

23.Статистические критерии для таблиц сопряженности
Чтобы получить статистические критерии для таблиц сопряженности, щелкните на кнопке Statistics... (Статистика) в диалоговом окне Crosstabs. Откроется диалоговое окно Crosstabs: Statistics (Таблицы сопряженности: Статистика) (см. рис. 11.9).
Флажки в этом диалоговом окне позволяют выбрать один или несколько критериев.
Тест хи-квадрат (X2)
Корреляции
Меры связанности для переменных, относящихся к номинальной шкале
Меры связанности для переменных, относящихся к порядковой шкале
Меры связанности для переменных, относящихся к интервальной шкале
Коэффициент каппа (к)

Рис. 11.8: Графическое представление: столбчатая диаграмма
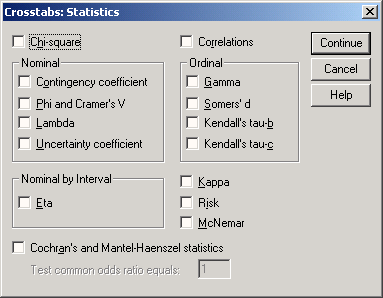
Рис. 11.9: Диалоговое окно Crosstabs: Statistics
Мера риска
Тест Мак-Немара
Статистики Кохрана и Мантеля-Хэнзеля
Эти критерии рассматриваются в двух последующих разделах, причем из-за того, что критерий хи-квадрат имеет большое значение в статистических вычислениях, ему посвящен отдельный раздел.
12.2.3 Таблицы сопряженности с категориальными наборами
На основе наборов со множественными категориями также можно строить таблицы сопряженности с другими переменными. Для примера рассмотрим таблицу сопряженности между набором Smitwirk и переменной geschl. Выполните следующие действия:
Выберите в меню команды Analyze (Анализ) Multiple Response (Множественные ответы) Crosstabs... (Таблицы сопряженности)
Появится диалоговое окно Multiple Response Crosstabs.
Перенесите в список переменных строк набор Smitwirk, а в список переменных столбцов — переменную geschl. Эта переменная появится в списке столбцов с двумя вопросительными знаками, заключенными в скобки.
Щелкните на кнопке Define Ranges... (Определить диапазоны).
Откроется диалоговое окно Multiple Response Crosstabs: Define Variable Range.
Введите минимальное значение 1 и максимальное "2".
Подтвердите выбор кнопкой Continue.
Щелкните на кнопке Options... (Параметры).
Откроется диалоговое окно Multiple Response Crosstabs: Options.
В группе Percentages based on сохраните настройку по умолчанию Cases.
В группе Cell Percentages установите флажок Column.
Подтвердите ввод кнопкой Continue, а затем — ОК.
В окне просмотра будет показана следующая таблица сопряженности.
*** CROSSTABULATION * ** |
|
|
|
|||||||||
$MITWIRK (group) Scheiterungby GESCHL Geschlecht der Mitwirkung |
|
|
|
|||||||||
GESCHL |
|
|
|
|||||||||
Count Iweiblich maennlic |
|
|
|
|||||||||
Col pet |
I |
|
h |
|
|
ROW |
|
|
|
|||
|
I |
|
|
|
|
Total |
|
|
|
|||
|
I |
1 |
I |
2 |
I + I |
24 |
|
|
|
|||
1 |
+ - I |
7 |
+ - - I |
17 |
|
|
|
|||||
Moglichkeiten nicht |
I |
30,4 |
I 26 |
,6 |
I |
27,6 |
|
|
|
|||
|
+ - |
_ _ _ |
+ — — |
— — |
+ |
|
|
|
|
|||
2 |
I |
3 |
I |
23 |
I |
26 |
|
|
|
|||
Mandate bereits bese |
I |
13,0 |
I 35 |
,9 |
I |
29,9 |
|
|
|
|||
|
+ - |
|
+ — — |
|
+ |
|
|
|
|
|||
3 |
I |
10 |
I |
26 |
I |
36 |
|
|
|
|||
Fuhrungs verbal ten de |
I |
43,5 |
I 40 |
,6 |
I |
41,4 |
|
|
|
|||
|
+ - |
_ _ _ |
•f - — |
— — |
+ |
|
|
|
|
|||
4 |
I |
4 |
I |
16 |
I |
20 |
|
|
|
|||
keine Forderung wage |
I |
17 ,4 |
I 25 |
,0 |
I |
23,0 |
|
|
|
|||
|
+ - |
— — — |
+ — — |
— — |
+ |
|
|
|
|
|||
5 |
I |
11 |
I |
18 |
I |
29 |
|
|
|
|||
zu wenig politische 6 |
I + — I |
47 ,8 |
I 28 |
,1 |
I + I |
33,3 8 |
|
|
|
|||
0 |
+ - - I |
8 |
|
|
|
|||||||
Befurchtung beruflic 7 |
I + -I |
, 0 |
I 12 |
,5 |
I + I |
9,2 6 |
|
|
|
|||
0 |
+ - — I |
6 |
|
|
|
|||||||
Befurchtung persqnli |
I |
, 0 |
I 9 |
,4 |
I |
6,9 |
|
|
|
|||
|
+ — |
_ _ _ |
+ - - |
— — |
+ |
|
|
|
|
|||
8 |
I |
4 |
I |
10 |
I |
14 |
|
|
|
|||
nichts bewegen konne |
I |
17,4 |
I 15 |
,6 |
I |
16,1 |
|
|
|
|||
|
+ - |
_ _ _ |
+ - - - |
- - + |
|
|
|
|
|
|||
|
|
|
|
9 |
I |
7 |
I |
17 I |
24 |
|||
gesundheitliche |
Grun |
I |
30,4 |
I |
26,6 I |
27,6 |
||||||
|
|
|
|
|
+ — |
_ _ _ |
+ - - |
- — - + |
|
|||
|
|
|
|
Column |
23 |
|
|
64 |
87 |
|||
|
|
|
|
Total |
26,4 |
|
|
73,6 |
100,0 |
|||
Percents |
and |
totals based |
on |
respondents |
||||||||
S7 |
valid |
cases ; |
23 |
missing cases |
||||||||
Процентные значения рассчитываются на основе количества допустимых наблюдений. Если сравнить оба пола, то значительное различие заметно только в частоте упоминания мнения, что функции уже распределены и в боязни негативного влияния на работу и личную жизнь; такие ответы мужчины дают чаще. Женщины, напротив, чаще ссылаются на недостаток политического опыта.
Двумерные таблицы
К наиболее часто используемым инструментам изучения взаимосвязи двух переменных относятся методы анализа таблицы сопряженности. Анализ таблицы является весьма простым и наглядным, и вместе с тем эффективным инструментом изучения одновременно двух переменных. Двумерная таблица сопряженности для переменных ql2 и q2 (табл. 2.1) составлена по данным исследования «Мониторинг социальных и экономических перемен в России», которые получены из ответов на вопросы:
qlO Как бы вы оценили в настоящее время материальное положение вашей семьи ?
Хорошее, очень хорошее.
Среднее.
Плохое, очень плохое.
Затрудняюсь ответить.
q12 Как бы вы оцениkb в целом политическую обстановку в России ?
Благополучная, спокойная.
Напряженная.
Критическая, взрывоопасная.
Затрудняюсь ответить.
Таблица 2.1. Таблица сопряженности для переменных q10 n q12
q10 Как бы вы оценили в настоящее время материальное положение вашей семьи? |
q12 Как бы вы оценили в целом политическую обстановку в России? |
Все го |
|||
благопо лучная. спокойная |
напря женная |
критическая, взрыво опасная |
затрудняюсь ответить |
|
|
Хорошее, очень хорошее |
12 |
48 |
47 |
17 |
124 |
Среднее |
20 |
478 |
666 |
138 |
1302 |
Плохое, очень плохое |
11 |
160 |
701 |
И |
953 |
Затрудняюсь ответить |
0 |
6 |
15 |
7 |
28 |
Всего |
43 |
692 |
1429 |
243 |
2407 |
В табл. 2.1 на пересечении строк и столбцов находятся числа, показывающие, какое количество единиц анализа (в данном случае — респондентов) обладают одновременно данными градациями по переменным q10 и q12. Например, на пересечении первой строки и второго столбца стоит число 48 — это значит, что градацию «1» переменной q10 (считают материальное положение своей семьи хорошим или очень хорошим) и градацию «2» переменной q12 (считают политическую обстановку в России напряженной) одновременно отметили 48 человек.
Внизу таблицы сопряженности располагаются суммарные данные по всем колонкам, а с правого края таблицы — аналогичные суммы по всем строкам. Иными словами, сбоку справа и снизу находятся одномерные частотные распределения для переменных, использованных в таблице.
Можно ли по данным табл. 2.1 сразу дать ответ на вопрос о наличии зависимости между переменными q10 и q12? По всей вероятности, нет — стоящие в клетках таблицы числа ничего особенного не демонстрируют. Поставим вопрос иначе — а что, собственно, мы ищем? По всей видимости, при наличии зависимости между переменными q10 и q12 при разных значениях переменной q10 поведение данных по переменной q12 будет различным. Если говорить о примере табл. 2.1 — это значит, что респонденты, по-разному оценивающие свое материальное положение, будут по-разному оценивать политическую обстановку в России.
Если бы количество респондентов, имеющих различные значения переменной q10, было одинаковым, в табл. 2.1 можно было бы сравнивать между собой строки и оценить, насколько схожи значения в клетках, располагающихся в одной колонке. Однако количество респондентов по строкам сильно разнится, поэтому для такого сравнения построим таблицу, в клетках которой располагаются не абсолютные количества единиц анализа, а процент от сумм по строкам. Другими словами, число респондентов в каждой строке берется за 100% и от этого числа считается процент в каждой клетке таблицы. Таким образом, мы как бы нормируем каждую строку таблицы и получаем возможность сравнения распределений по строкам (табл. 2.2).
Таблица 2.2 показывает, что оценка политической ситуации в России значительно отличается по группам респондентов, по-разному оценивающих материальное положение своей семьи, и, следовательно, имеется определенная зависимость между переменными q10 и q12.
При анализе зависимостей двух переменных важнейшим является вопрос о том, какую из переменных считать зависимой, т.е. подверженной влиянию, а какую — независимой, т.е. влияющей. В табл. 2.1 и в последующих рассуждениях предполагалось, что оценка материального положения семьи — независимая переменная, иными словами. она влияет на оценку политической ситуации, которая, следовательно, выступает зависимой переменной. Если мы поменяем места ми переменные в модели и будем считать, что оценка политической ситуации оказывает влияние на оценку материального положения семьи, целесообразно изменить таблицу и проводить нормирование не от сумм по строкам, а от сумм по колонкам. Таблица 2.3 построена именно таким образом, т.е. использованы данные табл. 2.1, но нормированные по колонкам.
Таблица 2.2. Таблица сопряженности переменных q10 и q12, %
q10 Как бы вы |
q12 Как бы вы оценили в целом |
Все |
||||
оценили |
политическую обстановку в России? |
го |
||||
в настоящее время материальное положение вашей семьи? |
благопо лучная. спокойная |
напря женная |
критическая. взрыво опасная |
затруд няюсь отвеппъ |
i |
|
Хорошее, очень |
9,7 |
38,7 |
37,9 |
13,7 |
100,0 |
|
хорошее |
|
|
|
|
|
|
Среднее |
1,5 |
36,7 |
51,2 |
10,6 |
100,0 |
|
Плохое, очень |
1,2 |
16,8 |
73,6 |
8,5 |
100.0 |
|
плохое |
|
|
|
|
|
|
Затрудняюсь |
0 |
21,4 |
53,6 |
25,0 |
100.0 |
|
ответить |
|
|
|
|
|
|
Всего |
1,8 |
28,7 |
59,4 |
10,1 |
100.0 |
|
Очевидно, что при решении вопроса о зависимости между переменными q10 и q12 при анализе табл. 2.3 необходимо сравнивать распределения по разным колонкам таблицы, а не по строкам, как при анализе таблицы, представленной на рис. 2.2. Такое сравнение показывает, что среди респондентов, оценивающих политическую ситуацию в России как критическую, материальное положение своей семьи оценивают как плохое 49,1% респондентов (колонка 3, строка 3 табл. 2.3). В то же время среди оценивающих политическую ситуацию оптимистичнее, как напряженную, материальное положение своей семьи считают плохим 23,1% респондентов (колонка 3, строка 2 табл. 2.3).
Таблица 2.3. Таблица сопряженности переменных q10 n q12, %
q10 Как бы вы оценили |
q12 Как бы вы оценили в целом политическую обстановку в России? |
Все го |
||||
в настоящее время материальное положение вашей семьи? |
благопо лучная. спокойная |
напря женная |
критическая, взрыво опасная |
затруд няюсь ответить |
|
|
Хорошее, очень хорошее |
27,9 |
6,9 |
3,3 |
7,0 |
5,2 |
|
Среднее |
46,5 |
69,1 |
46,6 |
56,8 |
54,1 |
|
Плохое, очень плохое |
25,6 |
23,1 |
49,1 |
33,3 |
39,6 |
|
Затрудняюсь ответить |
0 |
0,9 |
1,0 |
2,9 |
1,2 |
|
Всего |
100,0 |
100,0 |
100,0 |
100,0 |
100.0 |
|
 Рис.
2.2.
Меню команды Crosstabs
пакета
SPSS
Рис.
2.2.
Меню команды Crosstabs
пакета
SPSS
При анализе таблиц сопряженности крайне важно помнить, что мы, по сути дела, ищем наличие (или отсутствие) определенных статистических, а не причинно-следственных зависимостей. Вопрос о том, какая из переменных является причиной, т.е. оказывает влияние, а какая меняется вследствие этой причины, не может быть решен не только с помощью анализа таблиц, но и любым другим формально- статистическим методом. Это вопрос понимания той модели, которую мы проверяем методами построения таблиц либо другими статистическими приемами. Но результатом такой проверки не может быть утверждение: «наша модель верна», либо «наша модель неверна». Утверждать мы можем лишь то, что данные не противоречат (или, наоборот, противоречат) построенной модели, что само по себе отнюдь не является гарантией ее справедливости.
Иллюстрацию этой мысли можно найти у О. Генри. В рассказе «Вождь краснокожих» главный герой предложит изящную модель для ответа на вопрос о том, почему дует ветер — потому, что деревья качаются. Если собрать данные о ветре и поведении деревьев во время ветра, любой статистический метод покажет, что данные ни в коем случае не противоречат этой модели, что. видимо, и послужило Джиму основанием для столь глубокомысленного вывода.
Ряд распределения – упорядоченное распределение единиц совокупности оп определенному варьирующему признаку; это простая группировка, в кот известна численность едениц в группировках или удельный вес каждой группы в общем итоге. Ряды распр имеют 2 осн признака: 1. значение груп.признака (вариант Х), 2. частота- f или частость –w. Частота- f- численность отдельных вариантов, т.е.число, показывающее какое число раз (как часто встречается те или иные варианты. сумм f=N (N общий объем выборки). Частость— относительными частотами.–w-частота выраженная в % к итогу. W= f/ сумм f. Т.е. Относительные частоты – отношение частоты к объему выборки. Для создания частотной табл в SPSS: Выберите в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Frequencies (Частоты) Появится диалоговое окно Frequencies.
Пр.: Задано распределение частот выборки объема = 20:
2 6 12
3 10 7
Написать распределение относительных частот.
Решение. Найдем относительные частоты, для чего разделим частоты на объем выборки:
=3/20 = 0,15, W2= 10/20 = 0,50, W3 = 7/20 = 0,35.
Напишем распределение относительных частот:
xi 2 6 12
Wi 0,15 0,50 0,35
Проверка: 0,15+0,50+ 0,35= 1.
В SPSS: Тест хи-квадрат (X2)
При проведении теста хи-квадрат проверяется взаимная независимость двух переменных таблицы сопряженности и благодаря этому косвенно выясняется зависимость обоих переменных. Две переменные считаются взаимно независимыми, если наблюдаемые частоты (f0) в ячейках совпадают с ожидаемыми частотами (fe).
Для того, чтобы провести тест хи-квадрат с помощью SPSS, выполните следующие действия:
Выберите в меню команды Analyze (Анализ) Descriptive Statistics (Дескриптивные статистики) Crosstabs... (Таблицы сопряженности)
Кнопкой Reset (Сброс) удалите возможные настройки.
Перенесите переменную sex в список строк, а переменную psyche — в список столбцов.
Щелкните на кнопке Cells... (Ячейки). В диалоговом окне установите, кроме предлагаемого по умолчанию флажка Observed, еще флажки Expected и Standardized. Подтвердите выбор кнопкой Continue.
Щелкните на кнопке Statistics... (Статистика).
Откроется описанное выше диалоговое окно Crosstabs: Statistics.
Установите флажок Chi-square (Хи-квадрат). Щелкните на кнопке Continue, а в главном диалоговом окне — на ОК.
Вы получите следующую таблицу сопряженности.