

Планирование с последовательным прохождением очередей
Если длительность процесса априорно неизвестна, то для того, чтобы оказать предпочтение коротким процессам и повысить за счет этого пропускную способность может быть реализована дисциплина с последовательным прохождением очередей.
Идея данной дисциплины планирования заключается в следующем. Планировщиком организуется несколько очередей готовых процессов с монотонно снижающимися уровнями приоритетов. С каждой очередью сопоставляются временные кванты, которые предоставляются процессам из этих очередей. Причем наиболее приоритетной очереди соответствует минимальный временной квант. Временные кванты монотонно увеличиваются по мере снижения приоритета.
Вновь созданный процесс помещается в наиболее приоритетную очередь планировщика. В результате новому процессу будет быстро предоставлен процессор, но с выделением минимального временного кванта. Если процесс короткий, то он может завершиться даже за малый временной квант и быстро освободить процессор.
Если процесс самоблокировался не доработав временной квант, после выхода из состояния блокировки ему предоставляется возможность доработать остаток временного кванта с тем же приоритетом.
Если процесс не завершился за отведенный ему временной квант, то он снимается с выполнения и переводится в очередь более низкого приоритета, и т.д., пока процесс не завершится или не опустится в очередь минимального приоритета.
Процесс, прошедший все очереди, и не завершившийся, очевидно, не является коротким и для достижения максимальной пропускной способности должен обслуживаться с минимальным приоритетом. В очереди минимального приоритета может быть использована любая дисциплина планирования, например FIFO или RR.
Схема работы дисциплины планирования с последовательным прохождением очередей показана на рис. 7.
Благодаря первоочередному выделению процессора новым процессам, короткие процессы существенно сокращают время ожидания. В тоже время, длительные процессы не откладываются на слишком долгое время.
Дисциплина с последовательным прохождением очередей может с успехом применяться в системах, ориентированных преимущественно на решение вычислительных задач. Например, в операционной системе DEC было представлено три очереди готовых процессов с временными квантами в 0.2, 0.25 и 2 секунды соответственно. Каждому новому процессу было разрешено по одному разу пройти первые две очереди. Если после этого процесс еще не завершался, то он обслуживается в третьей очереди по дисциплине RR вплоть до своего завершения.
В качестве варианта может быть применена дисциплина планирования, допускающая прохождение процесса через каждую очередь по несколько раз, прежде, чем он будет переведен в очередь с меньшим приоритетом.
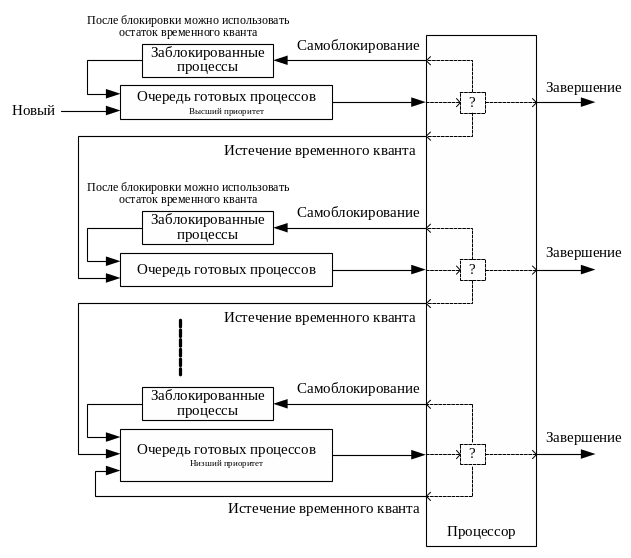
Рис.7. Планирование с последовательным прохождением очередей
Основной недостаток дисциплины планирования с последовательным прохождением очередей состоит в том, что данная дисциплина не учитывает возможное изменение характера процесса во время выполнения. В результате, если процесс из низкоприоритетной очереди войдет в фазу активного ввода-вывода, это не будет учтено планировщиком, что нежелательно.
Следовательно, необходима более гибкая дисциплина планирования, учитывающая не только длительность, но характер исполняемых процессов.