

4.2.3. Кодирование с минимальной избыточностью
Для
практики важно, чтобы коды сообщений
имели по возможности наименьшую длину.
Алфавитное кодирование пригодно для
любых типов сообщений
![]() .
Если про
.
Если про
![]() более ничего не известно, то сформулировать
задачу оптимизации сложно. Однако, на
практике, часто имеется дополнительная
информация. Например, для текстов на
естественных языках известно распределение
вероятности появления букв в сообщении.
Использование такой информации позволяет
корректно поставить и решить задачу
оптимизации алфавитного кодирования.
более ничего не известно, то сформулировать
задачу оптимизации сложно. Однако, на
практике, часто имеется дополнительная
информация. Например, для текстов на
естественных языках известно распределение
вероятности появления букв в сообщении.
Использование такой информации позволяет
корректно поставить и решить задачу
оптимизации алфавитного кодирования.
Идея
оптимизации алфавитного кодирования
может состоять в том, чтобы наиболее
часто применяемым буквам входного
алфавита
![]() сопоставить наиболее короткие элементарные
коды. Если длины элементарных кодов
равны, как в случае двоично–десятичного
кодирования, то данный подход не имеет
смысла. Но если длины элементарных кодов
различны, то длина кода сообщения зависит
от состава букв в сообщении и от того,
каких элементарные коды каким буквам
назначены.
сопоставить наиболее короткие элементарные
коды. Если длины элементарных кодов
равны, как в случае двоично–десятичного
кодирования, то данный подход не имеет
смысла. Но если длины элементарных кодов
различны, то длина кода сообщения зависит
от состава букв в сообщении и от того,
каких элементарные коды каким буквам
назначены.
Алгоритм
назначения элементарных кодов может
быть следующий: нужно отсортировать
буквы, входящие в сообщение
![]() ,
в порядке убывания количества вхождений,
элементарные коды отсортировать в
порядке возрастания длины и назначить
коды буквам в этом порядке. Естественно,
что этот простой метод позволяет решить
задачу оптимизации лишь для конкретного
сообщения
,
в порядке убывания количества вхождений,
элементарные коды отсортировать в
порядке возрастания длины и назначить
коды буквам в этом порядке. Естественно,
что этот простой метод позволяет решить
задачу оптимизации лишь для конкретного
сообщения
![]() и конкретной схемы кодирования
и конкретной схемы кодирования
![]() .
.
Рассмотрим
количественную оценку, позволяющую
сравнивать между собой различные схемы
алфавитного кодирования. Пусть задан
алфавит
![]() и вероятность появления букв в сообщении
и вероятность появления букв в сообщении
![]() ,
где
,
где
![]() – вероятность появления буквы
– вероятность появления буквы
![]() .
Будем считать, что
.
Будем считать, что
![]() .
.
Для
каждой разделимой схемы
![]() алфавитного кодирования математическое
ожидание длины сообщения при кодировании
алфавитного кодирования математическое
ожидание длины сообщения при кодировании
![]() определяется следующим образом:
определяется следующим образом:
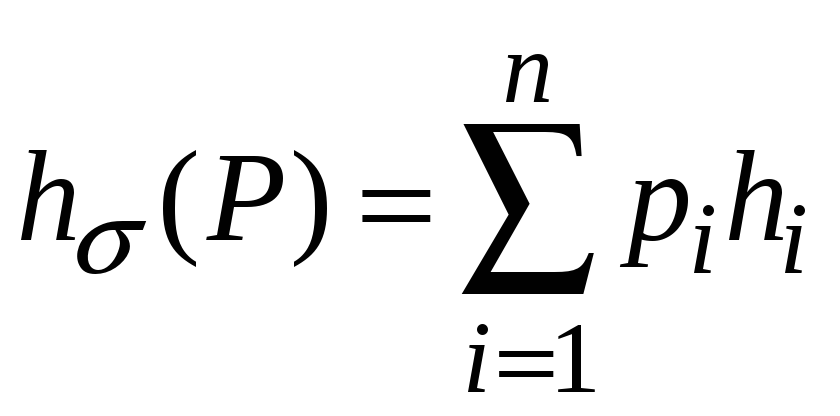 ,
где
,
где
![]() ,
(4.1)
,
(4.1)
и
называется средней
ценой кодирования
![]() при распределении вероятностей
при распределении вероятностей
![]() .
.
Пример.
Для разделимой схемы
![]() ,
,
![]() ,
,
![]() при распределении вероятностей
при распределении вероятностей
![]() цена кодирования
цена кодирования
![]() равна 0,5*1+0,5*2=1,5; а при распределении
вероятностей {0.9,0.1} она равна 0.9*1+0.1*2=1,1.
равна 0,5*1+0,5*2=1,5; а при распределении
вероятностей {0.9,0.1} она равна 0.9*1+0.1*2=1,1.
Алфавитное
кодирование
![]() ,
для которого средняя цена кодирования
минимальна, называется кодированием с
минимальной избыточностью, или оптимальным
кодированием, для распределения
вероятности
,
для которого средняя цена кодирования
минимальна, называется кодированием с
минимальной избыточностью, или оптимальным
кодированием, для распределения
вероятности
![]() .
.
4.2.4. Алгоритм квазиоптимального кодирования Фано
Известны два метода построения кодов, близких к оптимальному, принадлежащие Фано и Шеннону. Рекурсивный алгоритм Фано отличается чрезвычайной простотой конструкции и строит разделимую префиксную схему алфавитного кодирования, близкого к оптимальному. Метод Фано заключается в следующем: упорядоченный в порядке убывания вероятностей список букв делится на две последовательные части так, чтобы суммы вероятностей входящих в них букв как можно меньше отличались друг от друга. Буквам из первой части приписывается символ 0, а буквам из второй части – символ 1. Далее точно также поступают с каждой из вновь полученных частей, если она содержит, по крайней мере, две буквы. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве. Каждой букве ставится в соответствие последовательность символов, приписанных в результате этого процесса данной букве. Легко видеть, что полученный в результате код является префиксным.
В
таблице 4.3 приведен пример построения
схемы кодирования с использованием
алгоритма Фано для алфавита, включающего
7 букв. Буквы встречаются в сообщениях
с вероятностями
![]() .
На первом этапе список букв был разделен
на две части. В первую часть вошли буквы
с вероятностями
.
На первом этапе список букв был разделен
на две части. В первую часть вошли буквы
с вероятностями
![]() .
Во вторую – с вероятностями
.
Во вторую – с вероятностями
![]() .
Общая сумма вероятностей первой часть
– 0,59, второй – 0,41. Принятое разбиение
обеспечивает минимальную разницу
суммарных вероятностей двух частей,
равную 0,18. Если принять иное разбиение,
например,
.
Общая сумма вероятностей первой часть
– 0,59, второй – 0,41. Принятое разбиение
обеспечивает минимальную разницу
суммарных вероятностей двух частей,
равную 0,18. Если принять иное разбиение,
например,
![]() и
и
![]() ,
то разница будет равной 0,20. В результате,
первым символом в кодах трех первых
букв принимается 0, а оставшихся четырех
– 1.
,
то разница будет равной 0,20. В результате,
первым символом в кодах трех первых
букв принимается 0, а оставшихся четырех
– 1.
Далее,
первая группа букв снова делится на две
части –
![]() и
и
![]() .
В кодах букв первой части вторым символом
принимается 0, в кодах букв второй части
– 1. Так как первая часть содержит
единственную букву, для ее построение
кода закончилось. Вторая часть содержит
две буквы и им просто присваиваются
разные последние кодирующие символы.
Точно такая же процедура производится
в отношении второй половины списка
букв, полученной в результате первого
деления. В нижней строке таблицы, во
втором столбце стоит значение средней
цены кодирования, расчитанной для
принятой схемы кодирования по формуле
(4.1).
.
В кодах букв первой части вторым символом
принимается 0, в кодах букв второй части
– 1. Так как первая часть содержит
единственную букву, для ее построение
кода закончилось. Вторая часть содержит
две буквы и им просто присваиваются
разные последние кодирующие символы.
Точно такая же процедура производится
в отношении второй половины списка
букв, полученной в результате первого
деления. В нижней строке таблицы, во
втором столбце стоит значение средней
цены кодирования, расчитанной для
принятой схемы кодирования по формуле
(4.1).
Таблица 4.3.
|
|
Метод Фано |
Метод Хаффмена |
||
|
Коды |
|
Коды |
|
|
|
0.20 |
00 |
2 |
10 |
2 |
|
0.20 |
010 |
3 |
11 |
2 |
|
0.19 |
011 |
3 |
000 |
3 |
|
0.12 |
100 |
4 |
010 |
3 |
|
0.11 |
101 |
4 |
011 |
3 |
|
0.09 |
110 |
4 |
0010 |
4 |
|
0.09 |
111 |
4 |
0011 |
4 |
|
Цена кодирования |
2.80 |
|
2.78 |
|