

2.3.6.Процессоры с многопоточной архитектурой
MTA –Multi Threaded Architecture – многопоточная архитектура. Всерьез о создании такой системы задумалась фирма Terra. В качестве основных особенностей выделялись:
Высокая эффективность распараллеливания начиная с третьего уровня (см. п.2.3.5.).
Простота распараллеливания и переноса программ.
Применять подобные системы планировалось в следующих областях [5]:
задачи моделирования;
автомобильная и аэрокосмическая промышленность;
сейсмический анализ (например, в нефтегазовой промышленности);
трехмерные задачи в системах САПР;
вычислительная химия (в том числе исследования белка, составление лекарств и др.);
задачи национальной безопасности (криптография);
предсказание погоды;
предоставление информации по запросу;
сложные задачи виртуальной реальности;
приложения сверхбольших данных.
Для решения своих задач нашли применение следующие архитектурные особенности. Однородная общая оперативная память. Нет иерархического построения памяти. Отказ от кэш-памяти данных. За счет этого удалось сократить накладные расходы при распараллеливании, т.к. необходимость сопоставления кэшей различных процессоров исчезла сама собой (эта идея была реализована ранее фирмой Hitachi).
Другое преимущество заключается в том, что переключение между задачами после выполнения команды происходит быстро, опять же, без накладных расходов. Это позволяет процессорам быть все время занятыми независимо от задержек оперативной памяти или задержек синхронизации. Для поддержания большой занятости процессоров емкость пула (хранилища) задач сделана больше, чем число доступных аппаратных потоков.
Поток может быть создан и удален без вмешательства операционной системы, с помощью обычных непривилегированных команд. Этим уменьшаются потери на управление потоками.
Зачастую, узким местом становится оперативная память. Однако, MTA допускает обращения к памяти в каждом такте, даже в задачах целочисленной сортировки (в таких задачах основное ограничение накладывает пропускная способность оперативной памяти).
Сердцевиной MTA-компьютера является трехмерная сеть с коммутацией пакетов. Соединение тороидальное (см. рис. 2.2).
К каждому узлу присоединяют ресурсы (процессор и оперативную память). Задержка составляет 3 такта на узел. Максимальная задержка составляет 4,5*(р)1/2, где р – число процессоров. Число устройств памяти в два или в четыре раза больше числа процессоров. Обращения к оперативной памяти распределяются среди всех банков устройств памяти. Такое случайное обращение поддерживает одинаковые величины задержек при обращении к оперативной памяти.
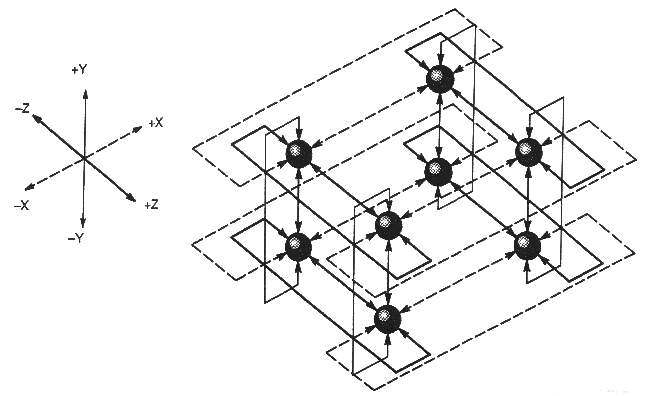
Рис. 2.2. Трехмерный тор [6]
Для фирмы Terra, как не сложно догадаться, была создана Unix-подобная операционная система. В ней использовалась BSD-версия Unix и микроядро, которое было разработано самостоятельно.
2.3.7.Технология Hyper-Threading
В первой половине 2002 года была представлена технология Hyper-Threading на процессоре Intel Xeon. Эта разработка позволяла обрабатывать данные в многопоточном режиме. Команды пересылки данных разбивались на параллельные потоки за счет архитектурного дублирования регистров микропроцессорных схем. Т.е. один процессор мог обрабатывать данные в таком режиме, как работают два процессора со своими потоками команд и наборами данных. Сейчас возможен выпуск полностью многопоточных процессоров, аналогичных архитектуре Terra MTA.