

3.3. Комбинированные системы
Самым логичным решением после изучение SMP и MPP-систем было бы создать систему, объединяющую все достоинства и той и другой архитектуры. Так появилась гибридная система NUMA (Nonuniform memory access) – система с неоднородным доступом к памяти.
Память организована следующим образом – она физически является распределенной по различным частям системы, но процессоры видят ее как единую, с единым адресным пространством. NUMA-системы состоят из однородных базовых модулей, которые объединены при помощи высокоскоростного коммутатора. Сохраняется единое адресное пространство, доступ к памяти других процессоров (из других модулей) поддерживается на аппаратном уровне. Для доступа к локальной памяти требуется значительно меньшее время чем при доступе к удаленной (принадлежащей другому модулю).
NUMA-архитектура представляет собой MPP-архитектуру, где в качестве отдельных элементов использованы SMP узлы. Чтобы легче было понять, что же имелось ввиду в последнем предложении, приведем схему компьютера с комбинированной организацией памяти.
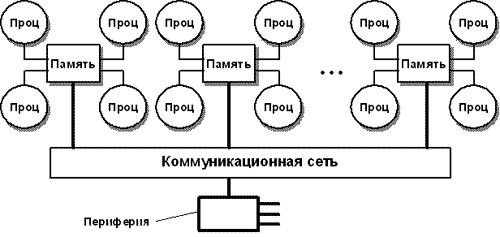
Рис. 3.4. Структурная схема вычислительной системы с комбинированной организацией памяти [9]
При подобной организации доступа к памяти очень важно, чтобы все процессоры получали одинаковые значение одних и тех же переменных в любой момент времени. Эта проблема называется когерентность кэш-памяти. Она появляется как следствие использования разделяемой памяти. Т.к. кэш-память принадлежит конкретному процессору, то она недоступна для остальных процессоров (даже для тех, которые находятся в его модуле). Именно поэтому необходимо проводить синхронизацию памяти. Применение нашли два варианта.
Отслеживать шинные запросы (Snoopy Bus Protocol). Кэши отслеживают переменные, которые передаются к любому из процессоров и, при необходимости, делают себе копии этих переменных;
Или выделить специальную область в памяти, в которой будет проверятся достоверность всех копий используемых переменных.
3.4. Мультипроцессорные и мультикомпьютерные системы
Мультипроцессорные и мультикомпьютерные системы представляют собой комбинации систем, которые рассматривались ранее. В этом пункте приведены современные разработки в этой области. Называть их суперЭВМ наверное нельзя, но от этого они не теряют своих возможностей в производительности. Вполне возможно, что скоро они будут такими же обыкновенными и легко доступными, как это произошло с двуядерными системами.
3.5.Кластеры пэвм и рабочих станций
Под кластером будем понимать два и более компьютеров, которые объединены коммуникационной сетью. Объединение возможно на основе шинной архитектуры или на основе коммутатора. Несколько машин представляются пользователю как единое техническое решение. Узлами кластера (под узлом понимают один из компьютеров) могут выступать любые ЭВМ, вплоть до обычных. Использование кластера позволяет защитить систему от сбоев. Так, например, если из строя выходит один из узлов, то решение его задачи возьмет на себя другой узел. Корректно организованный кластер можно легко масштабировать. Кластер является наиболее дешевой вычислительной единицей, особенно, если он построен на стандартных комплектующих (процессоры, коммутаторы, диски и т.п.). Кластеры можно организовать на различных уровнях компьютерной системы, включая аппаратную часть, операционные системы, системы управления и прочие приложения. Чем больше уровней системы будет объединено в кластерную систему, тем надежнее будет система, тем легче будет ее масштабировать, тем легче будет управлять ею.
Условно разделить кластеры можно на два класса. Это деление было предложено Язеком Радаевским и Дугласом Эдлайном.
К первому классу относятся кластеры, полностью построенные из стандартных деталей. Такие детали легкодоступны, просты в обслуживании, взаимозаменяемы и, что самое главное, стоят не так дорого как уникальные комплектующие.
Во второй класс попадают системы, при создании которых были использованы эксклюзивные, нераспространенные детали. Производительность таких кластеров заметно выше систем из первого класса, но далеко не у всех есть возможность приобрести комплектующие (зачастую, чем реже встречается деталь, тем выше ее стоимость).
Ввиду того, что кластер сравнительно легко собирается, различных конфигураций может быть очень много. Есть ряд задач, под которые наиболее часто собирают кластеры:
Системы высокой надежности;
Высокопроизводительные системы;
Многопоточные системы.
Естественно, такое деление весьма условно. Если решать неимоверно сложную параллельную задачу, то не обойтись без высокопроизводительного кластера. И конечно же, никто не хочет чтоб система умерла за два шага до получения конечного ответа, поэтому вопрос надежности встанет особенно остро. Точно так же обстоит дело с многопоточными кластерами. Вот и получается, что кластерные системы могут относиться к этим типам лишь в большей или меньшей степени. Потому что при создании в каждой кластерной системе будут устройства, относящиеся ко всем функциональным типам.
Для параллельных вычислений (как было сказано выше) используют высокопроизводительные системы. Такие кластеры собирают из большого числа компьютеров. Создание подобного кластера очень сложный процесс. На каждом следующем шаге необходимо не только подключить очередной узел, но использовать и управлять всеми, подключенными ранее. Проще всего это делать, когда на всех узлах одна операционная система (это позволяет избегать конфликтов между разными операционными системами). Реализовать такую схему можно только для сравнительно небольших систем.
Применение многопоточной архитектуры рационально в том случае, когда необходимо обеспечить одинаковый доступ к ресурсам. Такие системы можно произвольно наращивать.
Впервые, как это бывает со всеми компьютерными технологиями, создать кластер попробовали на оборонном объекте в США. В 1994 году был создан 16-ти узловой кластер. На его основе сейчас строятся практически все кластеры. Значительно сократить расходы на этот кластер позволило то, что под него практически не разрабатывалось программное обеспечение. А большинство использованных программ были из разряда free ware (свободное распространение). Практика бесплатного программного обеспечения с успехом применяется до сих пор.
Слабым звеном в кластере может стать его архитектура (способ соединения процессоров друг с другом). Существенным является такой параметр, как расстояние между процессорами. Именно из-за влияния этого показателя при увеличении числа процессоров в N раз, производительность в N раз не возрастет (при условии, что система идеальна). Предположим, что у нас есть 16 равноправных процессоров. Первое, что приходит на ум после линейного соединение (одномерное), это соединить их в решетку (двумерное) чтобы получить схему на рис. 3.5.
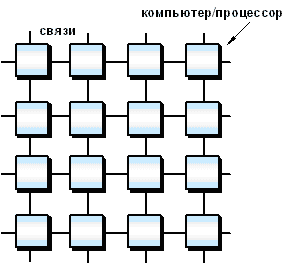
Рис. 3.5. Топология связи, сетка 4х4 [9]
Максимальное расстояние между процессорами равно 6 (количество связей между процессорами, разделяющих самые удаленные процессоры). Как правило, при расстоянии большим 4 система не может функционировать оптимально. Таким образом, двумерная схема тоже не эффективна. Что же остается? Нужна фигура, которая имеет максимальный объем при минимальной площади поверхности. Таковым является шар, но построить узловую структуру в форме шара затруднительно. Приходится строить систему в виде куба, а точнее гиперкуба (при числе процессоров больше 8). Размерность гиперкуба определяется числом процессоров, входящих в кластер. В нашем случае, при использовании 16 процессоров, используется 4-х мерный куб. Получить его можно из обычного куба путем его смещения еще в одном направлении, затем соединить вершины (рис. 3.6, 3.7).
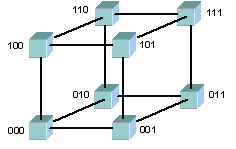
Рис. 3.6. Топология 3-х мерный куб [9]
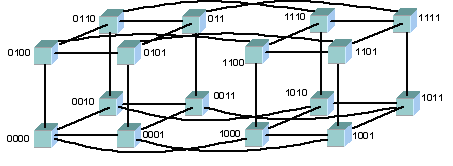
Рис. 3.7. Топология 4-хмерный куб [9]
Гиперкубы (являются второй по эффективности архитектурой, однако ее проще всего представить. Помимо гиперкубов можно встретить трехмерный тор, «кольцо», «звезда» (рис. 3.8) и т.д.
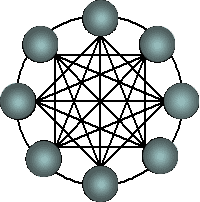
Рис. 3.8. Архитектура кольца с полной связью по хордам (Chordal ring) [9]
Одной из самых эффективных является архитектура «толстого дерева» (Fat Tree, рис. 3.9-3.10). Ее предложил Лейзерсон в 1985 году. Внутренние узлы скомпонованы в сеть, а процессоры локализованы в деревьях. Общение поддеревьев между собой происходит без обращения к более высоким уровням сети.
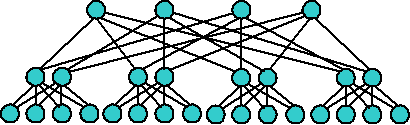
Рис. 3.9. Архитектура Fat Tree [9]
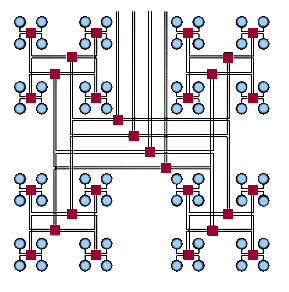
Рис. 3.10 Архитектура Fat Tree (вид сверху) [9]
Так как архитектура, в которую соединен кластер, оказывает большее влияние на производительность, чем тип процессоров, то возможно наиболее дешевым вариантом будет создание кластера из большего числа дешевых компьютеров, а не из меньшего числа дорогих. Поддерживать работу кластера можно при помощи бесплатного программного обеспечения, найти которое сейчас не составляет большого труда. Создание такой системы обходится не так уж дорого, но в таких системах велики накладные расходы на взаимодействие параллельных процессов между собой. Последний фактор значительно уменьшает количество потенциально решаемых задач.