

3.6.Особенности параллельного программирования
При написании программы под параллельную обработку возникает ряд проблем, которые, мягко говоря, неочевидны. Далее описаны возможные варианты уменьшения такого рода ошибок.
Итак, ваша программа работает в обычном режиме, вдруг она вылетает с ошибкой, что произошло несвоевременное обращение к оперативной памяти по какому-то невоспроизводимому адресу. А в чем же собственно проблема? Для этого представим, что наша программа обрабатывает много разных величин, по большому количеству формул, но, мало того, обрабатываемые величины связаны между собой. При классическом подходе к параллельному программированию всю программу разложить на несколько процессоров мы должны вручную. Очень показателен рис. 3.11.
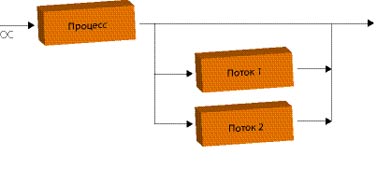
Рис.3.11. Распараллеливание одного процесса на несколько потоков [10]
На рисунке все это выглядит очень просто. На самом деле материнский поток при помощи различных вызовов должен сформировать несколько новых потоков (например, в Unix-системах после порождения новых потоков основной процесс приостанавливается ОС, а в ОС возникает два объекта – новый поток, запущенный по команде материнского, и последующий, продолжающий работу главного, но не являющийся собственно процессом). Вместо
…
Выполнить Действие1();
Выполнить Действие2();
…
Мы получим:
…
Запустить Поток (Действие1);
Запустить Поток (Действие2);
…
Т.е. обсчет объектов происходит одновременно. На самом деле, чаще встречается конструкция Запустить Поток (действие для Объекта1); Запустить Поток (действие для Объекта2), т.к. проделывается много однотипных операций над несколькими объектами.
Но такая организация может свести на нет все преимущества параллельного кода. Это связано с тем, что запуск нового потока и переключение между потоками (если процессоры не могут обработать все потоки одновременно) очень дорогие операции. Тогда пользуются следующим решением. Запускают необходимые (именно необходимые, тщательно подобранные по количеству, чтобы не было лишних переключений) потоки заранее, а после, главный поток в указанных местах передает текущее задание этим потокам. В результате получаем код вида:
…
Запустить Поток(Поток1);
Запустить Поток(Поток2);
…
Отправить на Обработку Потоку(Поток1, Действие над Объектом1);
Отправить на Обработку Потоку(Поток2, Действие над Объектом2);
…
В такой ситуации уже на этапе разработки нужно оперировать очень громоздкими и сложными конструкциями. Во-первых, их очень сложно написать. Во-вторых, их еще сложнее отладить.
На помощь может прийти такой компилятор как OpenMP. Это достаточно универсальное средство. OpenMP не привязывается к особенностям ОС. В случае непонимания другими компиляторами его можно просто игнорировать. Недостатком является очень жесткая модель программирования. В основе OpenMP лежит идея использования специальных компиляторов, ориентированных на параллельное программирование. В коде программы вставляются специальные метки, которые указывают какую часть кода выполнять последовательно, а какую параллельно. В итоге код программы приобретает следующий вид (рис. 3.12):
…
#Выполнить Код Параллельно
Действие1;
…
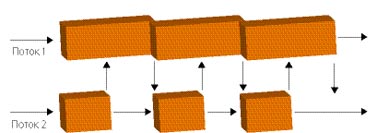
Рис.3.12. Пример работы программы [10]
Но OpenMP не поможет при таких проблемах, как, например, балансировка загрузки потоков. Вполне возможны ситуации, когда два из трех потоков справятся со своей задачей гораздо раньше, чем третий, и будут простаивать, ожидая его результаты. Вот и получается, что если 80% кода можно распараллелить, а 20% - нет. То получить прирост в производительности при подключении второго ядра более чем в 40% не получится. И это только процессор, а если взять такие ресурсы как оперативная память, которые вообще разделить нельзя, то ускорить программу относительно одноядерного процессора на двуядерном в два раза вряд ли удастся.
Возвращаясь от аппаратной части к программной, обратим внимание еще на один момент. Допустим, у нас есть одна величина, которую используют два потока. Первый поток изменяет ее, но в этот же момент в другом потоке она тоже должна быть изменена. Что же получим на выходе? Все зависит от того, какой из потоков запишет в память последним «верное» значение. А представим себе, что один из потоков удалил нашу злосчастную величину, сократив на нее что-нибудь другое (или сделав любую другую операцию, приводящую к стиранию объекта из памяти). Как в такой ситуации должен вести себя другой поток, который объект обсчитал и хочет внести изменения, а вносить некуда, объект удален. Конечно же, громко заявить об ошибке, попутно убив всю программу.
Разрешить такого рода недоразумения помогают объекты синхронизации. Они позволяют временно заблокировать изменение одного из объектов, которые могут быть использованы двумя потоками одновременно (рис. 3.13). Т.е. отдаем объект в пользование одному из потоков, а всех остальных претендентов на него ставим в очередь. Если этого не сделать, то, как было сказано ранее, программа может обрушиться. Причем обрушиться она может не в момент конфликта, а через некоторое время, когда «неудачный» код уже не отловить. Причем смерть программы может быть каждый раз в другом месте и в другое время.
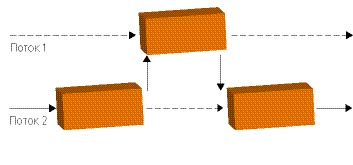
Рис. 3.13. Взаимодействие потоков [10]
Как мы выяснили в предыдущем абзаце, мало объектов синхронизации – программа сломается. Но кто бы мог подумать, что большое количество объектов синхронизации тоже приведет к краху нашей бедной программы? А связано это вот с чем. Пусть у нас есть какой-нибудь объект, который хотят заполучить все потоки. Т.к. всем потокам сразу принадлежать объект не может, то он отдается одному из них. Остальные терпеливо выстраиваются в очередь. И что же тогда останется от параллельности в таком коде? Тогда мы выдаем блокировку только на время, в течение которого будет происходить расчет. Вот мы и подошли к очередной проблеме. Нам необходимо изменить состояние двух объектов. Нам удалось просчитать как оно изменится, нам даже удалось изменить первый объект. Но при подходе ко второму объекту программа зависла. Почему? Потому что второй объект заблокирован, потому что он должен внести изменения в первый объект. Блокировку на себя он не отдаст, пока не изменит тот самый первый объект, обрабатываемый основным кодом. Вот так и будет стоять программа, потому что заблокированы все необходимые объекты. Или вот подобная ситуация. Первый поток заблокировал объект, обработал, и забыл снять блокировку. После этого другому потоку понадобилось проверить состояние объекта, он натыкается на блокировку и отказывается работать дальше. Поэтому важно помнить, что никогда не стоит пытаться обладать двумя объектами одновременно. А также, очень важно всегда проверять, что все однажды взятые объекты своевременно разблокированы.
Одной из проблем при отладке параллельного кода, является то, что один шаг процесса может сопровождаться десятками шагов другого процесса. Ситуации, возникающие в таких шагах зачастую уникальны. Они связаны со случайным совпадением в слабосвязанных между собой потоков. Такие проблемы могут больше никогда не появится в программе. И, как это бывает во всех измерениях, наличие наблюдателей (отладочных средств) вносит коррективы в результат, т.к. немного изменяет внешнюю среду.
Несмотря на все проблемы, связанные с параллельным программированием, отказаться от многоядерных процессоров не удастся. Тем более, что все производители процессоров заваливают нас недорогими продуктами. Скоро параллельное программирование станет таким же обычным, каким сейчас стало непараллельное.