

4.Потоковые параллельные вычисления для физического моделирования
4.1.Общие принципы распараллеливания расчётов
Задачи вычислительного моделирования физических систем очень часто связаны с независимым применением одного и того же набора операций (одного и того же алгоритма обработки) к большому количеству объектов одинакового типа.
Н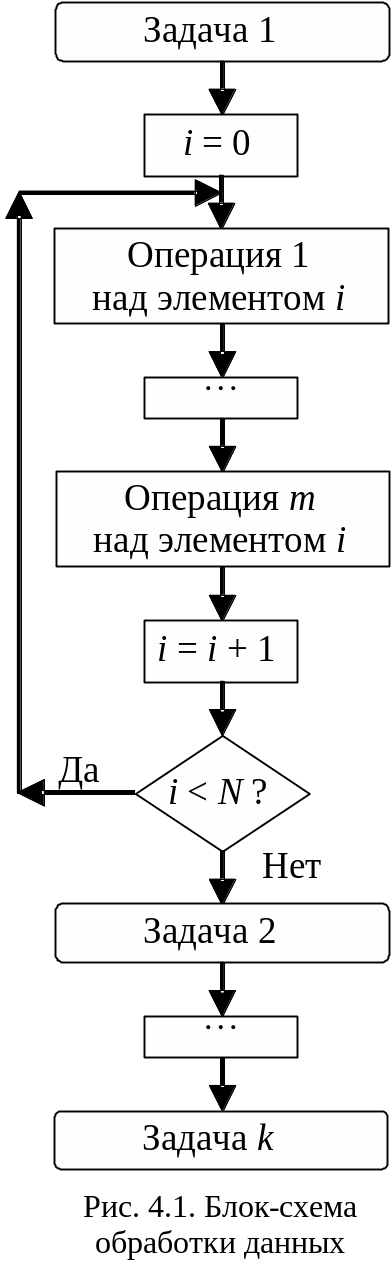 апример,
в молекулярной динамике на каждом
временном шаге необходимо рассчитывать
силы, действующие на каждую из частиц,
а затем определять ускорения, скорости
и перемещения частиц, соответствующие
этим силам. Ещё более распространённый
метод Монте-Карло предполагает
независимую обработку большого количества
однотипных случайных событий. Очевидно,
что решение подобных задач можно очень
существенно ускорить путём
распараллеливания расчётов.
апример,
в молекулярной динамике на каждом
временном шаге необходимо рассчитывать
силы, действующие на каждую из частиц,
а затем определять ускорения, скорости
и перемещения частиц, соответствующие
этим силам. Ещё более распространённый
метод Монте-Карло предполагает
независимую обработку большого количества
однотипных случайных событий. Очевидно,
что решение подобных задач можно очень
существенно ускорить путём
распараллеливания расчётов.
Пусть есть некоторый набор однотипных данных (N элементов), которые требуется обработать в соответствии с заданным алгоритмом. Блок-схема последовательных вычислений, без какого-либо распараллеливания, будет иметь общий вид, показанный на рис. 4.1. Из этой блок-схемы видно, что возможны 3 типа распараллеливания расчётов [11]:
Распараллеливание по данным. Если операции 1 - m (рис. 4.1) над каждым i-м элементом не зависят от исхода операций над остальными элементами, то эти элементы не обязательно обрабатывать последовательно. Расчёты можно распределить между несколькими вычислительными блоками (процессорами, конвейерами, машинами), как это показано на рис. 4.2. Именно такое распараллеливание характерно для физического моделирования.

Рис. 4.2. Распараллеливание по данным
Распараллеливание по инструкциям. Может оказаться, что некоторые инструкции из набора операций 1 – m независимы друг от друга, и тогда, при наличии нескольких вычислительных блоков, эти инструкции могут быть исполнены параллельно. Схема распараллеливания по инструкциям показана на рис. 4.3. Такое распараллеливание аппаратно реализовано в современных центральных процессорах общего назначения, поскольку оно эффективно при исполнении программ, интенсивно обменивающихся разнородной информацией с другими программами и с пользователями ПК.
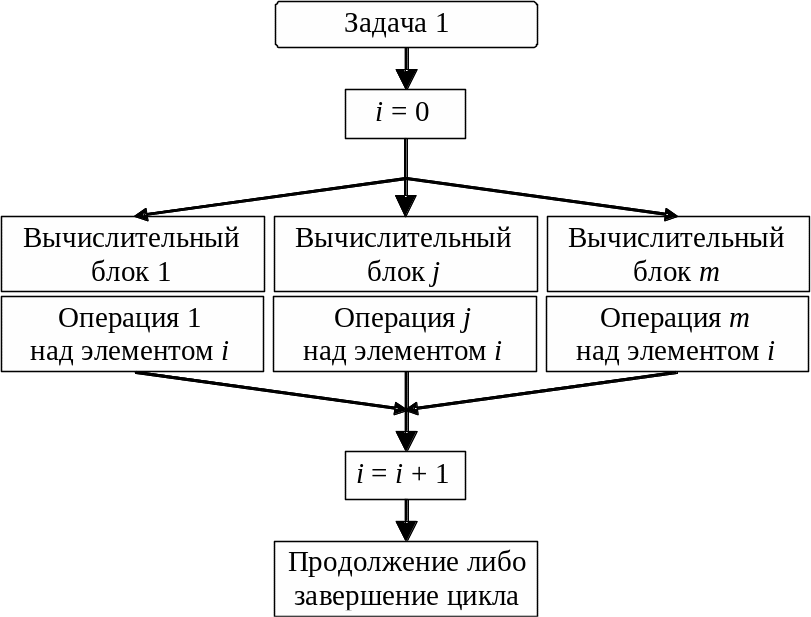
Рис. 4.3. Распараллеливание по инструкциям
Распараллеливание по задачам. Возможно, если задачи 1 - k (рис. 4.1) независимы друг от друга. Особенно актуально для сетевых серверов и других вычислительных систем, выполняющих одновременно несколько функций либо обслуживающих многих пользователей.
4.2.Обмен данными между процессором и памятью
Моделирование физических систем обычно связано с обработкой больших массивов данных (например, как в молекулярной динамике, - с расчётом траекторий большого количества частиц). Эти данные хранятся в памяти, доступной процессору (оперативная память компьютера, видеопамять, кэш). Двумя основными характеристиками, определяющими эффективность взаимодействия процессора с памятью, являются латентность и пропускная способность.
Латентность – это время доступа к памяти, т.е. время ожидания процессором данных после запроса. Латентностью определяется производительность вычислений при решении задач, требующих частого обращения к произвольным, неупорядоченным ячейкам памяти. Такой обмен с памятью характерен для «кибернетических» задач, связанных со сложным управлением потоком команд, обработкой уникальных входных сигналов. В числе этих задач интерактивные приложения, – приложения, управляемые пользователем в ходе исполнения, - которые обычны для персональных компьютеров. Современные интерактивные приложения обычно обмениваются с пользователем и другими приложениями большим количеством разнородной информации.
Недостаточная латентность памяти ограничивает возможности процессоров, работающих на высокой частоте, поскольку они не успевают получать данные для обработки.
Пропускная способность (ПС) характеризует объём данных, которыми процессор может обменяться с памятью за единицу времени. Высокая пропускная способность оказывается важнее латентности в задачах, позволяющих организовать считывание данных из последовательных ячеек памяти непрерывным потоком.
Высокую пропускную способность памяти можно эффективно использовать в задачах физического моделирования, которые связаны с применением сравнительно несложных алгоритмов обработки к большим массивам данных.
В последние годы пропускная способность памяти (ПС памяти) увеличивается существенно быстрее, чем уменьшается латентность. В табл. 4.1. приведены современные времена удвоения ПС памяти различных типов [12]. В последнем столбце табл. 4.1. даны величины уменьшения латентности памяти тех же типов за то же время (т.е. за время удвоения ПС). Видно, что во всех случаях латентность улучшалась гораздо менее чем в два раза, то есть – существенно медленнее, чем возрастала пропускная способность. Такая тенденция указывает на перспективность разработки алгоритмов физического моделирования, ориентированных скорее на потоковую обработку данных, эффективность которой определяется пропускной способностью памяти, чем на произвольный доступ к памяти. Эффективность потоковой обработки данных в большей мере определяется пропускной способностью памяти, чем латентностью, а эффективность произвольного доступа – наоборот.
Из табл. 4.1. видно, что пропускная способность кэша процессоров и оперативной памяти (которые задействованы при физическом моделировании на ПК) удваивается за 2-3 года. Можно ожидать, что и в ближайшем будущем эта тенденция сохранится.
Таблица 4.1.
Динамика улучшения пропускной способности и латентности памяти [12]
Тип памяти |
Время удвоения ПС, годы |
Улучшение латентности за то же время, разы |
Кэш процессоров |
1.7 |
1.3 |
Оперативная память (DRAM) |
2.9 |
1.2 |
Доступ к данным по сетям |
2.1 |
1.3 |
Дисковая память |
2.8 |
1.3 |