

35589645
.pdfРОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
впервые применен при изучении диспозиций населения в отношении коррупции.
В основе метода лежит предположение, что диспозиции респондентов, выраженные в ответах на вопросы анкеты, могут быть объяснены и описаны посредством некоторых обобщенных латентных факторов. Существенно, что прямой вопрос об изучаемых диспозициях, как правило, невозможно задать из-за сложности такого вопроса для респондента, чувствительности темы или по иной причине.
Например, таким фактором может быть оценка уровня коррупции по мнению респондента. Можно предположить, что респонденты, оценивающие уровень коррупции как высокий, отвечая на вопрос о проблемах, которые их беспокоят, наверняка выберут ответ «коррупция, взяточничество», будут считать, что большинство должностных лиц берут взятки, что сейчас коррупция распространена больше, чем в прошлом. Напротив, респонденты, оценивающие уровень коррупции как низкий, реже будут рассматривать коррупцию, как беспокоящую их проблему, будут считать, что должностных лиц, берущих взятки сейчас меньшинство, и что в прошлом коррупция, взяточничество были больше распространены.
Суть используемого нами метода заключается в следующем. Для некоторой латентной переменной (синтетической типологии, фактора) вводится несколько классов (градаций шкалы латентной переменной), а в анкету включаются вопросы, ответы на которые будут обусловлены влиянием данной переменной, так что респонденты, принадлежащие к различным классам, будут, с разными вероятностями выбирать различные варианты ответов. Будет яснее, если мы дадим формальное описание этой конструкции.
Итак, пусть есть некоторая классификация респондентов на классы: A = {A1, …, Ak }. Мы предполагаем, что ответ на вопрос любой анкеты — акт вероятностный. Это значит, что произвольный респондент x выбирает тот или иной ответ на тот или иной вопрос с определенной вероятностью. Пусть имеется вопрос B с множеством ответов {b1, b2, …, bs}. Мы можем предположить также, что вероятности ответов на данный вопрос могут зависеть от принадлежности респондента классам типологии A. Рассмотрим вероятность P(bt | Ai) — вероятность выбора респондентом ответа bt на вопрос В, если он, респондент, принадлежит классу Ai. Если мы классифицируем респондентов по цвету волос, то это вряд ли будет влиять на выбор ответов об уровне коррупции в стране. В этом случае все вероятности P(bt | Ai) будут равны для разных i (т.е. для респондентов из разных классов). Если теперь предположить, что мы смогли разбить всех респондентов на несколько групп, отличающихся друг от друга степенью оценки уровня коррупции в стране, то тогда при разных i мы будем иметь существенно различные вероятности P(bt | Ai). С другой стороны, мы можем разбить респондентов на классы (группы) по уровню оценки коррупции в стране, но при этом задать им вопрос о любимом
150

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
кинофильме. Естественно предположить, что и в этом случае все вероятности P(bt | Ai) будут равны для разных i, т.е. выбор ответа и принадлежность различным классам — события независимые. Эти рассуждения подводят нас к тому, что с разными латентными переменными, описывающими диспозиции респондентов, могут быть связаны свои вопросы. Эта связь означает, что ответы на эти вопросы в существенной степени определяются различиями в диспозициях, выраженными различиями в значениях данной переменной, в частности — принадлежностью разным классам некоторой классификации (типологии).
Теперь важно добавить следующее. Во введении уже отмечалось, что при анализе данных опросов мы исходим из предположения о том, что взаимосвязь между диспозициями респондента и ответами на вопрос неоднозначна. В данном случае мы должны полагать, что выбор ответа на вопрос об уровне коррупции (даже вероятностный выбор) зависит не только от оценки респондентом уровня коррупции в стране. Этот выбор может зависеть от настроения респондента, от его доверия властям и от множества других более или менее важных обстоятельств. Компенсировать эту неоднозначность можно только одним способом: мы будем анализировать некоторый набор различных вопросов. Все вопросы этого набора объединяет взаимосвязь с фиксированной диспозицией, например — оценкой уровня коррупции в стране.
Тогда логика практического применения данной модели такова:
1.Мы конструируем некоторую типологию респондентов — описываем некоторый набор классов.
2.Мы подбираем к этой типологии набор вопросов, предполагая, что выбор ответов на все эти вопросы зависит от принадлежности респондентов классам типологии.
3.Мы устанавливаем взаимосвязь между принадлежностью классам типологии и выбором ответов на отобранные выше вопросы. Взаимосвязь устанавливается оценкой вероятностей P(bt | Ai) с помощью экспертов.
4.Мы проводим опрос и устанавливаем, как каждый респондент отвечал на все вопросы, связанные с данной типологией.
5.Используя оценки вероятностей P(bt | Ai) и наборы ответов респондентов, мы определяем принадлежность респондентов классам типологии.
Итак, условные вероятности выбора ответов представителями каждого из классов оцениваются экспертами. Принадлежность респондента к классу определяется в зависимости от того, насколько его набор ответов является «правдоподобным» по отношению к набору условных вероятностей представителя данного класса по сравнению с остальными классами. Типичными задачами, решаемыми при построении латентной переменной экспертно-стати- стическим методом являются определение принадлежности респондента к классу на основании модели поведения, предложенной одним экспертом, оценка качества экспертизы и выделение группы («ядра») экспертов, адекват-
151

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
но отражающих центральное экспертное мнение, объединение классификаций, построенных отдельными экспертами, в итоговую классификацию.
В рамках данного исследования рассматривается 9 латентных переменных (см. таблицу 0.2 введения). Одна из них используется ниже в качестве источника примеров.
ПОСТРОЕНИЕ ЛАТЕНТНОЙ ПЕРЕМЕННОЙ ДЛЯ ОДНОГО ЭКСПЕРТА
Задача эксперта, привлекаемого для построения синтетической типологии (латентной переменной), состоит в оценке условных вероятностей для представителей классов данной типологии при выборе ответа на все связанные с ней вопросы анкеты.
Пусть A = {A1, …, Ak } — шкала латентной переменной, включающей K градаций (классов), at 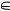 At, t = 1, K — типичный представитель класса At, B= {B1, …, Bm} — список вопросов анкеты, связанных с латентной переменной A, sj— количество закрытий (вариантов ответов, далее — ответов) в
At, t = 1, K — типичный представитель класса At, B= {B1, …, Bm} — список вопросов анкеты, связанных с латентной переменной A, sj— количество закрытий (вариантов ответов, далее — ответов) в
вопросе Bj (j=1,m), btj — вариант ответа на вопрос Bj, t =1, 2, …, sj. «Типовой» вопрос экспертизы формулируется следующим образом:
«Оцените пожалуйста (в баллах) вероятность того, что представитель класса Ak, отвечая на вопрос Bj,
выберет вариант ответа btj»1. Таким образом, по одному вопросу Bj эксперту необходимо заполнить таблицу, пример которой приведен ниже.
Таблица 1.4.1. Пример таблицы, заполняемой экспертом
Нередко можно услышать, что люди в высших органах |
|
|
|
|
|
|
власти нечестны, корыстны, приходят во власть только |
|
Классы типологии |
|
|||
для своего обогащения. С каким высказыванием на эту |
«Оценка уровня коррупции» |
|||||
тему вы согласны в максимальной степени? |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ответы на вопрос анкеты респондентов |
Высокий |
|
Средний |
|
Низкий |
|
уровень |
|
уровень |
|
уровень |
|
|
|
|
|
|||
|
|
|
|
|
|
|
1. Меньшинство людей в высших органах власти берут взятки |
0 |
|
0 |
|
2 |
|
|
|
|
|
|
|
|
2. |
Большинство людей в высших органах власти берут взятки |
5 |
|
4 |
|
2 |
|
|
|
|
|
|
|
3. |
Ни то, ни другое, примерно поровну |
1 |
|
2 |
|
3 |
|
|
|
|
|
|
|
4. |
Затрудняюсь ответить |
1 |
|
2 |
|
1 |
|
|
|
|
|
|
|
1Здесь предполагается, что респондент может выбрать один из вариантов ответа на вопрос, причем закрытие типа «затрудняюсь ответить» рассматривается как один из вариантов. Случай, когда респондент может выбрать несколько вариантов, в данном исследовании был сведен «одновариантному» случаю посредством специальной формулировки вопроса экспертизы.
152

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Для сопоставления баллов и вероятностей эксперту предъявляется таблица, в которой для каждого ответа представлены баллы и соответствующий им диапазон вероятностей в интервальной шкале (см. таблицу 1.4.2).
Таблица 1.4.2. Словесные формулировки, интервалы шансов и оцифровка баллов
Баллы |
Шансы (словесные формулировки) |
Шансы, % |
Оцифровка |
|
|
|
|
6 |
Близки к стопроцентным |
95–100 |
0,97 |
|
|
|
|
5 |
Весьма высоки, но заведомо не стопроцентные |
85–95 |
0,90 |
|
|
|
|
4 |
Не слишком высоки, но заведомо выше половины |
60–85 |
0,75 |
|
|
|
|
3 |
Примерно поровну |
40–60 |
0,50 |
|
|
|
|
2 |
Вполне реальны, но заведомо ниже половины |
15–40 |
0,25 |
|
|
|
|
1 |
Весьма малы, но заведомо не нулевые |
5–15 |
0,10 |
|
|
|
|
0 |
Близки к нулевым |
0–5 |
0,03 |
|
|
|
|
Ответы эксперта переводятся из баллов в вероятности в соответствии с принятой оцифровкой (таблица 1.4.2) и нормируются для каждого класса на сумму вероятностей по ответам.
Итак, предположим, что для некоторой латентной переменной вопрос задается экспертам E1, …, En (n — количество экспертов) относительно всего списка вопросов, всех вариантов ответов btj (t=1,sj, j=1,m) на вопрос Bt и всех
классов Af , 1 ≤ f ≤ K. Таким образом, после оцифровки экспертных баллов и
нормировки вероятностей, мы располагаем набором всех условных вероятностей выбора варианта ответа в каждом вопросе анкеты для всех классов и всех экспертов:
q(i,j), q(i,j) ≥ 0, q(i,j) + … + q(i,j) = 1, t = 1, s , j= 1, m, i = 1, n, f = 1, K . |
||||
tj f tj f |
1 f |
sj f |
j |
j |
Введем необходимые обозначения. Пусть
Q(fi,j) = (q(1i,fj) , … , q(sji,fj))
представляют условные вероятности — модель поведения типичного представителя класса Af при выборе ответов на вопрос Bj, определенная i-м экспертом. А
Qf (i)= (Q(fi,1) , … , Q(fi,m)),
определяет модель поведения типичного представителя класса Af при выборе ответов на все вопросы анкеты, связанные с латентной переменной A, по мнению i-го эксперта. Пусть, наконец,
153

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Q(i) =(Q1 (i), …, QK (i))
определяет модель поведения представителей всех классов при выборе ответов на вопросы анкеты по мнению i-го эксперта.
Подход к решению задачи построения латентной переменной по модели поведения представителей классов, предложенной одним экспертом, заключается в следующем. Предполагается, что априори принадлежность к различным классам-градациям типологии равновероятна и что респонденты отвечают независимо на отдельные вопросы анкеты. При данных предположениях по набору ответов респондента и модели поведения представителей классов определяются байесовские апостериорные вероятности принадлежности респондентов к каждому из классов. Принадлежность к классу определяется в соответствии с принципом максимума байесовской апостериорной вероятности.
Пусть T(r) =(t1 (r), …, tm (r)) — список номеров ответов респондента r. Для каждого эксперта Ei определяются:
P(r  Af | t1 (r), …, tm (r); i), f = 1, K ,
Af | t1 (r), …, tm (r); i), f = 1, K ,
апостериорные байесовские вероятности принадлежности респондента r к классу Af на основании его ответов по мнению i-го эксперта при априорном равномерном распределении по классам A1, …, AK.
Обозначим через Lm(r, f,i) = m q(tji,(jr)) f вероятность реализации набора отве-
j=1
тов Tr при предположении, что «типичный» респондент из класса Af отвечает независимо на отдельные вопросы анкеты.
Тогда апостериорная байесовская вероятность принадлежности респондента r к классу Af на основании его ответов Tr по мнению i-го эксперта рассчитывается по формуле:
P(r |
|
Af | t1 (r), …, tm (r); i) = |
Lm(r, f, i) |
|
|
|
|
. |
(1.4.1) |
||
|
K Lm(r, k, i) |
||||
k=1
Номер класса респондента f(i, r) определяется в соответствии с принципом максимума байесовской апостериорной вероятности:
f(i, r) = arg max P(r 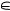 Ak| t1 (r), …, tm (r); i)
Ak| t1 (r), …, tm (r); i)
1≤k ≤ K
154

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
АНАЛИЗ РЕЗУЛЬТАТОВ ЭКСПЕРТИЗЫ
Анализ результатов экспертизы направлен на выделение наиболее качественных экспертных мнений. В целом, оценка качества экспертизы обусловлена качеством размытой классификации по генеральной совокупности наборов ответов.
Очевидно, что при заданном наборе ответов на вопросы Tr качество определения номера класса f(i, r) тем выше, чем ближе к 1 соответствующая ему вероятность P(r 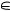 Af | t1 (r), …, tm (r); i) и, таким образом, меньше вероятность ошибочной классификации. Близость к 1 зависит от двух обстоятельств.
Af | t1 (r), …, tm (r); i) и, таким образом, меньше вероятность ошибочной классификации. Близость к 1 зависит от двух обстоятельств.
Во-первых, важно, насколько хорошо эксперт своими оценками различает классы по поведению их типичных представителей при выборе ответов на вопросы анкеты. Во-вторых, существенно, насколько точно оценки эксперта будут соответствовать реальному поведению респондентов, т.е. насколько точно эксперт «связывает» отдельные вопросы анкеты.
Ключевую роль в оценке качества экспертизы играет матрица ошибок классификации. Элементами такой матрицы являются вероятности вида:
fgk(i1,i2) = P (ag |
|
Ak | Q(i1),Q(i2)), |
(1.4.2) |
|
Здесь fgk(i1,i2) — вероятность того, что типичный представитель ag класса Ag,
использующий при выборе ответа на вопросы анкеты модель поведения
Q1 (i1) (определенную экспертом i1), по мнению эксперта i2 будет принадлежать классу Ak. Данная вероятность определяется по формуле полной вероятности как средневзвешенное по вероятностям из (1.4.1):
fgk(i1,i2) = P (ag  Ak | Q(i1))· m q(tji(1a,jg))g , по всем Ti1 (ag)
Ak | Q(i1))· m q(tji(1a,jg))g , по всем Ti1 (ag) 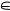 T(Ω)
T(Ω)
j=1
Матрица с элементами (1.4.2) характеризует качество классификации эксперта i2 относительно эксперта i1: чем ближе такая матрица к единичной, тем выше качество классификации. В случае, когда i1 = i2, матрица характеризует качество различения классов-градаций латентной переменной одним экспертом, его «самосогласованность». Расчет такой матрицы связан с перебором всех возможных вариантов наборов ответов, но с учетом нынешнего развития вычислительной техники эта проблема оказывается вполне решаемой.
В то же время, для оценки связей между вопросами анкеты и учета реального поведения респондентов могут использоваться выборочные оценки «матрицы ошибок», рассчитанные по результатам классификации респондентов.
155

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
I{l(i1, r)= g} · P(r  Ak | t1 (r), …, tm (r); i2)
Ak | t1 (r), …, tm (r); i2)
f |
gk |
(i ,i ) = |
r R |
|
|
, |
(1.4.3) |
|
|
|
|||||
|
1 2 |
|
I{l(i1, r)= g} |
|
|||
|
|
|
|
|
|||
|
|
|
|
r |
R |
|
|
среднее значение вероятности принадлежать классу Ak по всем респондентам, отнесенным к классу Ag. Также возможно использование оценки по таблице сопряженности, построенной по дискретным классификациям экспертов:
|
I{l(i1, r)= g; l(i2, r)= k} |
|
|
f gk(i1,i2) = |
r R |
, |
(1.4.4) |
I{l(i1, r)= g} |
|||
|
r R |
|
|
(в случае, когда i1 = i2, очевидно, получается единичная «матрица ошибок»). Далее реализовывался следующий подход. По полученным одним из спосо-
бов (1.4.2)–(1.4.4) матрицам ошибок для каждого эксперта и для каждой пары экспертов рассчитывалась характеристика качества, принимающая максимальное значение в случае, когда матрица ошибок совпадает с единичной. Одной из таких характеристик является характеристика согласованности каппа1 — κi1i2. В таблице 1.4.3 приведены значения характеристик согласованности для 8 экспертов, рассчитанные по данным экспертизы для шкалы «Установка на корруп-
цию». Значения по диагонали характеризуют качество различения классов,
внедиагональные элементы — согласованность экспертов.
Таблица 1.4.3. Оценки качества и согласованности экспертов по данным экспертизы
\ |
Э1 |
Э2 |
Э3 |
Э4 |
Э5 |
Э6 |
Э7 |
Э8 |
|
|
|
|
|
|
|
|
|
Э1 |
0.580 |
0.350 |
0.332 |
0.263 |
0.186 |
0.330 |
0.300 |
0.365 |
|
|
|
|
|
|
|
|
|
Э2 |
0.272 |
0.406 |
0.266 |
0.251 |
0.139 |
0.248 |
0.228 |
0.284 |
|
|
|
|
|
|
|
|
|
Э3 |
0.310 |
0.305 |
0.509 |
0.293 |
0.128 |
0.264 |
0.240 |
0.313 |
|
|
|
|
|
|
|
|
|
Э4 |
0.203 |
0.223 |
0.265 |
0.423 |
0.141 |
0.197 |
0.254 |
0.244 |
|
|
|
|
|
|
|
|
|
Э5 |
0.079 |
0.071 |
0.061 |
0.076 |
0.103 |
0.083 |
0.083 |
0.074 |
|
|
|
|
|
|
|
|
|
Э6 |
0.310 |
0.291 |
0.268 |
0.263 |
0.192 |
0.437 |
0.284 |
0.321 |
|
|
|
|
|
|
|
|
|
Э7 |
0.254 |
0.221 |
0.200 |
0.243 |
0.151 |
0.216 |
0.449 |
0.244 |
|
|
|
|
|
|
|
|
|
Э8 |
0.327 |
0.307 |
0.309 |
0.325 |
0.176 |
0.293 |
0.293 |
0.467 |
|
|
|
|
|
|
|
|
|
1Флейс Дж. Статистические методы для изучения таблиц долей и пропорций. Москва : Финансы и статистика, 1989.
156

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
В таблице 1.4.4 приведены аналогичные «выборочные» характеристики, рассчитанные с учетом результатов опроса 2005 года. Диагональные элементы определялись по формуле (1.4.3), внедиагональные — как каппа-статистика — по таблице сопряженности.
Таблица 1.4.4. Оценки качества и согласованности экспертов по данным экспертизы и опроса респондентов 2005 г.
\ |
Э1 |
Э2 |
Э3 |
Э4 |
Э5 |
Э6 |
Э7 |
Э8 |
|
|
|
|
|
|
|
|
|
Э1 |
0.558 |
0.320 |
0.314 |
0.184 |
0.259 |
0.316 |
0.296 |
0.322 |
|
|
|
|
|
|
|
|
|
Э2 |
0.320 |
0.454 |
0.284 |
0.180 |
0.138 |
0.225 |
0.243 |
0.278 |
|
|
|
|
|
|
|
|
|
Э3 |
0.314 |
0.284 |
0.526 |
0.227 |
0.105 |
0.350 |
0.217 |
0.313 |
|
|
|
|
|
|
|
|
|
Э4 |
0.184 |
0.180 |
0.227 |
0.479 |
0.187 |
0.189 |
0.247 |
0.208 |
|
|
|
|
|
|
|
|
|
Э5 |
0.259 |
0.138 |
0.105 |
0.187 |
0.233 |
0.219 |
0.246 |
0.148 |
|
|
|
|
|
|
|
|
|
Э6 |
0.316 |
0.225 |
0.350 |
0.189 |
0.219 |
0.496 |
0.229 |
0.396 |
|
|
|
|
|
|
|
|
|
Э7 |
0.296 |
0.243 |
0.217 |
0.247 |
0.246 |
0.229 |
0.512 |
0.258 |
|
|
|
|
|
|
|
|
|
Э8 |
0.322 |
0.278 |
0.313 |
0.208 |
0.148 |
0.396 |
0.258 |
0.513 |
|
|
|
|
|
|
|
|
|
Отметим, что таблицы 1.4.3 и 1.4.4 достаточно хорошо согласуются между собой. Так, наиболее слабым оказывается эксперт 705, хотя его самосогласованность по результатам опроса оказывается несколько выше самосогласованности по результатам экспертизы, т.е. эксперт 705 при относительно сла-
бом различении классов все же достаточно хорошо оценивает связи между
вопросами. То же можно сказать и о других экспертах, исключение — эксперт Э1, но здесь существенно, что этот эксперт больше всех различает классы (значение характеристики — максимальное из всех диагональных). Из таблиц 1.4.3 и 1.4.4 видно, что наиболее согласованными между собой и при этом обладающими относительно высокой самосогласованностью являются эксперты Э1, Э6, Э8.
Отметим, что, таким образом, для каждого эксперта все остальные выступают в роли контрольной выборки, моделирующей реальное поведение респондентов. Поэтому дальнейшее упорядочение экспертов связано с выделением главного фактора, характеризующего различия в согласованности экспертов.
В таблице 1.4.5 приведены значения весов и рейтинги экспертов, рассчитанные по таблицам 1.4.3 и 1.4.4. Видно, что различия в рейтингах, построенных только по экспертизе и с учетом данных опроса, не очень значительны, отличия сказываются на 4–6 экспертах, что позволяет включить в «ядро» экспертов Э1, Э6, Э8, занимающих 1–3 место, а еще одного-двух экспертов отбирать по дополнительным характеристикам.
157

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Таблица 1.4.5. Значения весов и рейтинги экспертов
Эксперт |
По экспертным оценкам |
|
По результатам опроса |
|
||||
|
|
|
|
|
|
|
|
|
Качество |
Вес |
|
Ранг |
Качество |
Вес |
|
Ранг |
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
Э1 |
0.580 |
0.158 |
|
1 |
0.558 |
0.143 |
|
1 |
|
|
|
|
|
|
|
|
|
Э2 |
0.406 |
0.130 |
|
5 |
0.454 |
0.123 |
|
6 |
|
|
|
|
|
|
|
|
|
Э3 |
0.509 |
0.142 |
|
4 |
0.526 |
0.132 |
|
4 |
|
|
|
|
|
|
|
|
|
Э4 |
0.423 |
0.117 |
|
7 |
0.479 |
0.104 |
|
7 |
|
|
|
|
|
|
|
|
|
Э5 |
0.103 |
0.042 |
|
8 |
0.233 |
0.096 |
|
8 |
|
|
|
|
|
|
|
|
|
Э6 |
0.437 |
0.144 |
|
3 |
0.496 |
0.139 |
|
3 |
|
|
|
|
|
|
|
|
|
Э7 |
0.449 |
0.117 |
|
6 |
0.512 |
0.124 |
|
5 |
|
|
|
|
|
|
|
|
|
Э8 |
0.467 |
0.151 |
|
2 |
0.513 |
0.139 |
|
2 |
|
|
|
|
|
|
|
|
|
Эксперты Э2 и Э7 делят между собой 5–6 места, однако дополнительным аргументов в пользу 5-го места эксперта Э2 является несколько близкое к первым трем по рангу экспертам распределение респондентов по классам (см. таблицу 1.4.6).
Таблица 1.4.6. Распределение респондентов по классам в шкале «Установка на коррупцию» в исследовании 2005 года
эксперт |
A1 |
A2 |
A3 |
A4 |
A5 |
|
|
|
|
|
|
Э1 |
615 |
1116 |
661 |
278 |
430 |
|
|
|
|
|
|
Э2 |
523 |
914 |
504 |
719 |
440 |
|
|
|
|
|
|
Э3 |
492 |
929 |
853 |
686 |
140 |
|
|
|
|
|
|
Э4 |
684 |
1426 |
360 |
399 |
231 |
|
|
|
|
|
|
Э5 |
1205 |
500 |
334 |
340 |
721 |
|
|
|
|
|
|
Э6 |
377 |
744 |
1358 |
476 |
145 |
|
|
|
|
|
|
707 |
463 |
910 |
617 |
827 |
283 |
|
|
|
|
|
|
Э8 |
198 |
1040 |
1192 |
429 |
241 |
|
|
|
|
|
|
Данные результаты вполне согласуются с результатами анализа экспертизы 2001 г., основанного на характеристике скорости распознавания класса в отдельном вопросе1, по итогам которого в ядро экспертов были включены эксперты Э1, Э2, Э6, Э8, т.е. различия сказываются только на четвертом по рангу эксперте (см. также таблицу 1.4.7).
1Подробнее об этом см. в Приложении III к докладу «Диагностика российской коррупции — 2001».
158

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
Таким образом, в «ядро» экспертов включаются те, кто обладает двумя качествами: хорошей самосогласованностью (матрица ошибок классификации близка к единичной) и хорошей согласованностью с другими экспертами с учетом и/или без учета реального поведения респондентов.
ОБЪЕДИНЕНИЕ ЭКСПЕРТНЫХ МНЕНИЙ
Для экспертов, вошедших в «ядро», оценивались веса, и итоговая классификация рассчитывалась как средневзвешенная по «ядру» экспертов.
Для оценки весов экспертов использовался следующий подход. Для каждой пары экспертов (i1,i2) по таблице сопряженности классификаций оценивалась характеристика согласованности каппа — κi1i2. То есть оценка качества экспертизы была основана на выборочной оценке матрицы ошибок классификации (1.4.2). Для симметричной неотрицательной матрицы א={κij}, элементами которой являются характеристики согласованности, выполнено условие Фробениуса-Перрона, она имеет соответствующий максимальному собственному значению собственный вектор с неотрицательными элементами, которые и берутся в качестве весов экспертов.1 Такой подход направлен на выделение главного фактора, определяющего различия в экспертных классификациях и формирование согласованной итоговой классификации. Идеологически это соответствует решению задачи о лидере2.
Обозначим wi ≥ 0 веса экспертов, w1 + w2 + … + wn = 1. Итоговая оценка
вероятности принадлежности респондента r к классу Ag считается по формуле:
^ |
|
|
|
K |
||
P(r |
|
Ag |
| t1 |
(r), …, tm (r)) = wi ·P(r |
|
Ag| t1 (r), …, tm (r); i), |
|
|
|||||
|
|
|
|
i=1 |
||
а номер класса l(r) определяется, также как и l(i,r) по максимуму итоговой оценки вероятности принадлежности к классу:
^
l(r) = arg max P(r 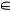 Ak| t1 (r), …, tm (r)).
Ak| t1 (r), …, tm (r)).
1≤k ≤ K
Таким образом, итоговая классификация (латентная переменная) отражает «центральное» мнение наиболее компетентных экспертов.
1«Ядро» экспертов формировалось таким образом, чтобы было больше 0, противный случай свидетельствует о плохом качестве — либо для классификации одного из экспертов, либо для списка вопросов в целом.
2Миркин Б.Г. Проблема группового выбора. Москва : Наука, 1974.
159