

35589645
.pdfРОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
мерно равен общему среднему рангу по всем данным. А как не трудно вычислить, средний ранг вектора длины N всегда равен величине 12 ·(N + 1). Поэтому критерий основан на сравнении этой величины со средним рангов каждого столбца таблицы. С учетом нужных технических дополнений, получается следующая формула для критерия Краскала-Уоллиса:
H = |
12 |
nj · ( |
r |
j – |
1 |
· (N+ 1))2. |
(1.2.10) |
|
|||||||
N(N +1) |
2 |
Чем больше значение H, тем больше отличия средних рангов внутри столбцов от общего среднего ранга и тем больше оснований считать, в терминах нашего примера, что люди с разным достатком платят взятки разных размеров. Случайная величина H при гипотезе об отсутствии систематических различий между столбцами таблицы данных имеет известное распределение хи-квадрат с (k−1) степенями свободы. Это позволяет обычным образом проверять гипотезы с помощью вычисления доверительной вероятности P{H > H*}. Снова посмотрим, что получилось при применении данного метода к примеру со взятками. Снова выяснилось, что нет оснований для отклонения нулевой гипотезы об отсутствии различий между величиной взяток в группах с разным достатком. Вычисления показали, что H = 1,95 и P = 0,377. Этот тест также подтвердил сделанный ранее вывод: нет различий в величине взяток в целом в трех группах респондентов, относящих себя к разным группам населе-
ния по достатку. Для пущей убежденности взглянем на таблицу со средними
рангами.
Таблица 1.2.10. Сопоставление средних рангов размеров взяток в группах респондентов, выбравших различные ответы на вопрос «Как бы вы оценили ваш уровень жизни по сравнению с большинством ваших знакомых, коллег, соседей?»
|
Число |
Средний |
|
наблюдений |
ранг |
|
|
|
Выше среднего уровня |
25 |
301,4 |
|
|
|
На среднем уровне |
352 |
269,6 |
|
|
|
Ниже среднего уровня |
157 |
257,4 |
|
|
|
Мы видим, что различия в средних рангах действительно не так уж велики. Для сравнения, в данном случае (N+1)/2 = 267,5.
110

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
АНАЛИЗ ВЗАИМОСВЯЗИ МЕЖДУ ЧИСЛОВЫМИ ПЕРЕМЕННЫМИ
Весьма распространены задачи, в которых изучается зависимость между двумя рядами наблюдений над одними и теми же объектами, когда результаты наблюдений заданы числами. Вот простые примеры: есть ли зависимость между размером взятки, в которой признался респондент и среднедушевым месячным доходом; есть ли зависимость между средним размером взятки в регионе и числом убийств на 10000 населения и т.п. Мы не будем говорить здесь о вещах совсем уж общеизвестных — о линейном коэффициенте корреляции, о том, как с его помощью проверяются гипотезы о независимости и т.п. Мы остановимся только на нескольких важных нюансах, которые полезно учитывать при решении подобных задач и которые будут возникать в нашем исследовании.
Первое важное соображение — это необходимость учитывать эффект ложной корреляции. Объясним его на ясном примере. Рассмотрим две величины, описывающих регионы России. Первая — годовой объем рынка деловой коррупции, вторая — региональный валовой продукт. Если вычислить между ними коэффициент линейной корреляции, то получится 0,440 при доверительной вероятности 0,005. Возникает искушение сделать вывод: чем богаче регион, тем больше в нем коррупции. Однако можно задуматься о том, что и ВРП и большое количество взяток может объясняться одним общим обстоятельством — численностью населения в регионе. И если учесть численность населения, то никакой корреляции не обнаружится. Эту гипотезу можно проверить с помощью понятия частной корреляции. Ее еще называют условной корреляцией. В нашем случае это означает зависимость между объемом рынка деловой коррупции и региональным валовым продуктом, если фиксировано значение численности населения (иногда говорят — если учитывается значение численности населения). В нашем примере вычисление такой частной корреляции дает следующий результат: корреляция равна –0,117, доверительная вероятность равна 0,484. Мы видим, что при учете численности населения обнаруженная ранее корреляция исчезает. Такого рода корреляции называются ложными корреляциями. Их частое появление должно учитываться при статистическом анализе зависимостей.
Второй момент, требующий обсуждения, — это анализ диаграмм рассеяния. Речь идет вот о чем. Если у нас есть две переменных, описывающих наблюдения за объектами, то каждый объект может быть представлен точкой на координат-
ной плоскости. Первая координата точки — это значение объекта по первой
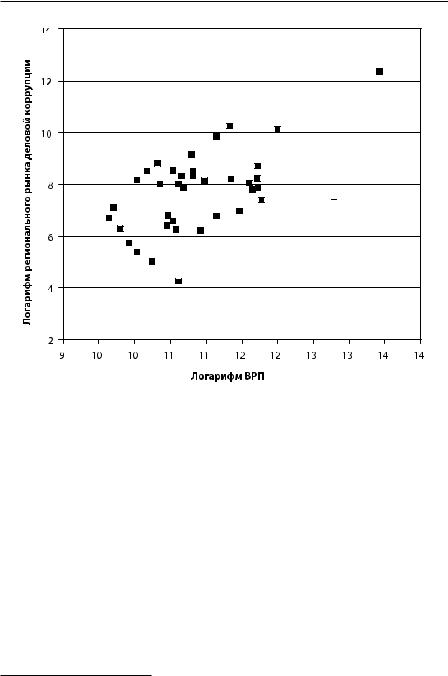
переменной, вторая координата — значение того же объекта по второй переменной. Ниже приведена диаграмма рассеяния для использовавшегося выше примера, только для наглядности вместо самих значений объема коррупции и ВРП использованы их логарифмы. Каждая точка на этой диаграмме соответствует субъекту Федерации. В левом нижнем углу расположены регионы с невысоким ВРП и невысоким рынком деловой коррупции. В правом верхнем углу расположены регионы с большим ВРП и обширным рынком деловой коррупции.
111
РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Москва
Московская 
 область
область

 Тюменская область
Тюменская область

 Псковская область
Псковская область
Рис. 1.2.2. Диаграмма рассеяния субъектов Федерации на плоскости двух переменных: логарифм валового регионального продукта (ось Х) и логарифм объема рынка деловой коррупции в регионе.
На диаграмме рисунка 1.2.2 мы видим пример облака рассеяния двух переменных, к которым применима линейная гипотеза о связи: статистическая зависимость между двумя переменными есть зашумленная линейная зависимость. Только для такого рода зависимостей применимо вычисление коэффициента линейной корреляции вместе со стандартными процедурами проверки гипотез.
Понятно, что существует великое множество отклонений от таких замечательных диаграмм рассеяния. Мы рассмотрим два важных случая.
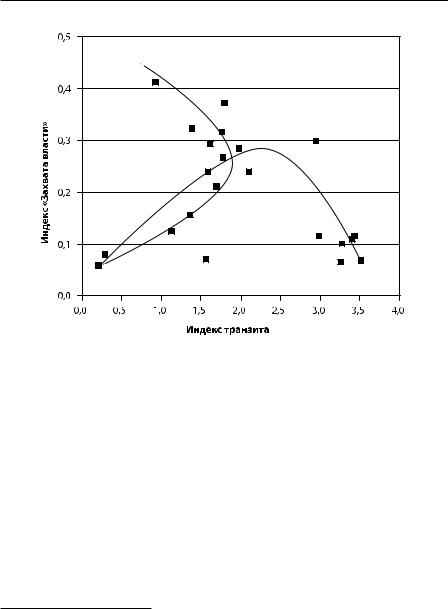
Первый: диаграмма с выраженной нелинейной зависимостью. Приведем реальный пример диаграммы рассеяния между двумя переменными (рис. 1.2.3). Первая переменная (вертикальная ось) соответствует индексу захвата государства, определявшемуся для транзитных стран в исследовании Всемирного банка «Business Environment and Enterprise Performance Survey» (BEEPS)1.
1Hellman J., Jones G. and Kaufmann D. Цит. соч.
112
ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Азе |
|
|
Рос |
|
Лат |
|
Слв |
Каз |
Лит |
|
Блр
Узб |
Вен |
|
Рис. 1.2.3. Диаграмма рассеяния на плоскости двух показателей: степень транзита по данным Фонда ИНДЕМ (горизонтальная ось, чем больше значение, тем дальше продвинута страна по пути транзита); индекс захвата государства по данным исследования Всемирного банка (вертикальная ось, чем больше значение, тем выше захват государства). Использованы данные 2001 г. Помечены точки, соответствующие России (Рос), Латвии (Лат), Литве (Лит), Венгрии (Вен), Казахстану (Каз), Беларуси (Блр), Узбекистану (Узб), Словакии (Слв) и Азербайджану (Азе)
Вторая переменная взята из исследования Фонда ИНДЕМ «Разнообразие стран и разнообразие коррупции». Она построена на основании данных следующих исследований: «Index of Economic Freedom», Heritage Foundation1; «Aggregate Governance Indicators», World Bank2; «Nations in Transit», Freedom House3. В результате была получена агрегированная переменная «степень транзита», которая учитывала уровень формирования в 22 транзитных странах демократических политических институтов и рыночной экономики.
1Материалы HeritageFoundationна официальном сайте www.heritage.org. Methodology: Factors of the Index of Economic Freedom by William W. Beach and Gerald P. O’Driscoll, Jr.
2Kaufmann D., Kraay A. and Zoido-Lobatón P. Aggregating Governance Indicators (World Bank Policy Research Working Paper 2195) October 1999.
3Материалы Freedom House на официальном сайте www.freedomhouse.org. «Explanatory Notes» Charles Graybow.
113
РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
На диаграмме точки расположены в явно регулярном виде, указывающем на некоторую нелинейную зависимость. Интересующиеся могут узнать об этом в работах Фонда ИНДЕМ1. Нам важно здесь указать на следующий факт: если попытаться вычислить для этого случая коэффициент линейной корреляции, то обнаружится, что он весьма мал. Это именно потому, что он предназначен для других диаграмм рассеяния, отражающих ситуацию линейной модели.
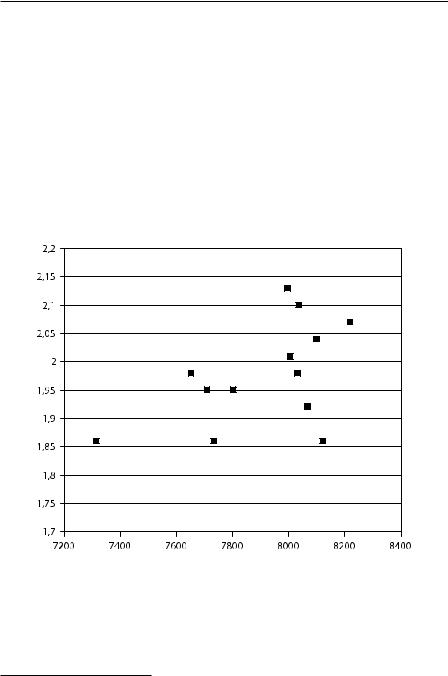
Второй случай мы проиллюстрируем следующим примером. В Париже регулярно проходит турнир десятиборцев «Decastar». Возьмем из таблицы результатов последнего турнира итоговые результаты и результаты по прыжкам в высоту каждого спортсмена и изобразим их на диаграмме рассеяния. Результат можно увидеть на рисунке 1.2.4. Мы видим третий интересный тип диаграммы
Рис. 1.2.4. Диаграмма рассеяния спортсменов-десятиборцев на плоскости двух показателей: итоговый результат (горизонтальная ось, чем больше значение, тем выше результат); результат в прыжках в высоту
1Разнообразие стран и разнообразие коррупции. Цит. соч.
114

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
рассеяния, который можно назвать треугольная диаграмма. Треугольный вид в случае нашего примера означает следующее: крайне маловероятно, чтобы появился спортсмен с высоким результатом в прыжках в высоту и одновременно с низким общим результатом. Это довольно естественно для десятиборья на высшем уровне: наивысших результатов достигает тот, кто хорош во всех видах. Понятно, что треугольная форма выражает здесь вероятностную форму зависимости между целым и частью, общим результатом и его составляющей.
Однако треугольные диаграммы появляются и в более нетривиальных ситуациях. Например, автору данного параграфа пришлось участвовать в разработках методов измерения понимания учебного материала (именно понимания, а не знания или усвоения, как в традиционных педагогических методиках). В экспериментах учащиеся измерялись с помощью новых методов и им приписывались некоторые числа, характеризующие уровень понимания. Одновременно те же учащиеся выполняли стандартные контрольные работы (тесты), которые характеризовали уровень их знаний в традиционном смысле. Сопоставление этих рядов данных приводило к треугольным диаграммам рассеяния: при низком уровне понимания мог быть любой уровень знаний — от высокого до низкого. При высоком уровне понимания уровень знания был только высокий. В данном случае треугольные диаграммы выражали вероятностную причинно-следственную связь: из понимания следует знание, обратное верно не обязательно.
КЛАСТЕРНЫЙ АНАЛИЗ
В анкетах проводимых нами исследований широко используются сложно организованные вопросы, ответы на которых образуют некоторую структуру данных, требующую специального подхода для анализа. Уже упоминалось о двух типах подобных вопросов.
Первый тип: вопросы с множественным выбором ответа (мультивариантные вопросы). Пример, приведенный ниже, взят из анкеты опроса «Граждане-2005».
Пример 1. Как бы вы описали свои ощущения от того, что вам пришлось дать взятку? Выберите, пожалуйста, не более 3-х ответов.
1Презрение к себе
2Ненависть к чиновнику
3 Страх, что могут схватить за руку
4Стыд, смущение
5 Отвращение, что по-другому нельзя
6Унижение
115

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Пример 1. Продолжение
7 |
Гнев, что меня вынудили так поступить |
|
|
8 |
Облегчение, что ситуация разрешилась |
|
|
9 |
Опустошенность |
|
|
10 |
Отчаяние, что этому нет конца и края |
|
|
11 |
Растерянность – не знал, как себя вести |
|
|
12 |
Раскаяние, угрызения совести: жаль, что я так поступил |
|
|
13 |
Радость от того, что удалось заставить чиновника работать на себя |
|
|
14 |
Опасение, что об этом узнают мои знакомые и будут меня осуждать |
|
|
15 |
Ничего не чувствовал, уже привык |
|
|
16 |
Недовольство нашей государственной системой, ставящей людей в такие обстоятельства |
|
|
17 |
Удовлетворение собой, своим умением решать свои проблемы |
|
|
18 |
Другое (укажите, что) __________________________________ |
|
|
00 |
Затрудняюсь ответить |
|
|
Второй тип: табличные вопросы. Приведенный пример взят из анкеты опроса «Бизнес-2005».
Пример 2. Оцените, пожалуйста, насколько в нашей стране мешают развитию такого бизнеса, как ваш, следующие действия властей
№ |
Наименование проблемы |
Очень |
Умеренно |
Практически |
|
мешает |
мешает |
не мешает |
|||
|
|
||||
|
|
|
|
|
|
1 |
Излишнее давление контрольных и надзорных органов |
1 |
2 |
3 |
|
|
|
|
|
|
|
2 |
Излишнее лицензирование |
1 |
2 |
3 |
|
|
|
|
|
|
|
3 |
Создание налоговых и подобных им льгот отдельным |
1 |
2 |
3 |
|
фирмам |
|||||
|
|
|
|
||
|
|
|
|
|
|
4 |
Участие чиновников в борьбе за собственность на сто- |
1 |
2 |
3 |
|
роне «своих» фирм |
|||||
|
|
|
|
||
|
|
|
|
|
|
|
Участие чиновников в управлении компаниями с доля- |
|
|
|
|
5 |
ми федеральной, областной или муниципальной соб- |
1 |
2 |
3 |
|
|
ственности |
|
|
|
|
|
|
|
|
|
|
6 |
Участие в искусственных банкротствах |
1 |
2 |
3 |
|
|
|
|
|
|
|
7 |
Создание искусственных монополий для «своих» фирм |
1 |
2 |
3 |
|
|
|
|
|
|
|
8 |
Плохая защита прав частной собственности |
1 |
2 |
3 |
|
|
|
|
|
|
|
9 |
Плохая работа арбитражных судов |
1 |
2 |
3 |
|
|
|
|
|
|
|
10 |
Плохая работа судов общей юрисдикции |
1 |
2 |
3 |
|
|
|
|
|
|
116

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Пример 2. Продолжение
|
Просьбы о непредусмотренных законами взносах |
|
|
|
11 |
в различные фонды, создаваемые властями (в т.ч. — |
1 |
2 |
3 |
|
на выборы, на праздники) |
|
|
|
|
|
|
|
|
12 |
Навязывание чиновниками своих людей на работу в |
1 |
2 |
3 |
руководство фирмами |
||||
|
|
|
|
|
13 |
Протекционизм «своим» или подконтрольным фирмам |
1 |
2 |
3 |
|
|
|
|
|
14 |
Борьба органов власти за блокирующие или контроль- |
1 |
2 |
3 |
ные пакеты акций |
||||
|
|
|
|
|
15 |
Частным бизнесом в регионе руководят чиновники или |
1 |
2 |
3 |
их родственники |
||||
|
|
|
|
|
16 |
Давление с целью заставить выбрать «нужных» постав- |
1 |
2 |
3 |
щиков или заказчиков продукции |
||||
|
|
|
|
|
Оба типа вопросов объединяет следующее: работая с ними, респонденты сопоставляют и оценивают по единой схеме сравнительно большой набор однотипных объектов. В первом примере это оценки эмоционального состояния. Во втором примере респонденты-предприниматели выражают свое отношение к группе распространенных и неприятных для бизнеса действий властей.
Анализируя ответы на такие вопросы, мы исходим из предположения, которое можно назвать «презумпция ментальной состоятельности». Это значит, что
респонденты в своем большинстве отвечают на вопросы не случайно, а согла-
сованно и в соответствии со своими представлениями, индивидуальными пристрастиями, диспозициями и, если угодно, «моделями жизни». Кроме того, мы предполагаем, что респонденты являются носителями сравнительно небольшого количества типов моделей жизни. И респонденты, обладающие сходными моделями жизни, отвечают на вопросы сходным образом.
Это предположение влечет свои следствия, которые легко проверяются при анализе ответов на вопросы. Например, если анализировать ответы на вопрос первого примера, то мы сочли бы странным и нелогичным, если бы респондент, отвечая на вопрос, включил в свой набор две таких эмоции: «Отчаяние, что этому нет конца и края» (10) и «Радость от того, что удалось заставить чиновника работать на себя» (11). А вот сочетание вроде: «Презрение к себе» (1) и «Стыд, смущение» (2) мы сочли бы более логичным и отражающим некоторый тип эмоциональной реакции.
Теперь обратимся ко второму примеру. При конструировании набора действий властей авторы анкеты компоновали набор, черпая примеры действий властей из трех типологических групп: административная коррупция (1, 2, 3); институциональные дефекты (8, 9, 10); поборы (11); все остальные являются проявлениями захвата бизнеса. Логично предположить, что разный бизнес
117

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
озабочен проблемами различного типа. Это значит, что предприниматели с близкими проблемами и интересами будут склоняться оценивать сходным образом действия властей из одной группы.
Существуют несложные статистические процедуры, позволяющие, не на уровне проверки статистических гипотез, а на уровне качественного (разведывательного) анализа структуры данных проверять правдоподобие такого рода модельных представлений об ответах респондентов. Одной из таких процедур является кластерный анализ. Рассмотрим его применение в данной ситуации.
В примере 1 ответы респондентов на вопрос могут быть представлены в виде матрицы данных вида E = || εij ||, где i — индекс респондента (строки матрицы), а j — индекс ответа на вопрос из примера 1 (столбца матрицы); εij = 1, если i-й респондент выбрал j-й ответ (помимо прочих), отвечая на вопрос примера 1; в противном случае (если не выбрал) εij = 0. В строке респондента в матрице E единицы стоят в тех столбцах, номера которых совпадают с номерами ответов, выбранных респондентом. В столбце вопроса единицы стоят в тех строках, которые соответствуют всем респондентам, выбравшим этот вариант при ответе на вопрос. Если два варианта ответа очень похожи по смыслу, то можно ожидать, что выбирать или не выбирать его будут примерно одни и те же респонденты; значит, единицы в столбцах этих ответов буду чаще всего стоять на одних и тех же местах. Если ответы сильно различаются по смыслу, то можно ожидать, что выбирать его будут разные респонденты; там, где в одном столбце стоят единицы, в другом будут, скорее всего, нули
и наоборот. Тем самым, мы можем говорить, что похожие ответы отражаются в
похожих, близких столбцах — векторах из нулей и единиц; и наоборот — если два вектора-столбца похожи, то это может говорить о смысловой похожести соответствующих вариантов ответа.
Эту степень сходства между векторами-столбцами можно измерить с помощью какого-либо коэффициента. Не уточняя конкретно, что это за коэффициент, обозначим его через sqr. Пусть тогда S = || sqr|| — квадратная матрица различий между векторами-столбцами матрицы E. Если sqr имеет небольшое значение, скажем, близкое к нулю, то это значит, что похожи вектора-столбцы с номерами q и r, а значит, как мы полагаем, похожи по смыслу варианты ответов с теми же номерами. Это, в свою очередь, означает, что если некоторый респондент выбрал один из этих ответов, то он скорее всего выберет и другой. И наоборот, если sqr достаточно велико, то это значит, что вектора-столбцы с номерами q и r не похожи, а значит, как мы полагаем, не похожи по смыслу варианты ответов с теми же номерами. Это, в свою очередь, означает, что если некоторый респондент выбрал один из этих ответов, то он скорее всего не выберет другой. Анализируя такую матрицу, можно понять, как респонденты группируют варианты ответов при выборе, и, как мы можем полагать, в массовом сознании.
118

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Кластерный анализ — один из таких методов анализа матрицы различий. Смысл алгоритма кластерного анализа довольно прост. Опишем его в стандартном пошаговом виде. Только вначале исходную матрицу различий обозначим так: S(1). Кроме того, введем счетчик шагов i, которому сначала присвоим значение 0. С самого начала предуведомляем, что алгоритм состоит в последовательном объединении объектов, между которыми заданы различия
вматрице S, в группы объектов. При этом на каждом последующем шаге мы будем переходить от матрицы различий S(i) к матрице различий S(i+1). Матрица различий S(i) может задавать различия как между исходными объектами, так и между группами объектов (понятно, что один объект можно рассматривать как такую вырожденную группу из одного объекта). Поэтому ниже под объектом будем понимать как исходные объекты, между которыми рассчитаны различия по векторам-столбцам матрицы E, так и группы, составляемые из этих объектов. Итак, алгоритм:
Действие 1. Увеличим значение счетчика шагов i на 1.
Действие 2. В матрице S(i) найдем наименьший элемент, который задает пару самых близких объектов (в нашем случае — ответов на вопрос); пусть эти объекты имеют номера s и r.
Действие 3. Составляем из этих объектов новую группу, объединяя их вместе. Действие 4. Если после объединения все объекты объединились в одну
группу, то работа алгоритма заканчивается.
Действие 5. Переходим от матрицы S(i) к матрице S(i+1) следующим образом:
встроке и столбце под номером s заменяем находящиеся там значения раз-
личий на новые значения различий между остальными объектами и новым
объектом, получившимся в результате слияния объектов s и r. Строка и столбец с номером r из матрицы исключаются.
Действие 6. Возвращаемся к действию 1.
Понятно, что работа такого алгоритма зависит от двух обстоятельств. Первое — способ вычисления различий между векторами-столбцами матрицы E. Второе — способ вычисления расстояний между группами объектов на шаге 5 приведенного алгоритма. Опыт работы с методом кластерного анализа показывает, что если исходные данные действительно содержат в себе структуру достаточно контрастных различий между объектами (респондентами, вопросами), описываемыми этими данными, то, варьируя методы вычисления различий, мы будем получать сходные результаты.
Формальным результатом работы метода кластерного анализа является последовательность пар номеров объединяемых групп объектов. Такой формальный результат анализировать и интерпретировать еще трудно. Поэтому дальше эту последовательность объединений представляют в графической форме дерева, или дендрограммы. На следующем рисунке мы видим как раз дендрограмму, полученную в результате применения метода кластерного анализа к данным примера 1. В этом конкретном применении для расчета разли-
119