

35589645
.pdfРОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
f(x) = 0,91x + 0,1 R2 = 0,99
Точки: x = Tk , y = ln(1/P{t > Tk})
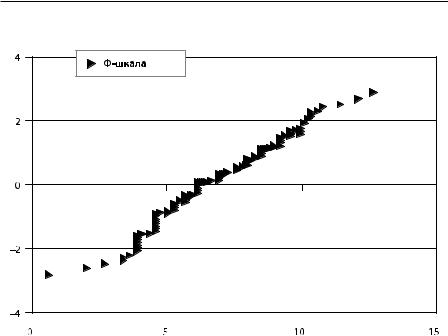
Рис. 1.6.2. Экспериментальные точки для построения регрессии и наилучшая прямая
А теперь мы вспомним, что в экспоненциальной модели значение λ в точности равно числу событий за единицу времени, в которых измеряется Т, так
что его мы можем принять за среднее число взяток в год, приходящееся на
одного респондента из числа дающих взятки. На рис. 1.6.2 мы видим, что экспериментальные точки располагаются явно нелинейно, выпукло вверх, так что эта оценка несколько занижена.
Средний размер взятки. Прежде, чем приводить формулу для вычисления bср , мы предлагаем посмотреть на распределение логарифмов взяток на «нормальной бумаге», рис. 1.6.3. Мы видим, что 3–5 наименьших и 3–5 наибольших значений выбиваются из общей линейной закономерности, которая хорошо прослеживается на рисунке. Подобного рода характер распределения размеров взяток является вполне обычным, что позволяет рекомендовать робастную оценку среднего значения взяток. Для этого берем из массива данных В числа b1, b2, …, bH , изымаем 5 наименьших и 5 наибольших значений, после чего вычисляем обычное среднее. Для данных из проекта «Татарстан-2004» bср
= 2849,2 рублей.
Объем рынка коррупции. Это суммарные траты граждан на взятки (подарки, подношения, другие услуги). Будем считать, что наша выборка является представительной для всей изучаемой страты населения. В нашем случае опрос проводится среди всего «взрослого» населения (для проекта «Татарстан-2004» — население региона, для проекта «Диагностика российской
190
ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Ось X — логарифмы взяток
Рис. 1.6.3. По оси Х отложены логарифмы взяток, а по оси Y — значения квантильной функции нормального распределения (от нормированного ранга взятки в общем ряду).
коррупции – 2005» — население всей РФ), которое составляет Q% от населения в целом, которое составляет Р тыс. человек. Предположим еще, что за текущий год в среднем на одного «взрослого» было осуществлено μ взяток, а средняя величина взятки составила b рублей. В таком случае объем рынка коррупции вычисляется по простой формуле:
М= 0,01 · Р · Q· μ · b (тыс. рублей). |
(1.6.4) |
В нашем случае числа Р и Q устанавливаются достаточно надежно по данным переписи населения (для Татарстана они приводятся в таблице 1.6.1). Алгоритм вычисления размера средней взятки b= bср был только что описан. Осталось лишь связать значение μ (интенсивность взяток в среднем за год на одного гражданина среди всех представителей изучаемой страты) с интенсивностью взяток λ среди «дающих взятки». Чисто формальная связь между этими двумя характеристиками очень проста:
μ· Т = λ · K
191

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
поскольку и левая, и правая часть равенства представляют одно и то же — число взяток за год, приходящееся на всю выборку респондентов. Сложность же использования этой связи для вычисления μ в том, что число дающих взятку респондентов всегда занижено, часть опрашиваемых «смущается» и уходит от прямых ответов. Мы в своих анкетах всегда стараемся дать серию дополнительных вопросов, позволяющих в той или иной степень оценить процент «стеснительных» граждан. Вычисленные таким образом оценки показывают (статистика пока невелика — три проекта, в которых эти расчеты удалось провести), что К должно быть примерно в полтора раза больше, чем вычисленное
вопросе.
Витоге для объема рынка бытовой коррупции предлагается следующая формула:
М = 0,015 · K · Q· P· λ· b тыс. рублей. |
(1.6.5) |
N |
ср |
|
Для Татарстана Р = 3785 тыс. человек, Q = 78,8 и N = 2405, так что
М= 0,015· (604/2405)· 78,8· 3785· 1,0791· 2849,2 = 3454537 тыс. рублей.
Всвязи с формулой (1.6.5) необходимо сделать еще несколько замечаний.
Во-первых, надо иметь в виду, что всегда bср меньше обычного среднего, причем, существенно. Далее, оценка интенсивности λ практически всегда занижена, хотя это лишь наблюдаемый факт, а не теоретический результат. Вследствие этого увеличение коэффициента 0,01 из (1.6.4) в полтора раза взят как компен-
сация потерь в произведении K· λ · bср трех величин, являющихся множителем
в (1.6.5). Наконец, надо сказать, что во всех тех случаях, когда мы можем из дополнительных вопросов достаточно надежно скорректировать число «дающих взятки» К и заменить его на К*, то нужно использовать формулу:
М = 0,01 · (K*/N)· Q· P· λ · bср тыс. рублей. |
(1.6.5*) |
Анализ рынка по сегментам. Сегменты рынка, то есть элементы разбиения респондентов на группы по некоторому дополнительному вопросу (мы его обозначали V9), порождают некоторые подвыборки. Для каждой такой подвыборки мы можем снова задаться проблемой вычисления характеристик рынка коррупции. С формальной точки зрения такая проблема для отдельной подвыборки ничем не отличается от уже разобранной для всей выборки в целом. Однако на практике все оказывается намного сложнее.
Это прежде всего потому, что размеры подвыборок могут оказаться слишком малы для того, чтобы хоть сколько-нибудь надежно оценить основные
192

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
характеристики соответствующих рынков коррупции (средний размер взяток, интенсивность взяток). В силу этого имеются важные изменения в расчетах:
1.Всякий раз, когда из-за количества имеющихся данных оказывается статистически некорректно вычислять ту или иную характеристику, вместо ее значения предлагается выдавать символьное значение #Н/Д.
2.Ранее для вычисления среднего размера взятки было рекомендовано робастное среднее. Однако конкретная процедура с отбрасыванием 5-ти наибольших и 5-ти наименьших значений пригодна лишь для больших выборок, а для сегментов она должна быть скорректирована.
3.Мы не всегда имеем данные о реальном распределении граждан по сегментам коррупционного рынка (разбиение по атрибутам, содержащимся в вопросе). А поэтому единственное, что мы можем сделать, — это в качестве «истинного» распределения взять то, что наблюдается на нашей
выборке респондентов.
Эти коррекции и содержатся в алгоритмическом изложении методики вычисления основных характеристик рынка коррупции в пределах отдельных сегментов. Нижеследующий текст мы, в основном, не снабжаем подробными комментариями (пусть формулы говорят сами за себя).
Рассмотрим сначала разбиение изучаемой социальной группы по тем проблемам, с которыми «идут к чиновнику» люди. Создадим для этого массив
V = {V10(n); 1 ≤ n≤ N}, где V10(n) =V2(n), если V3(n) = 1, V10(n) =V6(n), если
V4(n) = 1, и V10(n) =#Н/Д во всех остальных случаях. Используя массив V, мы
разобьем всю выборку респондентов на L + 1 группу. Точнее, мы соберем мас-
сивы номеров G(0V) и G(fV), 1 ≤ f ≤ L (в наших опросах L = 17, но для общности мы все формулы приводим для произвольного L > 1). Номер респондента n попа-
дает в массив G(fV), если V10(n) =f  {1; 2; …; 17}, и n попадает в массив G(0V), если значением V10(n) является символ #Н/Д.
{1; 2; …; 17}, и n попадает в массив G(0V), если значением V10(n) является символ #Н/Д.
Для каждой «проблемы» f  {1; 2; …; L} (закрытия вопроса V2) мы собираем следующие рабочие массивы: Tf = {t(n); n
{1; 2; …; L} (закрытия вопроса V2) мы собираем следующие рабочие массивы: Tf = {t(n); n G(fV)}, Af = {a(n); n
G(fV)}, Af = {a(n); n G(fV)} и Rf= {R(n); n
G(fV)} и Rf= {R(n); n G(fV)}. Эти данные удобно представить в виде таблицы:
G(fV)}. Эти данные удобно представить в виде таблицы:
№ п/п |
t |
a |
R |
|
|
|
|
1 |
t[1] |
a[1] |
R[1] |
2 |
t[2] |
s[2] |
R[2] |
- - - - - - |
- - - - |
- - - - |
- - - - |
|
|
|
|
N(f) |
t[N(f)] |
s[N(f)] |
R[N(f)] |
|
|
|
|
где N(f) — число респондентов из группы G(fV).
193

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
1. Если N(f) ≥ 5, то вычисляются
N(f)
N(wf) = I{t[k] = w + 1; a[k] = 1}, w = 0, 1, 2, 3 и 4,
k=1
где I{G} равно 1, если G — «истинна», и равно 0, если G — «ложь».
После этого проверяется неравенство N(4f) ≥ 2 и, при выполнении этого условия, подсчитываются частоты h(wf) для w= 1, 2, 3 и 4 по (1) с заменой Nw на N(wf) и K на K(f), равного сумме всех N(wf) , w= 0,1, 2, 3 и 4, и по формуле (3) с рассчитанными частотами вычисляется интенсивность λ(f). Если же N(4f) < 2, то полагается λ( f ) = #Н/Д.
Средний размер взяток bср( f ) в этом секторе отношений определяется при
условии, что N( f ) ≥ 5 и K( f ) ≥ 3, иначе bср( f )= #Н/Д. Сначала из массива Rf в отдельную выборку Bf собираются те R[k], которые являются положительны-
ми числами. Ее размер обозначим Н( f ) ≤ К( f ). Далее, если Н( f ) ≥ 7, то из нее изымаются максимальное и минимальное значения, и подсчитывается обычное среднее оставшихся чисел. Если 3 ≤ Н( f ) <7, то среднее значение вычис-
ляется по всей выборке . Если же Н( f ) < 3, то bср( f )= #Н/Д.
Если λ( f ) и bср( f ) определены, то объем рынка коррупции в этом сегменте
рынка вычисляется по формуле: |
|
|
||
М( f ) = 0,015 · |
K( f ) |
· Q · P · λ· bср( f) тысяч рублей. |
(1.6.6) |
|
N |
||||
|
|
|
||
Если же значением λ( f ) или (и) bср( f ) является символ #Н/Д, то из-за неопределенности значение M( f ) заменяется символом #Н/Д.
2. Если условие N( f ) ≥ 5 нарушается, то расчеты не проводятся, и вместо чисел λ( f ), bср( f ) и M( f ) проставляется символ #Н/Д.
Комментарий. Даже при допустимости всех расчетов в силу нелинейных способов оценки величин λ( f ) и M( f ) гипотетическое равенство
M(1) + M(2) + … + M(L) М* = M,
вообще говоря, не выполняется и не должно выполняться. Собственно, М и М* являются разными оценками одной и той же неизвестной величины — объема рынка коррупции, но оценка М статистически намного надежнее, чем М*.
Дополнительный вопрос
Вопрос V9, если он присутствует, позволяет разделить всех респондентов на S+ 1 группу. В группу G(0V9) мы соберем номера тех респондентов, которые не
194

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
дали ответ на вопрос V9, то есть n G(0V9) , если V9(n) = #Н/Д, и n
G(0V9) , если V9(n) = #Н/Д, и n G(dV9) , если
G(dV9) , если
V9(n) = d, 1 ≤ d≤ S.
После этого мы обрабатываем данные по сегментам G(dV9) для d = 1, 2, …, S точно по тем же процедурам, что и группы G(fV) для f =1, 2, …, L с абсолютно аналогичными условиями N(4d) ≥ 2, N(d) ≥ 5 и K(d) ≥ 3 при принятии решений о вычислении величин λ(d), bср(d) и M(d) .
ХАРАКТЕРИСТИКИ РЫНКА ДЕЛОВОЙ КОРРУПЦИИ
Концептуально анализ рынка деловой коррупции почти не отличается от анализа рынка бытовой коррупции. Различия — в нюансах, но они порой крайне существенны. Общая формула для объема ранка практически та же самая:
M= 0,001 × γ× λ×P× bср (миллионы рублей), |
(1.6.7) |
где γ — скорректированная доля дающих взятки, λ — интенсивность взяток
(среднее число взяток, даваемых в течении года), Р — общее число предприятий в изучаемом регионе (или во всей РФ, или в некотором секторе экономики) и bср — размер взятки (средний размер одной взятки, тыс. рублей).
Вообще говоря, нашими респондентами являются предприниматели, а не предприятия, но формирование выборки респондентов таково, что мы можем
считать, что разные респонденты (предприниматели) представляют разные
предприятия (фирмы, банки, акционерные общества и тому подобное). Этот факт позволяет рассматривать наших респондентов не только как предпринимателей, но и как «предприятия», которые они представляют.
Совокупность вопросов V1–V4, задаваемых предпринимателем для оценки характеристик рынка деловой коррупции, уже была приведена, но так же как и в случае опроса граждан нас может интересовать соотношение рынков коррупции при разбиении всей сферы бизнеса на небольшое число «направлений». Для этого обычно используется некий дополнительный вопрос V5 (или новая переменная, сформированная по ответам на некоторую серию вопросов, и которую снова можно считать дополнительный вопросом).
Мы считаем, что на вопрос V5 предлагается выбрать только один вариант ответа из предложенного списка с S вариантами, кодируемыми числами 1, 2, …, S. Отсутствие ответа, как всегда, кодируется символом #Н/Д.
Приведем таблицу входных параметров, которые используются при расчетах. В качестве примера используется опрос «Бизнес-2005».
195
РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Таблица 1.6.5. Входные параметры
Входные параметры |
Символ |
Примечания |
Татарстан-2004 |
|
|
|
|
Число респондентов |
N |
желательно > 500 |
1030 |
|
|
|
|
Наличие вопроса V4 |
β |
1 — есть, 0 — нет |
1 |
Наличие вопроса V5 |
θ |
1 — есть, 0 — нет |
1 |
Число закрытий в V5 |
S |
не более 10 |
- - - - - - |
Число малых предприятий |
Q |
Штук (Госкомстат) |
900000 |
|
|
|
|
Число фирм на изучаемой территории |
P |
Зарегистрировано штук |
#Н/Д |
Перед тем как перейти к изложению методики анализа рынка, надо сделать несколько замечаний об измерителях в анкетных вопросах. Дело в том, что величина оборота в вопросе V1 может спрашиваться не в тыс. рублей, в других единицах, например, в рублях. Далее, закрытия вопроса V2 могут, вообще говоря, содержать другие интервалы времени, например, будет использоваться неделя вместо десяти дней. Подобные изменения в вопросах должны отслеживаться, и должна производиться соответствующая корректировка в предлагаемых ниже формулах.
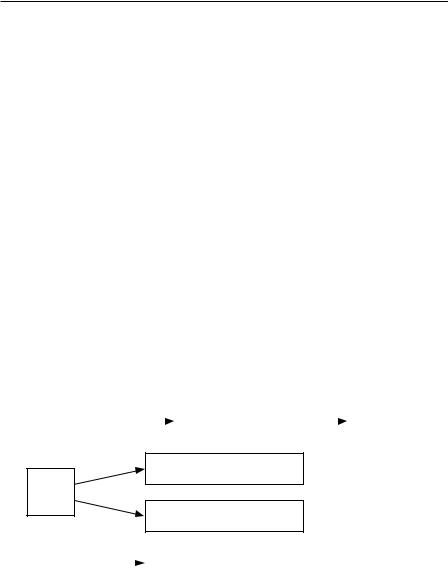
Расчеты для рынка деловой коррупции можно представить в виде следующей схемы:
(V1; V3) |
|
|
Массив взяток R |
|
|
Размер взятки |
|
|
|
|
|||
|
|
|
|
|
|
|
Интенсивность λ
V2
Доля дающих взятки γ
V4 |
|
|
Размер страты (число фирм) P |
|
|
||
|
|
|
|
Рис. 1.6.4. Схема расчета: что вычисляется и по ответам на какие вопросы
Используя массивы данных из опроса, на выходе выдают следующие базовые характеристики рынка (числовые значения приведены для исследования «Бизнес-2005»):
196
ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
1.Охват коррупции — это процент предпринимателей, которые используют взятку для решения проблем ведения своего бизнеса, d 62,5.
2.Интенсивность коррупции — оценка среднего числа взяток за 1 год среди предпринимателей, дающих взятки, λ 1,8.
3.Средний размер взятки за год (среди дающих взятки) bср 3911 тыс. рублей.
4.Среднегодовой рынок коррупции, М 9,1 трлн рублей.
Везде ниже (как и в случае рынка бытовой коррупции) обозначения V1(n), V2(n), V3(n), V4(n), V5(n) используются для кодировки ответов n-го респондента на вопросы V1, V2, V3, V4, V5 соответственно. Всего в выборке имеется N респондентов. Наконец, мы будем считать, что в исходных данных уже произведена необходимая перекодировка: все отказы от ответа или другие случаи потери информации (нет данных) кодируются символом #Н/Д.
И последнее вводное замечание: величина d (охват коррупции), вообще говоря, не совпадает с γ (скорректированная доля дающих взятки), если ее
измерять, как и d, в процентах. Естественно, что коррекция d проводится в сторону увеличения, поскольку основной «нечестностью» в ответах респондентов является умолчание о даче взяток. Это особенно серьезно для предпринимателей. Так же, как и в случае граждан, мы предлагаем «волевую» коррекцию, основанную на опыте и экспертных оценках, в форме
γ= 100d + 12 ·(1– 100d ). Конечно же, если по тем или иным вспомогательным
вопросам удается провести содержательно обоснованную коррекцию, то
именно ее и надо использовать в качестве γ.
Интенсивность. Определим числа
Nw = N I{V2(n) = w+ 1}, w = 0,1, 2, 3 и 4,
n=1
где I{G} — индикатор G (1, если G — истина, и 0, если это не так). И пусть, как и раньше, число К= N0 + N1 +N2 + N3 + N4 (респонденты, которые дали взятку и указали, как давно это было).
Тогда λ вычисляется по тем же формулам (1) и (3), что использовались для вычисления интенсивность взяток при анализе рынка бытовой коррупции. А именно:
λ= – |
(10/365) · ln h1 + (1/12) · ln h2 + (1/12) · ln h3 + ln h4 |
1,7955, (1.6.8) |
|
(10/365)2 + (1/12)2 + (1/2)2 + 1 |
|||
|
|
где h1 = K1 ·(N1 +N2 +N3 +N4), h2 = K1 ·(N2 +N3 +N4), h3 = K1 ·(N3 +N4), и h4 = K1 ·N4.
197
РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Заметим, что для этих данных экспоненциальная модель дает вполне хорошие результаты. Проиллюстрируем это графиком подгонки методом наименьших квадратов (рис. 1.6.5).
Интенсивность: In(1/h) = IT
f(x) =1,73x + 0,05 R2 = 1
R2 = 0,99
Рис. 1.6.5. График линейной регрессии по методу наименьших квадратов для оценки λ
Охват коррупции. Вычислим сначала число NНЕТ тех респондентов, что выбрали закрытие «Нам никогда не приходилось это делать», и оценим «корректную» долю δ респондентов, дающих взятки, по формулам:
NНЕТ = N I{V2(n) = 6}, δ = |
K |
. |
(1.6.9) |
|
|||
n=1 |
K + NНЕТ |
|
|
Поясним вычисление δ подробнее. Всего в опросе участвовало N респондентов, которые по ответам на вопрос V2 делятся на три группы: ГДА — признавшиеся, что берут взятки, ГНЕТ — выбравшие ответ «Нам никогда не приходилось это делать», и ГН/Д — все остальные (отказавшиеся от ответа и выбравшие вариант «Затрудняюсь ответить»). Значение δ из формулы (9) — это доля респондентов, дающих взятки, среди респондентов, не уклонившихся от «прямого ответа» на вопрос V2, оправдано. Это значение остается корректным и для всей выборки, если считать, что в группе ГН/Д примерно та же δ. На самом деле
198

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
вгруппе ГН/Д доля дающих взятки по многим соображениям не меньше δ, что вполне нас устраивает (и является дополнительным аргументом в пользу того, что истинное значение доли дающих взятки значительно выше этой «корректной» доли δ).
Ввыходных данных эта величина, выраженная в процентах, называется «Охват коррупции» и обозначается d = 100 δ, %.
Средний размер взятки. Чисто формально размеры взяток вычисляются
очень просто. Для этого надо взять величину оборота V1(n), названную респондентом, и взять от нее тот процент V3(n) (тыс. рублей), который назвал этот респондент, отвечая на вопрос о том, какой процент от оборота составила взятка. Но имеется целый ряд «но». Часть респондентов не сообщают об обороте своих фирм (не хотят отвечать на этот вопрос), другие — не отвечают на вопрос о размере взятки, не говоря уже о тех, кто говорит, что он никогда не дает взятки или просто умалчивает, скрываясь за ответом «Затрудняюсь ответить». Наконец, не так уж редко мы сталкиваемся с явными ошибками. На одной категории таких ошибок следует остановиться отдельно. Дело в том, что цифра 50 при ответе на вопрос V3 может оказаться случаем огромной взятки
в50% от месячного оборота, а может оказаться величиной самой взятки в 50 тыс. рублей. Все это надо иметь в виду при анализе рынка деловой коррупции.
Оставляя все эти проблемы на потом, определим массив R = {R(n), 1 ≤ n ≤ N}, где
•R(n) = 0,01 · V1(n) · V3(n) (тыс. рублей), если V1(n) и V3(n) являются числа-
ми,
•R(n) = #Н/Д во всех остальных случаях.
Из этого, созданного нами массива мы формируем выборку В = {b1; b2; …; bH} всех числовых и положительных значений R(n)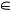 R, где Н — число элементов в выборке В. Теперь средний размер взятки вычисляется как обычное среднее по выборке В*, которая является частью выборки В, полученной путем изъятия нескольких значений в зависимости от размера Н выборки В, правило изъятия приведено в таблице 1.6.6.
R, где Н — число элементов в выборке В. Теперь средний размер взятки вычисляется как обычное среднее по выборке В*, которая является частью выборки В, полученной путем изъятия нескольких значений в зависимости от размера Н выборки В, правило изъятия приведено в таблице 1.6.6.
Таблица 1.6.6. Правила изъятия крайних значений из В для получения В*
№ |
Размер выборки В |
Сколько изымается |
|
|
|
|
|
1 |
H< 7 |
Ничего не изымается |
|
|
|
|
|
2 |
7 ≤ H≤ 100 |
1 минимальное и 1 |
максимальное значение |
|
|
|
|
3 |
100 < H ≤ 250 |
3 минимальных и 3 |
максимальных значения |
|
|
|
|
4 |
H> 250 |
5 минимальных и 5 |
максимальных значения |
|
|
|
|
199