

Выбор способа измерения расстояния между объектами, или кластерами (изначально считается, что каждый объект соответствует одному кластеру).
По умолчанию используется квадрат Евклидова расстояния – расстояние между объектами равно сумме квадратов разностей между значениями одноименных переменных объектов.
Предположим, что марка автомобиля А имеет показатели технического состояния и возраста 5 и 6, а марка В – 7 и 4 соответственно.
Тогда по этим двум переменным (координатам) расстояние между марками А и В вычисляется следующим образом: (5 - 7)2 + (6 - 4)2 = 8.
При выполнении анализа сумма квадратов разностей вычисляется для всех переменных. Получаемые расстояния используются программой при формировании кластеров1.
Относительно вычисления расстояния может возникнуть следующий вопрос: будет ли адекватным результат кластерного анализа в том случае, если переменные имеют различные шкалы измерения? Так, все переменные файла cars.sav имеют самые разные шкалы.
Для решения проблемы шкалирования в SPSS используется стандартизация, в частности, ее простой метод – нормализация переменных, приводящая все переменные к стандартной z-шкале (среднее равно 0, стандартное отклонение – 1).
При нормализации всех переменных при проведении кластерного их веса становятся одинаковыми. В случае если все исходные данные имеют одну и ту же шкалу измерения, либо веса переменных по смыслу должны быть разными, стандартизацию переменных проводить не нужно.
Формирование кластеров
Два основных метода формирования кластеров:
метод слияния – исходные кластеры увеличиваются путем объединения до тех пор, пока не будет сформирован единственный кластер, содержащий все данные.
метод дробления – сначала все данные объединяются в один кластер, который затем делится на части до тех пор, пока не будет достигнут желаемый результат.
По умолчанию SPSS использует метод слияния.
В методе слияния предусмотрены несколько способов объединения объектов. Способ, применяемый по умолчанию, называется межгрупповым связыванием, или связыванием средних внутри групп. SPSS вычисляет наименьшее среднее значение расстояния между всеми парами групп и объединяет две группы, оказавшиеся наиболее близкими.
На первом этапе, когда все кластеры представляют собой одиночные объекты, данная операция сводится к обычному попарному сравнению расстояний между объектами. Термин среднее значение приобретает смысл лишь на втором этапе, когда сформированы кластеры, содержащие более одного объекта.
Например, для данных файла cars.sav на начальном этапе имеется 15 кластеров (объектов); сначала в кластер объединяются два объекта с наименьшим расстоянием друг от друга. Затем подсчет расстояний повторяется, и в кластер объединяется еще одна пара переменных.
На втором этапе получается либо 13 свободных объектов и 1 кластер, объединяющий 2 объекта, либо 11 свободных объектов и 2 кластера по 2 объекта в каждом. В итоге все объекты окажутся в одном большом кластере.
Интерпретация результатов.
Желаемое число кластеров и оценка результатов анализа зависят от целей исследователя. Для файла cars.sav, приведенного ниже в заданиях, предпочтительное число кластеров 3. Анализ показывает, что все марки можно разделить на 3 группы:
высокая стоимость (среднее значение – 15230), небольшой срок эксплуатации (4 года) и средний пробег (85 400 км).
средняя стоимость, небольшой пробег, наибольший возраст, но хорошее техническое состояние.
недорогие модели с большим пробегом и невысоким рейтингом технического состояния.
Методы разбиения на кластеры довольно разнообразны, в них по-разному выбирается способ определения близости между кластерами, а также используются разные алгоритмы вычислений. Результаты кластеризации зависят от выбранного метода. Поэтому результаты кластерного анализа могут быть дискуссионными, часто они служат лишь подспорьем для содержательного анализа.
Методы кластерного анализа:
Сегодня существует достаточно много методов кластерного анализа. Остановимся на некоторых из них (ниже приводимые методы принято называть методами минимальной дисперсии).
Пусть Х - матрица наблюдений: Х = (Х1, Х2,..., Хu) и квадрат евклидова расстояния между Х и Хj определяется по формуле:
1 )
Метод Ворда.
В этом методе в качестве целевой функции
применяют внутригрупповую сумму
квадратов отклонений, которая есть ни
что иное, как сумма квадратов расстояний
между каждой точкой (объектом) и средней
по кластеру, содержащему этот объект.
На каждом шаге объединяются такие два
кластера, которые приводят к минимальному
увеличению целевой функции, т.е.
внутригрупповой суммы квадратов. Этот
метод направлен на объединение близко
расположенных кластеров.
)
Метод Ворда.
В этом методе в качестве целевой функции
применяют внутригрупповую сумму
квадратов отклонений, которая есть ни
что иное, как сумма квадратов расстояний
между каждой точкой (объектом) и средней
по кластеру, содержащему этот объект.
На каждом шаге объединяются такие два
кластера, которые приводят к минимальному
увеличению целевой функции, т.е.
внутригрупповой суммы квадратов. Этот
метод направлен на объединение близко
расположенных кластеров.
2) Центроидный метод. Расстояние между двумя кластерами определяется как евклидово расстояние между центрами (средними) этих кластеров:
d2 ij = (X -Y)Т(X -Y) Кластеризация идет поэтапно на каждом из n-1 шагов объединяют два кластера G и , имеющие минимальное значение d2ij Если n1 много больше n2, то центры объединения двух кластеров близки друг к другу и характеристики второго кластера при объединении кластеров практически игнорируются. Иногда этот метод иногда называют еще методом взвешенных групп.
3 )
Метод ближнего
соседа - это
когда мы находим ближайшую точку к новой
и считаем, что новая относится к тому
же классу, что и эта ближайшая. Или,
по-другому, мы определяем расстояние
от новой точки до целого класса равным
расстоянию от нее до ближайшей точки
из этого класса. Соответственно, к какому
классу новая точка оказалась ближе в
смысле этого расстояния - к тому ее и
относим.
алгоритм ближайшего соседа, когда
расстоянием между кластерами считается
минимальное из расстояний между парами
объектов, один из которых входит в первый
кластер, а другой — во второй;
)
Метод ближнего
соседа - это
когда мы находим ближайшую точку к новой
и считаем, что новая относится к тому
же классу, что и эта ближайшая. Или,
по-другому, мы определяем расстояние
от новой точки до целого класса равным
расстоянию от нее до ближайшей точки
из этого класса. Соответственно, к какому
классу новая точка оказалась ближе в
смысле этого расстояния - к тому ее и
относим.
алгоритм ближайшего соседа, когда
расстоянием между кластерами считается
минимальное из расстояний между парами
объектов, один из которых входит в первый
кластер, а другой — во второй;
4 )
Метод дальнего
соседа - это
другой способ задать расстояние от
точки до класса, равное расстоянию от
этой точки до самой дальней точки класса.
Тот же принцип - новая точка относится
к ближайшему к ней классу в смысле
введенного расстояния. Это значит, что
мы находим самую дальнюю точку от новой,
после чего относим новую к противоположному
классу. алгоритм дальнего соседа,
когда расстоянием между кластерами
считается максимальное из расстояний
между парами объектов, один из которых
входит в первый кластер, а другой — во
второй.
)
Метод дальнего
соседа - это
другой способ задать расстояние от
точки до класса, равное расстоянию от
этой точки до самой дальней точки класса.
Тот же принцип - новая точка относится
к ближайшему к ней классу в смысле
введенного расстояния. Это значит, что
мы находим самую дальнюю точку от новой,
после чего относим новую к противоположному
классу. алгоритм дальнего соседа,
когда расстоянием между кластерами
считается максимальное из расстояний
между парами объектов, один из которых
входит в первый кластер, а другой — во
второй.
5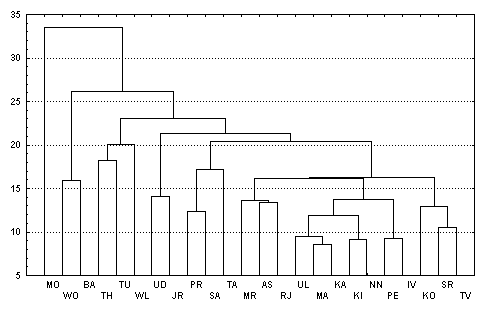 )
Метод средней
связи— метод
связывания; начинается аналогично
методам одиночной или полной связи,
однако критерием кластеризации является
среднее расстояние от индивидуумов
одного кластера до индивидуумов другого.
)
Метод средней
связи— метод
связывания; начинается аналогично
методам одиночной или полной связи,
однако критерием кластеризации является
среднее расстояние от индивидуумов
одного кластера до индивидуумов другого.
6) Связь между группами Дистанция между кластерами равна среднему значению дистанций между всеми возможными парами наблюдений, причём один наблюдения берётся из одного кластера, а другой из другого. Информация, необходимая для расчёта дистанции, находится на основании всех теоретически возможных пар наблюдений. По этой причине данный метод и устанавливается по умолчанию.
7) Связь внутри групп Это вариант связи между группами, а именно, здесь дистанция между двумя кластерами рассчитывается на основании всех возможных пар наблюдений, принадлежащих обоим кластеров, причём учитываются также и пары наблюдений, образующиеся внутри кластеров.
*Метод полных связей.
Суть данного метода в том, что два объекта, принадлежащих одной и той же группе (кластеру), имеют коэффициент сходства, который меньше некоторого порогового значения S. В терминах евклидова расстояния d это означает, что расстояние между двумя точками (объектами) кластера не должно превышать некоторого порогового значения h. Таким образом, h определяет максимально допустимый диаметр подмножества, образующего кластер.
*Метод максимального локального расстояния.
Каждый объект рассматривается как одноточечный кластер. Объекты группируются по следующему правилу: два кластера объединяются, если максимальное расстояние между точками одного кластера и точками другого минимально. Процедура состоит из n - 1 шагов и результатом являются разбиения, которые совпадают со всевозможными разбиениями в предыдущем методе для любых пороговых значений.

 Два
главных недостатка неиерархических
методов состоят в том, что число кластеров
определяется заранее и выбор кластерных
центров происходит независимо. Более
того, результаты кластеризации могут
зависеть от выбранных центров. Многие
неиерархические процедуры выбирают
первые к случаев (к — число кластеров),
не пропуская никаких значений в качестве
начальных кластерных центров. Таким
образом, результаты кластеризации
зависят от порядка наблюдений в данных.
Неиерархическая кластеризация быстрее
иерархических методов, и ее выгодно
использовать при большом числе объектов
или наблюдений. Высказано предположение
о возможности использования иерархических
и неиерархических методов в тандеме.
Во-первых, первоначальное решение по
кластеризации получают, используя такие
иерархические методы, как метод средней
связи или метод Варда. Полученное этими
методами число кластеров и кластерных
центроидов используют в качестве
исходных данных в методе оптимизирующего
распределения.
Два
главных недостатка неиерархических
методов состоят в том, что число кластеров
определяется заранее и выбор кластерных
центров происходит независимо. Более
того, результаты кластеризации могут
зависеть от выбранных центров. Многие
неиерархические процедуры выбирают
первые к случаев (к — число кластеров),
не пропуская никаких значений в качестве
начальных кластерных центров. Таким
образом, результаты кластеризации
зависят от порядка наблюдений в данных.
Неиерархическая кластеризация быстрее
иерархических методов, и ее выгодно
использовать при большом числе объектов
или наблюдений. Высказано предположение
о возможности использования иерархических
и неиерархических методов в тандеме.
Во-первых, первоначальное решение по
кластеризации получают, используя такие
иерархические методы, как метод средней
связи или метод Варда. Полученное этими
методами число кластеров и кластерных
центроидов используют в качестве
исходных данных в методе оптимизирующего
распределения.
В иерархических методах каждое наблюдение образовывает сначала свой отдельный кластер. На первом шаге два соседних кластера объединяются в один; этот процесс может продолжаться до тех пор, пока не останутся только два кластера. В методе, который в SPSS установлен по умолчанию (Between-groups linkage (Связь между группами)), расстояние между кластерами является средним значением всех расстояний между всеми возможными парами точек из обоих кластеров.
Древовидная диаграмма (дендрограмма) (dendrogram). Ее также называют древовидный граф — графическое средство для показа результатов кластеризации. Вертикальные линии представляют объединяемые кластеры. Положение вертикальной линии на шкале расстояния (горизонтальная ось) показывает расстояния, при которых объединяли кластеры. Древовидную диаграмму читают слева направо.
Сосульчатая диаграмма (icicle diagram). Это графическое отображение результатов кластеризации. Она названа так потому, что имеет сходство с рядом сосулек, свисающих с крыши дома. Сосульчатую диаграмму читают сверху вниз.
Л
 и́ца
Черно́ва
(англ. Chernoff
faces)
- отображение многомерных данных в виде
человеческого лица,
его отдельных частей. Люди
легко распознают лица и без затруднения
воспринимают небольшие изменения в
нем. Американский математик
Герман
Чернов
в 1973
году опубликовал работу, в которой
изложил концепцию
использования этой способности
восприятия
лица человека для построения пиктографиков.
Их применяют, как правило, в двух случаях:
1) когда нужно выявить характерные
зависимости или группы наблюдений и 2)
когда необходимо исследовать
предположительно сложные взаимосвязи
между несколькими переменными. Лица
Чернова являются одним из самых
эффективных способов визуализации
многомерных данных, и позволяет легко
оценивать одновременно большое их
количество. Пример
оценки юристами 12 судей по Лицам Чернова
и́ца
Черно́ва
(англ. Chernoff
faces)
- отображение многомерных данных в виде
человеческого лица,
его отдельных частей. Люди
легко распознают лица и без затруднения
воспринимают небольшие изменения в
нем. Американский математик
Герман
Чернов
в 1973
году опубликовал работу, в которой
изложил концепцию
использования этой способности
восприятия
лица человека для построения пиктографиков.
Их применяют, как правило, в двух случаях:
1) когда нужно выявить характерные
зависимости или группы наблюдений и 2)
когда необходимо исследовать
предположительно сложные взаимосвязи
между несколькими переменными. Лица
Чернова являются одним из самых
эффективных способов визуализации
многомерных данных, и позволяет легко
оценивать одновременно большое их
количество. Пример
оценки юристами 12 судей по Лицам Чернова
В заключение приводится затребованная нами дендрограмма, которая визуализирует процесс слияния, приведенный в обзорной таблице порядка агломерации. Она идентифицирует объединённые кластеры и значения коэффициентов на каждом шаге. При этом отображаются не исходные значения коэффициентов, а значения приведенные к шкале от 0 до 25. Кластеры, получающиеся в результате слияния, отображаются горизонтальными пунктирными линиями.
******HIERARCHICAL CLUSTER ANALYSIS*** Dendrogram usinc ( Average Linkage (Between Groups) |
|
Rescaled Distantce |
Cluster Combine |
CASE |
0 5 10 15 20 25 |
Label |
Hum +---- + ---- + ---- + _--_-- + ------ + |
Heineken |
5 |
Becks |
12 - - |
Dos Equis |
11--------------------------------- |
Krcnenbourg |
4 -- |
LcMBribrau |
2 ---- |
Michelcb |
3 - - |
Pabst Blue Ribbon |
7 ------------------------------ |
Rolling Rode |
13 -- - |
Budweiser |
4 --------------- |
Tuborg |
15 - - |
Schmdts |
6 ---------------------- |
Coors Light |
10 - |
Schlitz Light |
17 - |
Miller Light |
8 - - - - - |
Budweiser Light |
9 ------------------- |
Pabst Extra Light |
14 ------------------- |
Olynpia Gold Light |
16 - ------------------- |
В то время как дендрограмма годится только для графического представления процесса слияния, по диаграмме накопления можно проследить деление кластеров. Так как начиная с 7 версии SPSS графическое представление диаграммы накопления оставляет желать лучшего, мы отказались от активирования ее вывода.
Для вводного рассмотрения мы выбрали довольно простой пример, включающий только две переменных. В этом случае конфигурация кластеров поддается представлению в графическом виде.
1 Помимо Евклидова существуют и другие виды расстояний, вычисляемые по другим формулам, при необходимости обратитесь к руководству пользователя SPSS.