

2.3 Высокопроизводительные кластеры
Архитектура высокопроизводительных кластеров появилась как развитие принципов построения систем MPP (Massive Parallel Processing)
МРР Система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти, коммуникационные процессоры или сетевые адаптеры, иногда — жесткие диски и/или другие устройства ввода/вывода
Кластеры также как и MPP системы состоят из слабосвязанных узлов, которые могут быть как однородными, так и, в отличие от MPP, различными или гетерогенными. Особое внимание при проектировании высокопроизводительной кластерной архитектуры уделяется обеспечению высокой эффективности коммуникационной шины, связывающей узлы кластера.
HPC-кластеры по своей производительности вплотную приблизились к суперкомпьютерам, а по соотношению цена/производительность даже обогнали их (причем весьма значительно). Однако следует помнить, что HPC-кластеры эффективны лишь для решения сравнительно узкого круга параллельных задач, не требующих интенсивного межпроцессорного обмена.
Начиная с ядра 2.2.x, Linux поддерживает HPC-кластеризацию, даже созданы специальные узкоспециализированные дистрибутивы, однако их использование не является обязательным, т.к. RedHat и Fedora уже включают в себя все необходимое.
Помимо операционной системы нужны еще и компиляторы, обеспечивающие высокую степень параллелизма. Бесплатный GCC, к сожалению, недостаточно эффективен и рекомендуется остановить свой выбор на коммерческих - компилятор от Intel, а лучше - компиляторы компании The Portland Group, Inc. (более известной под аббревиатурой PGI). И Intel, и PGI поддерживают языки Fortran/Cи/Cи++ и операционные системы Linux/xBSD/Windows. Приложения, распространяемые вместе с исходными текстами, выгодно отличаются тем, что могут быть перекомпилированы любым компилятором, что позволяет потребителям повышать их производительность (рисунок 3).

Рисунок 3 Высокопроизводительный кластер
3. Коммуникационной среды для повышения эффективности вычислений
Особое внимание при проектировании высокопроизводительной кластерной архутектуры уделяется обеспечению высокой эффективности коммуникационной шины, связывающей узлы кластера. Так как в кластерах нередко применяются массовые относительно низкопроизводительные шины, то приходится принимать ряд мер по исключению их низкой пропускной способности на производительность кластеров и организацию эффективного распараллеливания в кластере. Так, например, пропускная способность одной из самых высокоскоростных технологий Fast Ethernet на порядки ниже, чем у межсоединений в современных суперкомпьютерах МРР-архитектуры.
Для решения проблем низкой производительности сети применяют несколько методов:
- кластер разделяется на несколько сегментов, в пределах которых узлы соединены высокопроизводительной шиной типа Myrinet, а связь между узлами разных сегментов осуществляется низкопроизводительными сетями типа Ethernet/Fast Ethernet. Это позволяет вместе с сокращением расходов на коммуникационную среду существенно повысить производительность таких кластеров при решении задач с интенсивным обменом данными между процессами. - применение так называемого «транкинга», т.е. объединение нескольких каналов Fast Ethernet в один общий скоростной канал, соединяющий несколько коммутаторов. Очевидным недостатком такого подхода является «потеря» части портов, задействованных в межсоединении коммутаторов.
- для повышения производительности создаются специальные протоколы обмена информацией по таким сетям, которые позволяют более эффективно использовать пропускную способность каналов и снимают некоторые ограничения накладываемые стандартными протоколами (TCP/IP,IPX).
Такой метод часто используют в ситемах класса Beowulf. Основным качеством, которым должен обладать высокопроизводительный кластер являтся горизонтальная масштабируемость, так как одним из главных преимуществ, которые предоставляет кластерная архитектура является возможность наращивать мощность существующей системы за счет простого добавления новых узлов в систему. Причем увеличение мощности происходит практически пропорционально мощности добавленных ресурсов и может производиться без остановки системы во время ее функционирования. В системах с другой архитектурой (в частности MPP) обычно возможна только вертикальная масштабируемость: добавление памяти, увеличение числа процессоров в многопроцессорных системах или добавление новых адаптеров или дисков. Оно позволяет временно улучшить производительность системы. Однако в системе будет установлено максимальное поддерживаемое количество памяти, процессоров или дисков, системные ресурсы будут исчерпаны, и для увеличеия производительности придется создавать новую систему или существенно перерабатывать старую. Кластерная система также допускает вертикальную масштабируемость. Таким образом, за счет вертикального и горизонтального масштабирования кластерная модель обеспечивает большую гибкость и простоту увеличения производительности систем.
При построении кластеров в качестве сред передачи данных чаще всего используется:
Gigabit Ethernet - наиболее доступный тип коммуникационной среды, оптимальное решение для задач, не требующих интенсивных обменов данными (например, визуализация трехмерных сцен или обработка геофизических данных). Эта сеть обеспечивает пропускную способность на уровне MPI* (около 70 Мбайт/с) и задержку (время между отправкой и получением пакета с данными) примерно 50 мкс.
MPI - наиболее распространенный и производительный протокол передачи сообщений в кластерных системах, а также интерфейс программирования для создания параллельных приложений.
Myrinet - наиболее распространенный тип коммуникационной среды с пропускной способностью до 250 Мбайт/с и задержкой 7 мкс, а новое, недавно анонсированное ПО для этой сети позволяет сократить эту цифру в два раза. Сеть SCI отличается небольшими задержками - менее 3 мкс на уровне MPI - и обеспечивает пропускную способность на уровне MPI от 200 до 325 Мбайт/с.
Сеть SCI отличается небольшими задержками - менее 3 мкс на уровне MPI - и обеспечивает пропускную способность на уровне MPI от 200 до 325 Мбайт/с.
А так же обеспечивает масштабируемую архитектуру, позволяющую строить системы, состоящие из множества блоков. SCI представляет собой комбинацию шины и локальной сети, сеть SCI имеет топологию двух- или трехмерного тора и не требует применения коммутаторов, что уменьшает стоимость системы.
QsNet - очень производительное и дорогое оборудование, обеспечивающее задержку менее 2 мкс и пропускную способность до 900 Мбайт/с.
Наиболее перспективная на сегодня технология системной сети - InfiniBand. Ее текущая реализация имеет пропускную способность на уровне MPI до 1900 Мбайт/с и время задержки от 3 до 7 мкс. Создав унифицированную топологию fabric, архитектура InfiniBand обеспечивает механизм совместного использования межкомпонентных соединений ввода/вывода между большим количеством серверов. Архитектура InfiniBand не устраняет необходимость в других технологиях межкомпонентных соединений. Она создает более эффективный способ соединять хранилища данных, коммуникационные сети и серверные кластеры, обеспечивая инфраструктуру ввода/вывода, которая предлагает эффективность, надежность и масштабируемость, так необходимые для работы центров данных.
Общедоступные высокоскоростные технологии системных сетей Myrinet, QsNet, InfiniBand используют коммутируемую топологию Fat Tree (рисунок 4).
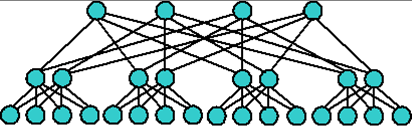
Рисунок 4 топология FatTree
Сеть fat tree (утолщенное дерево) — топология компьютерной сети, изобретенная Charles E. Leiserson из MIT, является дешевой и эффективной для суперкомпьютеров. В отличие от классической топологии дерево, в которой все связи между узлами одинаковы, связи в утолщенном дереве становятся более широкими (толстыми, производительными по пропускной способности) с каждым уровнем по мере приближения к корню дерева. Часто используют удвоение пропускной способности на каждом уровне. Сети с топологией fat tree являются предпочтительными для построения кластерных межсоединений на основе технологии Infiniband.
Вычислительные узлы кластера соединяются кабелями с коммутаторами нижнего уровня (leaf, или edge switches), которые в свою очередь объединяются через коммутаторы верхнего уровня (core, или spine switches). При такой топологии имеется много путей передачи сообщений между узлами, что позволяет повысить эффективность передачи сообщений благодаря распределению загрузки при использовании различных маршрутов. Кроме того, при помощи Fat Tree можно объединить практически неограниченное количество узлов, сохранив при этом хорошую масштабируемость приложений.