

35589645
.pdfРОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
чий между векторами-столбцами матрицы E использовался коэффициент Юла1 Q, он же, как правило, использовался в наших расчетах. Пусть у нас есть два вектора-столбца матрицы E. Введем следующие обозначения: a — число респондентов, выбравших оба ответа (число случаев, когда на одинаковых местах в векторах стоят единицы), d — число респондентов не выбравших оба ответа (число случаев, когда на одинаковых местах в векторах стоят единицы), b — число респондентов, выбравших первый ответ, но не выбравших второй, c — число респондентов, не выбравших первый ответ, но выбравших второй. Тогда коэффициент Q определяется по следующей формуле:
Q = |
(ad – bc) . |
(1.2.10) |
(ad – bc) |
Этот коэффициент принимает значение –1, когда вектора противоположны, и 1, когда совпадают. Поэтому их значение обычно преобразуется изменением знака и перемасштабированием в интервал [0; 1]. Тогда они приобретают смысл не корреляций, а различий. Использование именно этого коэффициента обусловлено тем, что, как правило, он дает более контрастную картину по сравнению с остальными.
Для вычисления расстояний между группами использовалось среднее межгрупповое различие: складываются все исходные различия между объектами одной группы и объектами другой группы, и полученная сумма делится на
произведение численностей двух групп. Это стандартный метод, предлагае-
мый по умолчанию в SPSS.
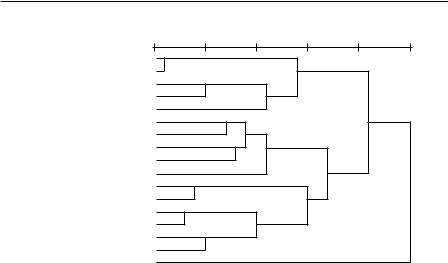
Итак, обещанная дендрограмма.
«Поваленное» на бок дерево, изображенное на рисунке 1.2.5, имеет следующий смысл. Из дендрограммы следует, что пара самых близких объектовответов, — это 12 и 14 — «Раскаяние» и «Опасение». Это изображено на дендрограмме, соединяющей их скобочкой с самыми короткими ножками. Зная это, мы увидим следующие по сходству ответы — «Стыд» и «Растерянность». И сразу можно понять, что ответ 5 «Ничего не чувствовал» располагается где-то на отшибе. Вообще действует следующее правило: длина горизонтальной ножки скобки соответствует расстоянию (на дереве) между объектами, которые эта скобка соединяет. Взгляд на дендрограмму в целом позволяет увидеть структуру вроде гроздьев (кластеров). В гроздья объединяются сходные объекты. Большие гроздья могут делиться на маленькие и т.п. Тем самым, дендрограмма становится инструментом, позволяющим увидеть структуру данных; в нашем случае — это структура сходств-различий между ответами на вопрос.
1Кендалл М.Дж., Стьюарт А. Цит. соч. Стр. 723.
120
ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
0 |
5 |
10 |
15 |
20 |
25 |
Раскаяние 12 Опасение 14 Радость 13
Удовлетворенность 17 Облегчение 8 Отвращение 5 Отчаяние 10 Ненависть к чиновнику 2 Гнев 7 Ненависть к системе 16
Презрение к себе 1 Опустошенность 9 Стыд 4 Растерянность 11 Страх 3 Унижение 6
Ничего не чувствовал 5
Рис. 1.2.5. Дендрограмма, изображающая результат применения кластерного анализа к матрице различий между векторами ответов на вопрос «Как бы вы описали свои ощущения от того, что вам пришлось дать взятку?» анкеты опроса «Граждане-2005»
Однако мы помним, что этой структуре двойственна структура сходств и различий между респондентами: сходные респонденты близким образом
отвечают на вопросы, с большой вероятностью выбирая ответы из одного
кластера. Это позволяет, задавшись классификацией ответов, увиденной с помощью дендрограммы, строить классификации респондентов. Методы таких построений будут продемонстрированы ниже в исследовании.
Теперь перейдем к примеру 2. Ответы на вопрос этого примера также можно представить матрицей данных, несколько отличной от предыдущей, X = || xij|| , где i — индекс респондента (строки матрицы), а j — индекс про- блем-действий властей, соответствующих строкам табличного вопроса; xij — код ответа i-го респондента, относящегося к j-й проблеме. В строке респондента в матрице X стоят все его ответы по всем проблемам табличного вопроса. В столбце, соответствующем одной проблеме, стоят ответы всех респондентов. Если две проблемы очень похожи по смыслу, то можно ожидать, что респонденты будут сходным образом их оценивать; значит, векторы-столбцы, соответствующие этим проблемам, будут сходны. Если проблемы сильно различаются по своей природе, то можно ожидать, что респонденты будут приписывать им различные баллы; в результате соответствующие векторы-столбцы будут непохожи. Тем самым, мы можем говорить, что похожие проблемы отражаются в похожих, близких столбцах; и наоборот — если два вектора-столбца похожи, то это может говорить о смысловой похожести соответствующих проблем.
121
РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
0 |
5 |
10 |
15 |
20 |
25 |
9
10
8
15
16
13
14
12
4
5
6
7
11
1
2
3
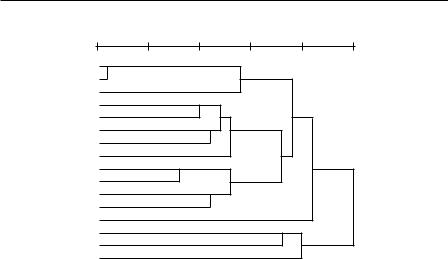
Рис. 1.2.6. Дендрограмма, изображающая результат применения кластерного анализа к матрице различий между проблемами, описанными в вопросе «Оцените, пожалуйста, насколько в нашей стране мешают развитию такого бизнеса, как ваш, следующие действия властей?» анкеты опроса «Граждане-2005»
Повторяя примененную выше логику рассуждений, мы переходим от
матрицы данных X к матрице различий S между проблемами, соответствую-
щими векторам-столбцам. И затем к этой матрице применяем метод кластерного анализа. Результат для примера 2 приведен на рисунке 1.2.5.
Если читатель возьмет на себя труд сопоставить номера проблем на рисунке с соответствующими им текстами выше в таблице вопроса примера 2, то можно будет увидеть, насколько логично объединяются проблемы на дендрограмме. Это значит, что есть группы респондентов, для которых более важны проблемы одного типа и менее важны — другого. Ниже это обстоятельство будет использоваться для построения типологий респондентов.
На примере этой дендрограммы мы покажем другой пример ее «чтения». Структура дендрограммы на рисунке 1.2.5 позволяет увидеть следующее. Все объекты (проблемы) делятся на две группы (кластера): в первую входят объекты {1, 2, 3}, а во вторую группу — все остальные. Вторая группа делится на две. Первую образует единственный объект с номером 11, вторую — оставшиеся объекты. Последняя группа делится снова на две: в первую входят объекты с номерами 8, 9, 10, а во вторую — 4, 5, 6, 7, 12, 13, 14, 15, 16. Проследив за представленным перечнем «деления» первоначального множества объектов на кластеры, читатели смогут далее продолжить этот процесс.
122

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
В связи с табличными вопросами, уже безотносительно к собственно кластерному анализу, следует упомянуть еще об одной их особенности, позволяющей обогащать возможность построения типологий респондентов. Опыт применения подобных вопросов показывает, что всегда можно выделить две группы респондентов. Первая состоит их тех респондентов, которые, в терминах нашего примера, приписывают почти всем проблемам максимальную важность. Вторая — это те, кто, напротив, почти все проблемы недооценивает с точки зрения их важности. Это обстоятельство также будет учитываться при построении типологий респондентов по их ответам на табличные вопросы.
§ 1.3. ПОСТРОЕНИЕ РЕЙТИНГОВ
ЧТО ТАКОЕ РЕЙТИНГ?
При проведении опросов общественного мнения достаточно часто ставится вопрос об отношении респондентов к некоторому множеству объектов с той или иной точки зрения. Объектами могут выступать политические партии, сектора экономики, способы передвижения, законодательные акты, высказывания (лозунги, мнения, максимы) и т.п., то есть объекты одного рода.
Фактически в анкету вставляется табличный вопрос следующего типа:
Как часто, по вашему мнению, жителям Республики Татарстан приходится сталкиваться со взяточничеством, коррупцией в отдельных сферах повседневной жизни, перечисленных ниже? Укажите оценку для каждой строки.
|
|
1 |
2 |
3 |
4 |
5 |
№ |
Наименование проблемы |
|
|
|
|
|
Не прихо- |
Редко |
Время от |
Довольно |
Очень |
||
|
|
дится |
|
времени |
часто |
часто |
1 |
Получение бесплатной медицинской помощи |
|
|
|
|
|
|
в поликлинике (анализы, прием у врача и т.п.), |
(1) |
(2) |
(3) |
(4) |
(5) |
|
в больнице (лечение, операция, нормальное |
|||||
|
|
|
|
|
|
|
|
обслуживание и т.п.) |
|
|
|
|
|
|
|
|
|
|
|
|
… |
......................................................................... |
……… |
…… |
……… |
……… |
…… |
|
|
|
|
|
|
|
7 |
Решение проблем с призывом на военную службу |
(1) |
(2) |
(3) |
(4) |
(5) |
|
|
|
|
|
|
|
… |
......................................................................... |
……… |
…… |
……… |
……… |
…… |
|
|
|
|
|
|
|
16 |
Зарегистрировать сделки с недвижимостью |
(1) |
(2) |
(3) |
(4) |
(5) |
|
|
|
|
|
|
|
17 |
Другое (указать) |
(1) |
(2) |
(3) |
(4) |
(5) |
|
|
|
|
|
|
|
Примечание. Вопрос взят из анкеты, по которой проводился опрос жителей Татарстана (осень 2004 г.); приводится сокращенный список «объектов оценивания».
123

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
Вданном случае объектами являются ситуации повседневной жизни, проблемы, которые приходится решать гражданам, вступая в контакт с государственными служащими, и по существу респонденты оценивают плотность коррупции в этих ситуациях, частоту столкновения со взяточничеством со стороны чиновников.
Вэтом примере шкала оценок содержит 5 градаций: 1. Не приходится, 2.
Редко, 3. Время от времени, 4. Довольно часто и 5. Очень часто. Но списки градаций могут быть самыми разными — вот несколько примеров.
Таблица 1.3.1. Градации типа «школьных» оценок и типа «За — Против»
2 градации |
3 градации |
|
|
Неудовлетворительно |
Плохо |
|
|
Удовлетворительно |
Посредственно |
|
|
5 градаций |
Хорошо |
|
|
Отвратительно |
4 градации |
|
|
Плохо |
Плохо |
|
|
Посредственно |
Хуже, чем посредственно |
|
|
Хорошо |
Лучше, чем посредственно |
|
|
Отлично |
Хорошо |
|
|
2 градации |
3 градации |
|
|
Не нравится |
Заведомо хуже |
|
|
Нравится |
Не хуже и не лучше, то же самое |
|
|
5 градаций |
Заведомо лучше |
|
|
Заведомо «Против» |
4 градации |
|
|
Скорее «Против», чем «За» |
Абсолютно не согласен |
|
|
Ни «За», ни «Против», фифти-фифти |
Скорее не согласен, чем согласен |
|
|
Скорее «За», чем «Против» |
Скорее согласен, чем не согласен |
|
|
Заведомо «За» |
Абсолютно согласен |
|
|
Для того, чтобы разобраться в содержании рейтингов, нам удобно рассмотреть пример с минимальным числом градаций для оценивания объектов.
Существуют различные суждения о судебной системе, о наших судьях. Как бы вы оценили в этой связи следующие высказывания?
№ |
Наименование проблемы |
Согласен |
Не согласен |
Затрудняюсь |
|
|
|
|
ответить |
|
|
|
|
|
1 |
Судьи плохо защищены, получают небольшую зарплату, поэ- |
(1) |
(2) |
(0) |
|
тому некоторые из них начинают брать взятки |
|||
|
|
|
|
124

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
2 |
В судах часто выигрывает дело тот, кто больше заплатит |
(1) |
(2) |
(0) |
|
|
|
|
|
… |
......................................................................... |
……… |
……… |
…… |
|
|
|
|
|
9 |
Судьи слишком неквалифицированны, чтобы грамотно |
(1) |
(2) |
(0) |
|
решать дела |
|||
|
|
|
|
|
|
|
|
|
|
Примечание. Вопрос взят из анкеты, по которой проводился опрос жителей Татарстана (осень 2004 г.); приводится сокращенный список «объектов оценивания».
В этом примере оценочными градациями являются только две, «Согласен» и «Не согласен», однако наличие варианта «Затрудняюсь ответить» («з/о») уже не позволяет провести простое сравнение объектов по доле ответивших «Согласен», поскольку разное количество затруднившихся ответить респондентов при оценке разных суждений приводит порой к несопоставимости объектов по доле ответивших «Согласен».
Для нашего анализа мы рассмотрим специально сконструированную таблицу данных с всего тремя суждениями (какие они — нам неважно).
Таблица 1.3.2. Данные о распределении ответов респондентов
Объекты оценивания |
Согласен |
Не согласен |
З/о |
Всего |
|
|
|
|
|
Суждение №1 |
528 |
274 |
198 |
1000 |
|
|
|
|
|
Суждение №2 |
528 |
375 |
97 |
1000 |
|
|
|
|
|
Суждение №3 |
528 |
470 |
2 |
1000 |
|
|
|
|
|
Разглядывая эту таблицу, мы легко поймем, что главное различие между суждениями определяется тем, как распределяются 472 (1000 — 528) респондента по ответам «Не согласен» и «З/о», поскольку вариант «Согласен» набрал одно и то же число голосов (528) при оценке всех трех суждений. Можно было бы проигнорировать тех респондентов, которые выбрали ответ «З/о», если бы не одно «но»: здесь выбор «З/о» является вполне содержательной оценкой, лежащей между «Согласен» и «Не согласен». Другими словами, если мы на каком-нибудь листке бумаги оценки «Согласен» и «Не согласен» отметим точками, то «З/о» наиболее естественно поместить между ними, приняв за точку или за несколько «размазанную» точку. Фактически это равносильно оцифровке градаций, например, «Не согласен» мы можем поместить в начало шкалы, оцифровать как 0, «Согласен» — как 1, а «З/о» принять за ½ . Поскольку 1-е суждение оценку 1 (Согласен) получило 528 раз, 198 раз — оценку 0.5 и 274 раза — оценку 0, то среднеарифметическая оценка 1-го суждения будет равна 0.627 (это тривиально вычисляется непосредственно: (1 · 528 + 0.5 · 198 +
+ 0 · 274)/1000 = 0.627).
Такого рода среднеарифметические оценки при специально подобранных оцифровках градаций и называются рейтингами.
125

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
В данном случае значение рейтинга можно рассматривать как числовой вариант ответа в среднем на подразумевающийся вопрос «На сколько процентов вы согласны с таким-то утверждением?». Число 0.627 равносильно 62,7% для 1-го суждения. Второе и третье суждения получат значения в 57,65% и 52,9% соответственно. Это как бы мнения усредненного респондента, «середины» в многообразии всей изучаемой популяции.
Методика построения рейтингов опирается на ряд специальных экспертиз, по которым определяется связь между градациями оценок, которые выбирают респонденты, и позициями этих градаций на шкале рейтингов. Сама шкала рейтингов — это числа от 0 до 1, отрезок [0;1]. Смысловое содержание рейтинга, его вербальная интерпретация, часто зависит от конкретики задаваемого вопроса и от семантической шкалы градаций.
Фактически всегда респонденту предлагается оценить степень выраженности некоторого свойства, степень его наличия (или процент) у ряда объектов из некоторого списка. И если бы мы могли получить от респондента числовой ответ в процентах или долях, если бы респондент умел измерить, сколько этого свойства в долях от максимально возможного количества присутствует у того или иного объекта, то вычисляемый нами рейтинг был бы простонапросто средним значением всех респондентских оценок, мнением некого
усредненного респондента.
ФОРМУЛЫ ДЛЯ ВЫЧИСЛЕНИЯ РЕЙТИНГОВ
В этом разделе мы приводим финальные формулы без их обоснования. Для того, чтобы их использовать, табличные вопросы должны удовлетворять нескольким требованиям:
•число оценочных градаций должно быть не более пяти (вариант «Затрудняюсь ответить» не в счет: он может быть или не быть);
•оценочные градации должны укладываться в некий хорошо интерпретируемый порядок;
•оцениваемые объекты должны относиться к одному смысловому ряду;
•в формулах будут использованы следующие обозначения: h — число оценочных градаций (либо 2, либо 3, либо 4, либо 5), которые кодируются цифрами от 1 до h таким образом, чтобы порядок градаций был согласован с ростом рейтинга, так чтобы оценка с кодом 1 была бы худшей для рейтинга, а оценка с кодом h — лучшей;
•ответ «Затрудняюсь ответить» кодируется числом 0, независимо от его наличия или отсутствия в списке предлагаемых вариантов ответа;
•Nz — число респондентов, выбравших для оценки вариант ответа с кодом z (либо одну из оценочных градаций при 1 ≤ z ≤ h, либо «Затрудняюсь ответить» при z = 0);
126

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
•m — списочный номер оцениваемого «объекта» из табличного вопроса, S — суммарное число «объектов», так что m = 1, 2, …, S;
•wz(h)— оцифровка варианта ответа с кодом z при общем числе h оценочных градаций.
В общем случае рейтинг объекта вычисляется по формуле
ħ |
ħ |
– 0,075 |
|
ħ |
h wz(h) · Nz |
0,5 · N |
|
||
x |
|
|
|||||||
X(m) = |
m |
|
, |
xm = |
|
|
+ |
0 |
(1) |
|
0,85 |
|
|
N0 + N1 + ħ Nh |
|||||
|
|
|
|
z=1 N0 + N1 + ħ Nh |
|
||||
где веса (оцифровки градаций) берутся из таблицы 1.3.3. Отметим, что при отсутствии в списке градаций варианта «Затрудняюсь ответить» N0 = 0.
Таблица 1.3.3. Экспертно установленные значения оцифровки градаций wz(h)
Коды градаций (z) |
h= 2 |
h= 3 |
h= 4 |
h= 5 |
|
|
|
|
|
1 |
0,1525 |
0,13125 |
0,11 |
0,10125 |
|
|
|
|
|
2 |
0,8475 |
0,5 |
0,265 |
0,2825 |
|
|
|
|
|
3 |
|
0,86875 |
0,735 |
0,5 |
|
|
|
|
|
4 |
|
|
0,89 |
0,7175 |
|
|
|
|
|
5 |
|
|
|
0,89875 |
|
|
|
|
|
Проблемы измерения рейтинга на примере сравнения знаний у школь-
ников по литературе и математике
Рассмотрим модельную ситуацию сравнения знаний у школьников по литературе и по математике. В качестве экспериментальных данных выступают отметки учеников, полученных за общегородские контрольные работы по этим предметам. Итак, всего участвовало N учеников, которые в итоге получили следующие отметки:
•по литературе — N2(L) двоек, N3(L) троек, N4(L) четверок и N5(L) пятерок;
•по математике — N2(M) двоек, N3(M) троек, N4(M) четверок и N5(M) пятерок.
Если бы нас интересовали только положительные отметки, т.е. мы могли бы «свалить в кучу» «тройки», «четверки» и «пятерки», то сравнение стало бы тривиальным: где больше «двоек», там и хуже. Но загвоздка в том, что по математике, как правило, больше «двоек» и, одновременно, больше «пятерок». И, как говорят, «"тройка" "тройке" — рознь», полученная оценка является лишь неким неточным отражением чего-то «истинного».
Другими словами, решение этой модельной проблемы лежит в очень трудной области формализации понятия «знания», связывания его с отметками за
127

РОССИЙСКАЯ КОРРУПЦИЯ: УРОВЕНЬ, СТРУКТУРА, ДИНАМИКА. ОПЫТ СОЦИОЛОГИЧЕСКОГО АНАЛИЗА
контрольные работы, конструирования «меры знания», которая учитывала бы и объем, и качество.
При создании любого измерительного прибора решается несколько задач: выбирается шкала измерения, ее границы, шкала по возможности линеаризуется, проводится ее калибровка. Точно так же мы должны поступать и здесь. Очевидно, что содержательное различие между результатами контрольной работы варьирует от «ничего не сделал», «никаких знаний не проявил» до «блестящая работа», «лучшего и не требуется». Конечно, диапазон шкалы зависит от задания, которое было заложено в контрольных, от его сложности. Поэтому наша шкала, как бы мы ее ни строили, будет относительной, зависящей от содержания контрольного задания. А раз так, то границы этой шкалы мы можем установить волевым образом, например, поместив «полное отсутствие каких-либо знаний» на один край шкалы, в точку 0 (нуль), а «показательную по полноте и качеству работу» — на другой край шкалы, в точку 1 (один).
Теперь мы должны перейти к самой сложной части нашего исследования: разобраться, как соотносятся отметки «двойка», «тройка», «четверка» и «пятерка» с позиционированием на нашей «шкале знаний», представленной отрезком [0;1]. Очевидно, что «двойка» — это не точка на этой шкале, а некий «размытый интервал», некое распределение значений в интервале от нуля до некоторогозначения,которое,скореевсего,меньшеоднойтрети.Аналогичные суждения можно высказать и относительно других отметок, «размещая» их в «размытые интервалы» внутри отрезка [0;1].
Что же это такое «размытый интервал» для «двойки»? Или для другой отметки? Хотим мы того или нет, но это связано со случайностью, которая обусловлена как вариабельностью самих учеников по уровню знаний, так и различиями между оценивающими их «учителями». Другими словами, те школьники, которые «схватили» «двойку», не идентичны друг другу: одни получили эту оценку почти случайно, другие чуть-чуть не дотянули до тройки, третьи были «настоящими двоечниками». Следовательно, оценка «два» представляет некоторое распределение значений на «шкале знаний». И нам нужно поискать ряд правдоподобных гипотез о генезисе наших экспериментальных данных, чтобы сконструировать измеримую по ним «меру знаний».
Уже на этом этапе мы можем выдвинуть следующую рабочую гипотезу: мы будем считать, что все наши N учеников, занумерованы в случайном порядке 1, 2, … N; то есть, нет никаких связей между номером ученика и его «знаниями», какими бы способами они (знания) не определялись.
А теперь мы рассмотрим проблему измерения «знания» только по одному предмету, по математике, имея в виду, что все наши рассуждения ничем не будут отличаться, если мы математику заменим на литературу. Поскольку номера достаются ученикам абсолютно случайно, то школьник с конкретным номером n 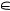 {1; 2; …; N} может оказаться с любой отметкой за контрольную, и естественно предположить, что наблюдаемые частоты «двоек», «троек», «четве-
{1; 2; …; N} может оказаться с любой отметкой за контрольную, и естественно предположить, что наблюдаемые частоты «двоек», «троек», «четве-
128

ГЛАВА 1. МЕТОДЫ ИССЛЕДОВАНИЯ
рок» и «пятерок» можно считать отражением вероятностного распределения между этими событиями. Более того, если через ξn(M) обозначить оценку n-го ученика за контрольную по математике, то можно считать, что совокупность {ξ1(M), ξ2(M), …, ξn(M)} представляет последовательность независимых и одинаково распределенных случайных величин, принимающих значения 2, 3, 4 и 5 с неизвестными нам вероятностями p2(M), p3(M), p4(M) и p5(M). Эти
вероятности легко оцениваются частотами π (M) = Nk(M), k {2; 3; 4; 5}. |
|
k |
N |
Далее, если n-й школьник попал в двоечники, то, как уже отмечалось выше, его «истинный уровень знаний» размыт, и его можно описать некой случайной величиной ζn[N], распределенной по некому неизвестному закону F(x | 2), где 2 — индекс полученной оценки («пары»). То же самое мы можем сказать, если n-й школьник получил любую отметку k 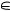 {2; 3; 4; 5}: его «истинный уровень знаний» можно описать случайной величиной с распределением F(x | k) на [0;1]. И вот тут мы сделаем два крайне важных и нетривиальных допущения.
{2; 3; 4; 5}: его «истинный уровень знаний» можно описать случайной величиной с распределением F(x | k) на [0;1]. И вот тут мы сделаем два крайне важных и нетривиальных допущения.
1. Распределения F(x| k) не зависят от того, по какому предмету была контрольная. Для примера, троечники и по литературе, и по математике распределены на шкале [0;1] по «уровню знаний» вокруг «средней тройки» примерно одинаково (в рамках модели — абсолютно одинаково), причем, позиция «средней тройки» для обоих предметов одна и та же.
2. Распределения F(x | k) можно с практически допустимой точностью аппроксимировать кусочно-равномерными распределениями следую-
щего вида. Если Au = {x: au–1 ≤ x < au}, где a0 = 0, a1 = 0.15, a2 = 0.35, a3 = 0.65, a4 = 0.85 и a5 = 1, то плотность f(x| k) распределения F(x | k) в интервале
Au |
постоянна и равна |
qk(u) |
≥0, а вне отрезка [0;1] тождественно равно |
||
au |
–au–1 |
||||
|
|
|
|||
нулю, причем, qk(1) + qk(2) + qk(3) + qk(4) + qk(5) = 1.
Второе допущение можно считать безобидным, поскольку это семейство плотностей достаточно богато для аппроксимации реальности. Конечно, в общем случае надо было бы разрешить свободное варьирование не только вероятностей qk(u) попадания в интервалы Au, но и границ au самих интервалов, однако специально проведенные экспертизы вариантов и их математикостатистический анализ показал, что можно ограничиться этим, несколько суженным семейством распределений.
Что касается первого допущения, то оно принято по двум причинам: с одной стороны, оно вполне правдоподобно, если считать, что экзаменаторы по литературе и по математике принадлежат одной педагогической школе, а с другой, совершенно непонятно, каким образом строить альтернативы к этому допущению.
Вся эта математическая «кухня» со случайными величинами и их распределениями нам была нужна, в основном, для того, чтобы свести задачу измере-
129