

66. Текстурирование объектов
Операции наложения текстур на грани моделируемых объектов являются одной из наиболее часто встречаемых операций визуализации 3D-сцен. Алгоритмы наложения текcтур можно классифицировать в зависимости от:
1) вида граней;
2) ориентации граней на экране.
В зависимости от вида граней различают:
1) алгоритмы, ориентированные на текстуризацию полигональных сеток;
2) алгоритмы, ориентированные на текстуризацию сложных поверхностей.
В зависимости от ориентации граней различают алгоритмы, предназначенные для:
1) текстуризации вертикальных граней;
2) текстуризации горизонтальных граней;
3) текстуризации произвольно ориентированных граней.
Первые два вида алгоритмов текстуризации широко используются в программах 2,5D-моделирования. Работа этих алгоритмов основывается на выделении в базовой текстуре вертикальных или горизонтальных линий и отображение их на грани с учетом масштабного коэффициента, учитывающего расстояние до объекта. В случае произвольной ориентации плоских граней алгоритм наложения текстура значительно усложняется. Рассмотрим отдельную плоскую грань, расположенную в 3D-пространстве, с гранью связана своя собственная система координат, определяющая положение каждой точки текстуры на этой грани.

На практике используются нормированные координаты грани, то есть U и V лежат в пределах [0;1]. Чтобы получить индексы для отображаемой текстуры следует произвести элементарные преобразования координат. Конец 66 вопроса.
67.Классификация методов сжатия графической информации.
Графическая информация, как и большинство видов информации,несёт в себе избыточность. Поскольку объемы современной графической информации имеют значительные размеры, то при ее сохранении, эту избыточность желательно устранить. Для устранения избыточности существуют специальные методы, которые делятся на две группы:
• методы упаковки;
• методы сжатия.
Методы упаковки не устраняют информацию избыточности, а устраняют из потока пустые фрагменты (не несущие полезной информации).
Методы сжатия ориентированы на сведение информации избыточности к минимуму. Эти методы делятся на:
- методы сжатия с потерями;
- методы сжатия без потерь.
К методам упаковки и сжатия без потерь относятся следующие группы алгоритмов:
1) упаковка пикселей;
2) групповое кодирование;
3) методы, базирующиеся на словаре;
4) методы, базирующиеся на кодировании строк бит переменной длины.
К методам сжатия с потерями относятся:
1) JPEG-сжатие;
2) волновое сжатие (вейвлет-сжатие);
3) фрактальное сжатие.
Конец 67 вопроса.
68.Метод группового кодирования (rle-алгоритм).
Алгоритмы данного семейства выделяют в потоке данных (в изображении) группы однородных элементов (байтов, пикселей) и выполняет замену этих групп парой чисел, одно из которых определяет значения повторяющихся элементов (цветовые характеристики байтов, пикселей), а другое – количество элементов в этой группе. В том случае, если в изображении в достаточном количестве присутствуют группы однородных элементов, происходит существенное сокращение объёмов информации. К сожаленью, в компьютерной графике подобные алгоритмы эффективно работают при малой цветности изображений - до 256 цветов (т.е. до 8 бит/пиксель).Эти алгоритмы в англоязычной литературе называются RLEалгоритмами (Run Length Encoding). RLE -алгоритмы классифицируются:
- по выделению кодируемых строк;
- по выделению кодируемых элементов.
По выделению кодируемых строк RLE -алгоритмы делятся на четыре группы:
а) ориентированные на горизонтальные строки;
б) ориентированные на вертикальные строки;
в) ориентированные на блочную упаковку;
г) ориентированные на змеевидные строки.
При этом варианты а и б просты для реализации. Однако имеют существенный недостаток - не учитывается двумерный характер графической информации. В вариантах в и г недостаток устранен.
Входные данные рассматриваются RLE-алгоритмом как одномерный поток. При этом в большинстве алгоритмов последовательность пикселей потока данных соответствует последовательности обхода экрану лучом сканирования: слева направо и сверху вниз. Однако существуют такие вариант RLE-алгоритмов, которые позволяют формировать последовательность пикселей в ином порядке (например, обход столбцов пикселей сверху вниз или зигзагом - от верхнего левого угла к правому нижнему). Подобные варианты RLE позволяют в отдельных случаях повышать степень сжатия данных, но на практике
применяются довольно редко.
По выделению кодируемых элементов RLE -алгоритмы делятся на:
а) бит–ориентированные;
б) байт–ориентированные;
в) пиксельно–ориентированные.
Вариант «а» целесообразно использовать только для монохром-
ных изображений. Вариант «б» наиболее универсален, т.к. он не зависит ни от формата машинного слова, ни от формата пикселя. Вариант «в» использует в качестве элементов потока двух, трех и четырех байтные пиксели.
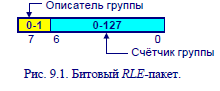
Бит-ориентированные RLE-алгоритмы. RLE-алгоритмы данного вида выделяют группы одинаковых битов, игнорируя при этом границы байтов и слов. Этот вид алгоритмов эффективен только при обработке монохромных, или чёрно-белых, изображений (1 бит/пиксель).RLE-алгоритм битового уровня объединяет в группы от 1 до 128 битов,
создавая из них однобайтовые пакеты. Семь младших битов этого байта содержат счётчик группы (количество битов минус единица), а самый старший бит – описатель группы (рис.9.1). Группы длиной более 128 пикселей необходимо делить на несколько RLE-пакетов.
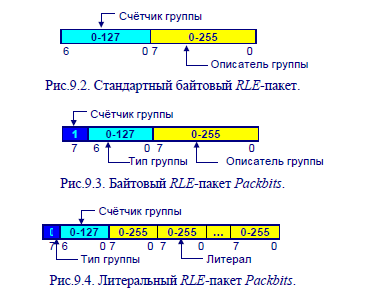
Байт-ориентированные RLE-алгоритмы. RLE-алгоритмы байтового уровня являются наиболее распространенными и объединяют в RLE-группы одинаковые байты. При этом каждая RLE-группа заменяется двухбайтовым RLE-пакетом. Первый байт содержит счётчик группы (от 0 до 255), а второй – описатель (рис.9.2). Кроме того, часто
применяется схема двухбайтового кодирования, позволяющая хранить в потоке закодированных данных литералы - группы неповторяющихся байтов (такой подход применен в одном из самых распространенных вариантов RLE-алгоритма - Packbits). При этом семь младших битов первого байта содержат счётчик группы (количество байтов в группе минус единица), а самый старший бит первого байта указывает тип
группы (RLE-группа или литерал). Если самый старший бит установлен в «1», то он определяет RLE-группу. RLE-группа восстанавливается по байту-описателю, повторяя его столько раз, сколько определяет счётчик группы (рис.9.3). Если же самый старший бит установлен в 0, то он определяет литерал. При этом следующие байты (в количестве, указанном счётчиком группы плюс единица) должны читаться напрямую из закодированных данных изображения. В этом случае байт счётчика группы содержит значения в диапазоне от 0 до 127 (количество байтов в группе минус единица). Смотрите рисунок. RLE-схемы байтового уровня эффективны для данных изображения, которые хранятся в виде одного байта на пиксель.
Пиксельные RLE-алгоритмы. RLE-алгоритмы пиксельного уровня используют в качестве элемента входного потока пиксели размером два, три или четыре байта. Сведения о размере пикселей хранятся, как правило, в заголовке растрового файла. На рис.9.5 приведен пример с трехбайтовым пикселем.

Кроме того, варианты RLE-алгоритмов могут отличаться для различных форматов
Конец 68 вопроса.