

Тема 2. Методы прогнозирования обратимых процессов
2.1. Краткосрочное прогнозирование обратимых процессов
Средняя величина
При краткосрочном прогнозировании стационарных процессов последовательность данных рассматривается как реализация случайных величин с фиксированным распределением, которые в большинстве случаев считается нормальным с некоторым математическим ожиданием и дисперсией. Прогнозирование в такой ситуации сводится к вычислению математического ожидания, расчёту дисперсии и доверительных интервалов.
Лучшей оценкой математического ожидания для нормального распределения, как вы знаете, является средняя величина. Тогда прогноз на одно наблюдение вперёд будет равен:
|
|
1 |
T |
|
|
|
∑Y t , |
(2.1.1) |
|
Y T 1=Y = |
|
|||
|
|
T t=1 |
|
|
дисперсия в свою очередь считается по формуле:
2 |
= |
1 |
T |
|
2 |
. |
(2.1.2) |
σ |
|
∑ Y t −Y |
|
||||
|
|
T t=1 |
|
|
|
|
|
Зная эти 2 значения легко выполнить краткосрочный прогноз для стационарного процесса. Однако с учётом того, что обычно среднее значение рассчитывается по какой-то выборке наблюдений, а не по всей совокупности, истинное математическое ожидание находится в некотором интервале, который можно определить по формуле:
|
|
tα σ |
|
tα σ |
|
|
||||
Y |
− |
|
|
|
Y Y |
|
|
|
, |
(2.1.3) |
|
|
|
|
|
|
|||||
T |
T |
|||||||||
где |
|
tα |
— t-статистика Стьюдента при заданном уровне доверительной вероятности и |
|||||||
числе наблюдений T. t-статистика Стьюдента используется тогда, когда число |
||||||||||
наблюдений не велико, не превышает несколько десятков. Учитывая то, что с |
||||||||||
увеличением числа наблюдений T значение |
tα уменьшается, а дисперсия стремится к |
|||||||||
своему фактическому значению, следовательно основной путь повышения прогноза — увеличение числа наблюдений.
Рассмотрим пример. Студенты сдают экзамен и на выходе один из студентов собирает информацию для того, чтобы понять, что его может ждать. Выходит 5 человек со следующими оценками:
t |
Оценки |
|
|
2 |
Y t −Y |
Y t −Y |
|||
|
(Yt) |
|
|
|
1 |
3 |
-1 |
1 |
|
|
|
|
|
|
2 |
4 |
0 |
0 |
|
|
|
|
|
|
3 |
5 |
1 |
1 |
|
|
|
|
|
|
25
4 |
4,5 |
0,5 |
0,25 |
|
|
|
|
5 |
3,5 |
-0,5 |
0,25 |
|
|
|
|
|
|
|
|
average |
4 |
sum |
2,5 |
|
|
|
|
tα |
12,92 |
σ 2 |
0,5 |
|
|
|
|
Со статистикой |
Без статистики (t → |
||
|
|
1000) |
|
-0,09 |
8,09 |
3,29 |
4,71 |
|
|
|
|
Похожий принцип с доверительными интервалами работает и в случае, когда мы сталкиваемся и с нестационарными процессами, а в качестве математического ожидания у нас выступает какая-то математическая функция. На семинарских занятиях мы будем рассчитывать доверительные интервалы по более простой, несколько некорректной с точки зрения эконометрии формуле:
Y −σ Y Y σ . |
(2.1.4) |
|
|
|
|
Для наших целей этой формулы должно быть достаточно.
Обращаем ваше внимание на то, что на семинарских занятиях мы будем строить модели, в которых расчётное значение определяется не через среднее значение, а через какую-либо математическую функцию. В таком случае и СКО надо считать как отклонение фактических значений от нашей модели, а не от среднего арифметического.
Однако вернёмся к нашему случаю с нормальным распределением случайных величин. Если мы раскроем знак суммы в формуле (2.1.1), то получим:
|
1 |
Y T |
1 |
Y T −1 ... |
1 |
Y 1 . |
Y T 1= |
T |
T |
T |
|||
|
|
|
|
|||
Здесь |
1 |
- это вес у каждого наблюдения. В данном случае они все равны, но, если |
||||
T |
||||||
мы имеем дело не с нормальным распределением случайных величин или хотим некоторым иным образом дать прогноз, то эти веса могут быть и разными. В таком случае можно использовать следующую формулу для расчёта прогнозного значения:
Y T 1=νT Y T νT −1 Y T −1 ... ν1 Y 1 ,
где νT - вес соответствующего значения YT на наблюдении T.
Авторегрессия
Достаточно часто на практике встречаются стационарные процессы, каждое значение Yt которых определяется предыдущими значениями Yt-1, Yt-2. То есть имеет место авторегрессия, формально описываемая следующей формулой:
|
a1Y t – 1 a2 Y t – 2 ... |
(2.1.5) |
Y t =a0 |
|
26
Для того, чтобы определить, имеется ли в процессе такая зависимость и может ли он быть описан авторегрессионной моделью, осуществляется расчёт коэффициентов автокорреляции, для чего в формулу коэффициента корреляции подставляют попарно значения Y в момент t и те же, но сдвинутые на некоторый шаг τ.
Вспомним, как рассчитывается коэффициент корреляции между двумя переменными
— Xt и Yt:
|
|
T |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
∑ Y t−Y X t −X |
|
|
|
|||
r X t ,Y t |
= |
t =1 |
|
|
|
. |
|
|
|
|
|
|
|||
|
T |
T |
|
|
|||
|
|
|
2 |
|
2 |
|
|
|
|
|
∑ Y t−Y |
∑ X t − X |
|
|
|
|
|
t =1 |
t=1 |
|
|
|
|
Если мы теперь в формулу (2.1.6) вместо Xt подставим Yt-τ, а вместо получим формулу для расчёта автокорреляции для сдвига τ:
|
|
|
T |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
∑ Y t −Y t Y t – τ−Y τ |
|
|
|
|
|
||||||
rY t ,Y t−τ |
= |
t =1 |
|
|
|
|
|
|
|
, |
||
|
|
|
|
|
|
|
|
|
||||
|
|
T |
2 |
T |
|
|
2 |
|||||
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|||||
|
|
|
|
∑ Y t −Y t |
∑ Y t – τ−Y |
τ |
|
|
|
|||
|
|
t =1 |
|
t =1 |
|
|
|
|
|
|
||
|
|
|
1 |
T |
|
|
1 |
|
T – τ |
|||
|
|
|
∑ Y t |
= |
|
|
∑ Y t . |
|||||
где Y t = |
|
|
, Y τ |
T −τ |
||||||||
|
|
|
T −τ t =τ 1 |
|
|
t=1 |
||||||
(2.1.6)
X - Y , то
(2.1.7)
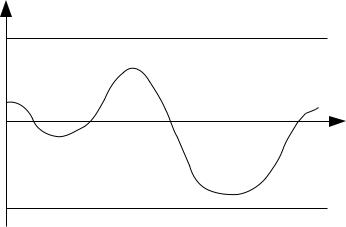
Если при некоем сдвиге τ коэффициент корреляции окажется по модулю не менее 0,8, то говорят о наличии линейной зависимости между значениями самого ряда и ряда, сдвинутого во времени (ряда с лагом). Обычно зависимость коэффициента корреляции от шага τ анализируют графически. Такой график называют коррелограммой (см. Рисунок 7).
rY t ,Y t−τ |
|
1 |
0,87 |
|
|
0 |
|
τ
-0,91
-1
Рисунок 7: Пример коррелограммы
Если, например, оказалось, что коррелограмма имеет два по модулю наибольших значения (например, r5=0,87 и r7=−0,91 ), то исследователь имеет все основания для построения модели авторегрессии вида:
Y t =a5 Y t – 5−a7 Y t – 7 .
27