

2.4.Требования к памяти высокопроизводительных эвм
Исходя из задач, решаемых суперЭВМ, требования к памяти не только выше, чем у обычных ЭВМ, но их еще и больше. Т.к. приложения для высокопроизводительных ЭВМ должны работать с большим количеством данных, охватывать большой объем ресурсов, обработка происходит длительное время (это связано с длительным циклом обработки), то память должна отвечать следующим критериям:
Иметь максимальный объем памяти.
Обеспечивать возможность асинхронного ввода-вывода.
Иметь возможность организовать массивное хранилище данных.
Обеспечивать высокоскоростной ввод-вывод.
Иметь возможность передачи данных удаленным системам.
Преобразовывать данные для различных технических средств.
2.5.Коммуникационная сеть высокопроизводительных эвм
Одним из важнейших элементов архитектуры высокопроизводительных ЭВМ является коммуникационная сеть. Благодаря ей можно связать процессоры между собой, с памятью и другими устройствами. Существуют две основные топологии сетей – статические и динамические.
Как только к сетевым устройствам был добавлен переключатель, появилась возможность организовывать многокаскадные сети.
2.5.1.Статические и динамические топологии и маршрутизация коммуникационных систем
Основным отличием статических топологий от динамических является то, что все соединения в такой сети фиксированы. У динамических топологий в межпроцессорных соединениях используются переключатели. Говоря о топологиях вообще (о локальных сетях) можно выделить следующие (см. рис.2.3.):
Шина (1) – обмен происходит через единственную шину. Она, как правило становится узким местом.
Звезда(2) – обмен информацией идет через концентратор.
Кольцо(3) – информация запускается в кольцо и циркулирует по нему до тех пор, пока не придет к нужному адресату (сигнал идет в одном направлении).
Многокаскадные и многосвязные сети (они являются комбинацией предыдущих).
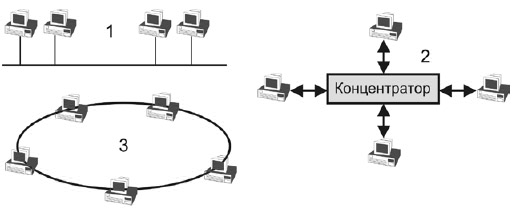
Рис. 2.3. Сетевые топологии [7]
Рассмотрим случай, когда узлы соединены в по схеме на рис.2.3. Для выбора маршрута передачи данных необходимо выполнить смещение по оси X, затем –Y и в конце – Z. Сетевые маршрутизаторы (аппаратное устройство, находящееся в месте соединения коммуникационных линий, направляющее пакет данных) должны определять путь перемещения пакета данных. Для удобства, каждому узлу присваивают уникальный физический номер, который определяет его положение. Вполне возможен случай, что несколько узлов будут держаться в резерве (так было сделано с компьютером CRAY T3D).
2.5.2.Многокаскадные сети и методы коммутации
Основой многокаскадных систем (возможные соединения показаны на рис. 2.4, 2.5), как было сказано ранее, являются переключатели (коммутаторы). Они помещаются между процессорами или другими узлами. При передаче информации переключатели устанавливаются таким образом, чтобы получилось необходимое соединение. В принципе, возможен вариант, когда один из маршрутов заблокирует все остальные маршруты. Это может иметь неблагоприятные последствия, но иногда такую возможность вносят специально. Чтобы связать все элементы между собой, необходимо построить матричный коммутатор (например, использовать топологию «звезда»). При такой реализации любой из процессоров может обратиться к любому модулю памяти. Может возникнуть конфликт, когда несколько процессоров обратятся к одному модулю памяти (вот тут на помощь может прийти система блокировки). При расширении сети ощутимо возрастает число переключателей. Очевидно, что для системы из N процессоров и N модулей памяти необходимо 2N переключателей.
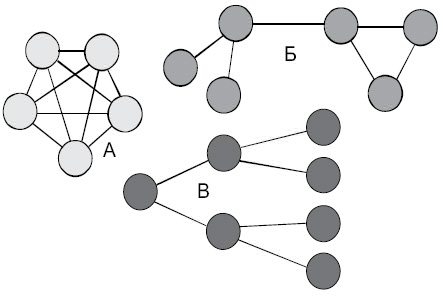
Рис. 2.4. Возможные связи в коммуникационных сетях.
А – каждый узел соединен с каждым, Б – смешанная система,
В – иерархическая система связи [7]
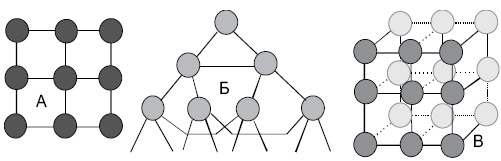
Рис. 2.5. Возможные топологии в современных вычислительных системах.
А – решетка, Б – гипердерево, В – куб [7]