

Tom_2
.pdfХозяйство |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
|
|
|
|
|
|
|
|
Валовый сбор (ц) |
400 |
320 |
250 |
300 |
170 |
240 |
140 |
180 |
Найти среднее значение выборки, дисперсию и стандартное отклонение.
Решение. Вначале найдем среднее арифметическое по исходным данным валового сбора зерновых в хозяйствах:
|
|
|
|
|
1 |
|
8 |
|
|
2000 |
|
|
|
|
|
|
|
|
|
x = |
|
åxi |
= |
= 250 ц. |
|
|
|||||||||
|
|
8 |
|
|
|||||||||||||
|
|
|
|
|
8 i=1 |
|
|
€ |
= |
σ8 |
( X ) целесообразно |
||||||
|
|
|
|
|
|
|
= |
D8 |
|
|
|
||||||
Для вычисления |
|
D |
|
(X ) и σ |
|
||||||||||||
построить следующую табл. 2. |
|
|
|
|
|
|
|
|
Таблица 2 |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
Хозяйства |
|
Валовой |
|
|
xi - x |
|
|
|
(x - x )2 |
|
||||||
|
|
|
сбор (ц) |
|
|
|
|
|
|
|
i |
|
|||||
|
1 |
|
|
400 |
|
|
|
|
150 |
|
|
|
22 500 |
|
|||
|
2 |
|
|
320 |
|
|
|
|
70 |
|
|
|
4 900 |
|
|||
|
3 |
|
|
250 |
|
|
|
|
0 |
|
|
|
0 |
|
|||
|
4 |
|
|
300 |
|
|
|
|
50 |
|
|
|
2 500 |
|
|||
|
5 |
|
|
170 |
|
|
|
|
– 80 |
|
|
|
6 400 |
|
|||
|
6 |
|
|
240 |
|
|
|
|
– 10 |
|
|
|
100 |
|
|||
|
7 |
|
|
140 |
|
|
|
– 110 |
|
|
|
12 100 |
|
||||
|
8 |
|
|
180 |
|
|
|
|
– 70 |
|
|
|
4 900 |
|
|||
|
Итого |
|
|
2000 |
|
|
|
0 |
|
|
|
53 400 |
|
||||
Теперь легко найти, что выборочная дисперсия
D = 53400 = 6675 . 8
Извлекая из дисперсии корень, получим величину выборочного стандартного отклонения σ€ » 82 ц. □
Таким образом, можем заключить, что степень разброса в данной выборочной совокупности невелика.
Для сравнения средних стандартных отклонений различных выборок из одной генеральной совокупности вычисляют коэффициент вариации, который определяется по формуле
v = σx€ ×100 % ,
434

т.е. коэффициент вариации равен процентному отношению выборочного стандартного отклонения к среднему выборочному.
20. Мода и медиана. Наряду со средним выборочным в качестве статистических характеристик вариационных рядов рассматриваются структурные средние – мода и медиана.
Мода m0 выборки представляет собой значение варианты,
повторяющееся с наибольшей частотой. Если две или более несмежных вариант имеют разные наибольшие частоты, то вариационный ряд называют бимодальным или полимодальным. В этом случае можно говорить о неоднородности выборки.
Медианой me называют значение параметра, относительно
которого статистическая совокупность делится на две равные по объему части, причем в одной из них содержатся члены, у которых значения параметра не больше me , а в другой – члены со значениями
параметра не меньше me .
Если сумма абсолютных частот n дискретного вариационного ряда нечетная, то медиана me определяется по формуле
me = a
если n – четное, то
1 æ me = 2 çç an
è 2
n+1 ,
2
ö
+ an+1 ÷÷ .
2 ø
Пример 2. Рабочие бригады из 11 человек имеют следующие тарифные разряды: 9, 5, 9, 6, 6, 8, 7, 6, 7, 8, 6. Найти моду и медиану в ы б о р к и .
Решение. Проведем упорядочивание статистического ряда по возрастанию: 5, 6, 6, 6, 6, 7, 7, 8, 8, 9, 9.
Очевидно, m0 = 6 . Мода отражает наиболее распространенную
варианту рассматриваемого признака. В данном случае это будет рабочий шестого разряда. Можно заметить, что моду легко определять, если воспользоваться полигоном частот.
Легко найти также медиану, me = 7 . Именно рабочий седьмого разряда находится на середине статистического ряда. □
Вотличие от дискретных вариационных рядов определение моды
имедианы по интервальным рядам требует более сложных расчетов. Если предположить, что интервалы вариационного ряда имеют
одинаковую длину h и (xi ; xi+1) – модальный интервал, т.е. интервал,
435
которому соответствует наибольшая частота mi , то мода вычисляется по формуле
m0 |
= xi + h |
mi - mi−1 |
|
, |
|
(mi - mi−1 ) + (mi |
- mi+1 ) |
||||
|
|
|
m0
(4)
где mi−1 , mi+1 – частоты, которые соответствуют предмодальному и
послемодальному интервалам.
Чтобы найти медиану интервального вариационного ряда, вначале также следует определить медианный интервал. Медианным называют первый интервал, накопленная частота которого превышает или равна половине общей суммы абсолютных частот, т.е.
i−1 |
n |
i |
|
|
åmj < |
£ åmj . |
(5) |
||
2 |
||||
j=1 |
j=1 |
|
||
|
|
Тогда медиана me вычисляется по формуле
|
h |
æ |
n |
i−1 |
ö |
|
|
|
me = xi + |
ç |
- åmj ÷ |
, |
(6) |
||||
m |
2 |
|||||||
|
ç |
j=1 |
÷ |
|
|
|||
|
ме è |
|
ø |
|
|
|||
где h и mме – длина и частота mi медианного интервала, соответственно.
Пример 3. Обследование качества пряжи на прочность дало следующие результаты:
Прочность |
120 – |
140 – |
160 – |
180 – |
200 – |
220 – |
240 – |
260 – |
нити |
140 |
160 |
180 |
200 |
220 |
240 |
260 |
280 |
Частота mi |
1 |
6 |
19 |
58 |
53 |
24 |
16 |
3 |
(число случаев |
||||||||
порыва) |
|
|
|
|
|
|
|
|
Найти моду и медиану выборки.
Решение. Модальным интервалом является интервал (180; 200), ему соответствует частота mi = 58 . Следовательно, в формуле (4) следует
положить: xi = 180, h = 20, mi−1 = 19, mi+1 = 53 .
Получим
m0 |
=180 + 20 |
|
58 -19 |
»198,1. |
||
(58 |
-19) |
+ (58 - 53) |
||||
|
|
|
||||
Для нахождения медианы воспользуемся формулой (6). Вначале с помощью неравенств (5) найдем медианный интервал. Нетрудно посчитать, что сумма всех частот равна n = 180 . Таким образом, неравенства (5) имеют вид
i |
180 |
i+1 |
||
åmj £ |
< åmj . |
|||
|
2 |
|||
j=1 |
j=1 |
|||
|
|
|||
436

Если положить i = 5, то
4
åmj =1+ 6 +19 + 58 = 84 ,
j=1
5
åmj = 84 + 53 =137
j=1
и будем иметь
84 < 90 < 137.
Следовательно, медианным является интервал (200; 220),
mме = 53 и
me = 200 + 2053 (90 - 84) »102,3 . □
30. Моменты вариационного ряда. Моменты вариационного ряда определяются аналогично соответствующим характеристикам случайной величины из п.10.5.40.
Начальным моментом r-го порядка выборки называется величина
|
€ |
= |
k |
|
¢ |
|
|
|
r |
mi |
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
, |
|
|
|
|
(7) |
|||||||||
|
νr |
|
å(xi ) |
|
|
|
|
|
|
n |
|
|
|
|
|||||||||||
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
mi |
|
||
где n – объем выборки, x′ – различные варианты, |
– относительная |
||||||||||||||||||||||||
|
|||||||||||||||||||||||||
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
частота варианты xi′ . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Рассмотрим частные случаи формулы (7): |
|
||||||||||||||||||||||||
|
|
|
k |
|
|
|
mi |
|
|
|
|
|
|
|
|
|
|
|
|||||||
ν€0 |
= å1× |
|
|
=1 ; |
|
|
|
|
|
||||||||||||||||
n |
|
|
|
|
|
||||||||||||||||||||
|
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
k |
|
|
mi |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
ν€1 |
= åxi¢ |
|
= x ; |
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
i=1 |
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
) |
2 |
|
mi |
|
|
|
|
|
|
|
|
|
|
|||||||||
€ |
= |
¢ |
|
|
|
= |
x |
2 |
; |
|
|
||||||||||||||
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
||||||||||||||||||
ν2 |
|
å(xi |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|||||||||
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
k |
|
|
3 |
mi |
|
|
|
|
|
|
|
|
|
|
|||||||||
€ |
= |
¢ |
|
= |
x |
3 |
. |
|
|
||||||||||||||||
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|||||||||||||||||||
ν3 |
|
å(xi |
) |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
||||||||
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Центральным моментом r-го порядка выборки называется |
|||||||||||||||||||||||||
величина |
|
k |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
mi |
|
|
|
|
|||||
μ€r = å(xi¢ - |
x |
)r |
|
, |
|
(8) |
|||||||||||||||||||
|
|
||||||||||||||||||||||||
|
|
i=1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
где x – среднее значение выборки.
437
Легко видеть, что
|
k |
|
|
|
mi |
|
|
||||
μ€0 = å1× |
|
=1. |
|||||||||
|
n |
||||||||||
|
i=1 |
|
|
|
|
|
|||||
Далее имеем |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
||
k |
m |
|
|
1 |
|
k |
|||||
μ€1 = å(xi¢ - x ) |
|
i |
|
= |
|
|
åxi¢mi - x = 0 ; |
||||
n |
|
||||||||||
i=1 |
|
|
|
n i=1 |
|||||||
k |
|
|
|
|
|
|
mi |
|
|||
μ€2 = å(xi¢ - x )2 |
|
=ν2 -ν12 ; |
|||||||||
|
|
||||||||||
i=1 |
|
|
|
|
|
|
n |
|
|
||
|
|
|
|
|
|
|
|
|
|
||
k |
|
mi |
|
|
|
|
|
|
|||
μ€3 = å(xi¢ - x )3 |
=ν3 - 3ν1ν2 + 2ν13 . |
||||||||||
|
|||||||||||
i=1 |
|
n |
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
||
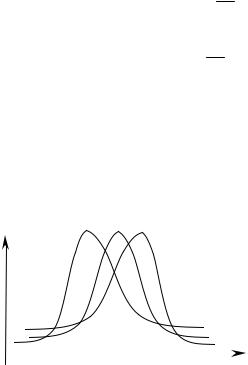
40. Асимметрия и эксцесс. Асимметрией распределения выборки называют величину
α= σμ€€33 ,
аэксцесс определяют следующим образом:
ε= σμ€€44 - 3.
Асимметрия и эксцесс характеризуют форму распределения. При симметричном распределении вариант в вариационном ряду равноудаленные от x варианты будут иметь одинаковую частоту и μ€3 = 0 , а следовательно, и α = 0 . Если в вариационном ряду
преобладают варианты меньшие, чем средняя x , то α < 0 и ряд будет отрицательно асимметричен, т.е. будет наблюдаться более длинная ветвь влево. Положительная асимметрия (более длинная ветвь вправо)
|
|
|
α = 0 |
|
|
будет |
наблюдаться |
в |
||
|
|
α > 0 |
α < 0 |
|
|
случае, |
когда |
α > 0 , |
т.е. |
|
y |
|
|
||||||||
|
|
|
|
когда |
|
|
преобладают |
|||
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
варианты большие, чем x |
||||
|
|
|
|
|
|
(рис.1). Таким образом, |
||||
|
|
|
|
|
|
асимметрия |
характеризует |
|||
|
|
|
|
|
|
«меру |
симметричности» |
|||
|
|
|
|
|
|
эмпирической |
кривой |
|||
|
|
|
|
|
|
распределения |
|
по |
||
0 |
|
|
|
|||||||
|
x |
сравнению |
с |
нормальной |
||||||
|
|
|
Рис. 1 |
|
|
кривой распределения, |
для |
|||
|
|
|
|
|
|
которой α = 0 . |
|
|||
438

Эксцесс характеризует высоту вершины эмпирической кривой распределения по сравнению с нормальной кривой. Как известно,
ε > 0 |
|
|
μ€4 |
= 3 для нормального распределения. |
||||||
|
|
4 |
||||||||
|
|
σ€ |
|
|
|
|
|
|
|
|
ε = 0 |
|
П о э т о м у е с л и ε < 0 , |
|
т о э т о |
||||||
|
свидетельствует о большей рассеянности |
|||||||||
|
|
|||||||||
|
|
вариант, и при ε > 0 будет наблюдаться |
||||||||
ε < 0 |
|
большая концентрация вариант вокруг x |
|
|||||||
|
( |
р |
и |
с |
. |
2 |
) |
. |
||
0 |
|
|
|
|
|
|
|
|
||
x |
|
|
|
|
|
|
|
|
||
Рис. 2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
439

50. Аппроксимация выборочного распределения. После построения гистограммы распределения случайной величины X нужно знать приближенное аналитическое представление неизвестного закона распределения X.
В случае непрерывной случайной величины X такое представление полезно по следующим причинам: а) аналитический вид плотности распределения сглаживает выборочный ряд наблюдений и дает представление о стохастической природе механизмов изучаемого явления; б) аналитическое представление позволяет интерполировать н а б л ю д е н и я .
Таким образом, возникает задача выбора аналитического вида аппроксимирующего распределения. Аппроксимирующую функцию можно выбрать различными способами, например, можно взять
полином B(x) = b |
+ b x + ... + b xk , при этом, чем выше степень |
|
0 |
1 |
k |
полинома, тем точнее он описывает гистограмму. К аппроксимации плотности распределения обычно предъявляют следующие требования: аналитический вид должен соответствовать предполагаемому закону распределения, число параметров распределения не должно быть слишком велико (как правило, не более четырех).
Для выбора кривой аппроксимирующей функции иногда применяют метод моментов, суть которого состоит в следующем. Пусть X – непрерывная случайная величина и f (x) – ее неизвестная плотность распределения. Требуется по выборке найти ее оценку f€(x) .
Возьмем |
в |
качестве |
аппроксимирующей функции |
f€(x) |
|||||||||
следующую: |
|
|
|
|
|
|
|
|
|
|
|
|
|
f€(x) = |
B(x) e− x2 |
|
|
|
x2 |
(9) |
|||||||
= e− 2 (b0 + b1x +K + bk xk ). |
|||||||||||||
|
|
2 |
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
2π |
2π |
|
||||||||
Оценки |
k +1 |
параметров b0 ,b1,...,bk в (9) нужно выбрать так, |
|||||||||||
чтобы наилучшим образом приблизить f€(x) к f (x) . Определим меру близости f€(x) к f (x) числом y:
y = |
|
+∞ò ( f€(x) − f (x))2 e |
x2 |
|
|
|
2 |
dx. |
(10) |
||
2π |
|||||
−∞
440
Для наилучшей оценки коэффициентов b0 ,b1,...,bk следует потребовать, чтобы y из (10) была наименьшей, как функция переменных b0 ,b1,...,bk .
Необходимое условие минимума |
|
∂y |
|
= 0 |
; |
∂y |
= 0 |
; …; |
∂y |
|
= 0 |
||
|
∂b |
∂b |
∂b |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
||||
можно переписать так: |
0 |
|
|
|
1 |
|
|
k |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
||
+∞ò ( f€(x) − f (x))xsdx = 0 , |
|
s = 0, 1, 2, …, k. |
|
|
(11) |
||||||||
−∞ |
+∞ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Обозначая |
νs = ò xs f (x)dx , |
перепишем |
равенство |
(11) |
|||||||||
|
−∞ |
|
|
|
|
|
|
|
|
|
|
|
|
следующим образом: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
+∞ |
|
|
|
|
|
|
|
|
|
|
|
|
|
ò xs f€(x)dx =νs , s = 0, 1, 2, …, k. |
|
|
|
(12) |
||||||||
|
−∞ |
|
|
|
|
|
|
|
|
|
|
|
|
Эту систему из (k +1) уравнений называют системой уравнений |
|||||||||||||
моментов. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Если в правой части соотношений |
(12) взять |
выборочные |
|||||||||||
|
|
|
+∞ |
s |
€ |
|
|
|
|
|
|||
моменты ν€s , то |
полученная система ò |
x |
|
|
|
|
|
||||||
|
f (x)dx =ν€s позволяет |
||||||||||||
−∞
решить поставленную задачу.
§ 3. Статистические оценки параметров распределения
Приведем основные характеристики оценок параметра и дадим точечные статистические оценки математического ожидания и дисперсии. Изложим метод интервальной оценки математического ожидания случайной величины с известной дисперсией.
10. Оценки параметров. Состоятельность, несмещенность и эффективность оценки. Как указывалось выше, задачей статистики является описание характера распределения некоторого признака в генеральной совокупности на основании изучения этого признака у некоторой части совокупности (выборки), полученной в результате случайного отбора.
441
При этом распределение относительных частот в выборке рассматривается как эмпирическое приближение к теоретическому распределению вероятностей в генеральной совокупности. Выяснение закона распределения по данным выборки и составляет главную проблему математической статистики, так как на основании закона распределения изучаемого признака можно решать задачи по анализу и предсказанию результатов массового процесса. На практике часто теоретический закон распределения случайной величины в генеральной совокупности известен (или построено его приближенное аналитическое представление), т.е. известно, что закон распределения принадлежит к тому или иному семейству (нормальный закон, закон Пуассона и т.д.), зависящему от одного или нескольких параметров. Если бы точные значения параметров были известны, например, a и σ при нормальном законе, λ при законе Пуассона, то и закон распределения был бы полностью определен. Поэтому именно для определения этих параметров и проводится само статистическое исследование.
На основании закона больших чисел в форме Чебышева можно приближенно найти параметр a (математическое ожидание), положив его равным выборочному среднему. Аналогично можно рассматривать выборочную дисперсию как оценку теоретической дисперсии. Это означает, что будет найдена с некоторым приближением функция нормального закона распределения вероятностей.
Таким образом, задача оценивания неизвестного параметра θ состоит в построении приближенных формул
θ€ θ€(x1, x2 ,K, xn ) .
Функцию θ€= θ€(x1, x2 ,K, xn ) называют выборочной функцией или
статистикой, а ее значение в приближенном равенстве – оценкой. Любая выборка является случайной. Следовательно, все
выборочные функции θ€= θ€(x1, x2 ,K, xn ) также являются случайными.
Поэтому оценку θ€ неизвестного параметра θ будем рассматривать как случайную величину, а ее значение, вычисленное по данной выборке объема n, – как одну реализацию случайной величины.
Оценки параметров подразделяются на точечные и интервальные. Точечная оценка параметра θ определяется одним числом θ€. Интервальная оценка определяется двумя числами θ€1 и θ€2
442
– концами интервала, внутри которого содержится неизвестный параметр θ.
Естественно стремиться, чтобы оценка θ€ была в определенном смысле близка к истинному значению параметра θ.
Как определить близость оценки θ€ к истинному значению θ и как проверить качество этой оценки? С этой целью формулируются определенные требования к статистическим оценкам: состоятельность,
несмещенность и эффективность. Оценка θ€ называется состоятельной, если при увеличении числа испытаний эта оценка сходится по вероятности к истинному значению параметра θ, т.е.
lim P{ |
|
θ€−θ |
|
< ε} =1, где ε – сколь |
угодно малое |
положительное |
|
|
|
||||||
n→∞ |
|
|
|
|
|
|
|
число. |
|
|
|
||||
Свойство |
состоятельности |
является |
обязательным, |
||||
несостоятельные оценки в статистике не используются. |
|
||||||
Оценка θ€ называется несмещенной, если ее математическое |
|||||||
ожидание равно истинному значению, т.е. |
|
||||||
|
|
|
|
|
Mθ€= θ . |
|
(1) |
Это свойство является желательным, но не обязательным. Иногда полученная оценка бывает смещенной, т.е. содержащей систематическую ошибку, но ее можно изменить так, чтобы она стала несмещенной.
Рассматривают также асимптотически несмещенные оценки, т.е. такие,
что Mθ€→θ при увеличении объема выборки.
Наконец, оценка θ€ называется эффективной, если она имеет наименьшую дисперсию по сравнению с другими оценками. Другими
словами, оценка θ€ будет эффективной, если при рассмотрении всех выборок данного объема n она будет иметь минимальную дисперсию.
20. Точечные оценки математического ожидания и дисперсии.
Пусть из генеральной совокупности образуется повторная выборка объема n со значениями признака x1, x2 ,..., xn . Для простоты
рассуждений будем полагать, что эти значения различны. В качестве оценки математического ожидания a генеральной совокупности будем брать выборочное среднее
|
1 |
n |
|
|
x = |
åxk . |
(2) |
||
|
||||
|
n k=1 |
|
||
443