоты (поторяемость)каждого варианта, кот записываются напротив этого варината.
Пропущенными значениями могут быть кумулятивные частоты, кот надо считать и относит частоты, кот заполняются также рядом в столбик в табл. В конце табл подсчитывается итог. Пропущенные значения в вариантах или частотах высчитываются исходя из вышеперечисленных формул.