

2.3.2.Процессоры risc с сокращенным набором команд
Идеей создания процессора RISC (Reduced Instruction Set Computer – компьютер с сокращенным набором команд) появившейся в 70-е годы ХХ века было то, что он «воспринимал» минимальный набор команд. Создание таких процессоров было следствием известного правила «80/20»: 80% кода типовой программы использует 20% простейших машинных команд ( ряд сложных команд быстрее выполняются, если разбить их на много простых). К отличительным особенностям RISC-процессоров относят:
Сокращенный набор команд (обычно не более 100).
Фиксированная длина машинных инструкций.
Простой формат команды.
Простая адресация.
Выполнение большинства команд происходит за один такт.
Команды выполняют только простые действия.
Операндами могут быть только регистры.
Большое количество регистров общего назначения.
Несколько жестких многоступенчатых конвейеров.
Большая по объему раздельная кэш-память.
Наличие оптимизирующих компиляторов (они имеют возможность анализировать исходный код и менять последовательность команд).
Для третьего поколения этих процессоров характерно следующее:
Процессор является 64-х разрядным, суперскалярным.
Наличие встроенных конвейерных блоков арифметики с плавающей запятой.
Наличие многоуровневой кэш-памяти.
Реализовывать внеочередное выполнение команд позволяют алгоритмы прогнозирования ветвления, а также переназначение регистров.
Увеличение быстродействия достигается повышением тактовой частоты и усложнением схемы кристалла. В первом направлении работает фирма DEC (процессоры Alpha). Структура процессора Alpha 21064 представлена на рис. 2.1.
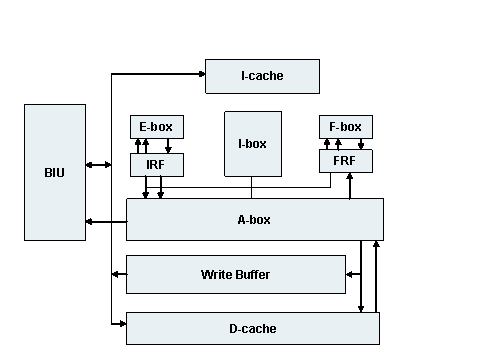
Рис. 2.1 Структурная схема процессора Alpha 21064 [4]
Функциональные блоки процессора Alpha 21064 [1]:
I-cache - кэш команд.
IRF - регистровый файл целочисленной арифметики.
F-box - устройство арифметики с плавающей точкой.
E-box - устройство целочисленной арифметики (7 ступеней конвейера).
I-box - командное устройство (управляет кэш команд, выборкой и дешифрацией команд).
A-box - устройство управления загрузкой/сохранением данных. Управляет процессом обмена данными м/у IRF, FRF, кэш данных и внешней памятью.
Write Buffer - буфер обратной записи.
D-cache - КЭШ данных.
BIU - интерфейсный блок, с помощью которого подключаются внешняя кэшпамять, размером 128 Кб-8 Мб.
Одной из последних разработок, сделанных на базе этого процессора, является процессор Alpha 21264. Он может читать до четырех инструкций за одни такт, а исполнять – до шести инструкций. Есть возможность выполнять команды с изменением очередности (Out-of-Order). Эффективность этого алгоритма зависит от количества инструкций, которые может обрабатывать процессор для поиска оптимального порядка следования команд. Для сравнения, процессоры фирмы Intel (Pentium Pro, Xeon) способны одновременно работать с 40 командами, Hewlett-Packard (PA-8000) – 56 команд, Alpha – 80!
Для большей эффективности внеочередной обработки команд, в процессоры Alpha добавлены еще 48 целочисленных регистров и 40 регистров для данных с плавающей запятой. При обработке инструкции не нужно перегружать результат в целевой регистр, вместо этого происходит переименование временного регистра (Register Renaming). Точно также работают и остальные процессоры, но в процессорах Alpha есть существенная особенность, каждый их 80 целочисленных регистров продублирован. Это позволяет существенно повысить частоту процессора.
Ряд технических решений представлен и в процессорах PA-8000. Их отличительной особенностью является большой набор средств для внеочередного выполнения команд. Они позволяют аппаратно планировать загрузку ковейеров. В состав процессора от Hewlett-Packard входят:
Два АЛУ для целочисленных операций.
Два устройства для выполнения операций сдвига.
Два устройства для сложения чисел с плавающей запятой.
Два устройства деления.
Два устройства для выполнения операций записи/загрузки.
Современные RISC-процессоры чаще всего применяют в качестве рабочих станций высшего класса, персональных рабочих станций, серверов.
Как следует из вышесказанного RISC-процессоры это не «надархитектурное « свойство, а просто способ выполнения.