

Комбинированное отображение участков озу в процессорный кэш
Для того, чтобы совместить в одном устройстве достоинства процессорного кэша со случайным отображением и процессорного кэша с детерминированном отображением, была предложена схема комбинированного отображения.
Основная идея состоит в том, чтобы разделить ассоциативную память в составе кэша на несколько банков памяти меньшего объема (несколько каналов кэширования), с возможностью выбирать требуемый банк ассоциативной памяти (канал) по индексу.
Упрощенная схема процессорного кэша, построенного на основе комбинированного отображения участков ОЗУ показана на рис. 53.

Рис.53. Процессорный кэш с комбинированным отображением
Целесообразность использования комбинированного отображения объясняется тем, что реализовать несколько независимых ассоциативных банков памяти оказывается проще и дешевле, чем единый банк ассоциативной памяти суммарного размера.
Процессорный кэш с комбинированным отображением работает следующим образом. Как и в случае детерминированного отображения, адрес данных разделяется на три компоненты – смещение (младшая часть адрес), индекс (средняя часть адреса) и ключ (старшая часть адреса). Однако, в отличие от детерминированного отображения, индекс здесь адресует не запись процессорного кэша, а банк ассоциативной памяти, который, возможно, содержит требуемую запись.
В пределах выбранного банка памяти выполняется стандартный ассоциативный поиск записи по ее ключу, и либо выбираются данные из кэша при совпадении ключа, либо констатируется промах процессорного кэша.
При этом, для эффективной работы кэша, достаточно, чтобы каждый банк памяти содержал небольшое количество записей, порядка десяти. Реализация ассоциативной памяти с таким малым количеством точек входа не представляет особой сложности.
Основное отличие в логике работы комбинированного кэша от детерминированного состоит в том, что теперь в кэш могут одновременно отображаться несколько блоков ОЗУ с одинаковыми индексами, что позволяет оптимизировать замещение данных в процессорном кэше и удерживать в кэше все данные рабочего набора, независимо от их фактического размещения в ОЗУ компьютера. При этом, для выбора замещаемой записи в пределах каждого банка ассоциативной памяти может использоваться любая из рассмотренных ранее стратегий замещения данных, но на практике чаще всего применяется стратегия случайного замещения или стратегия LRU, причем с ростом объема ассоциативных банков памяти или числа каналов кэширования, преимущества стратегии LRU становятся все менее заметными.
Благодаря относительной простоте реализации и достаточно высокой эффективности работы, процессорный кэш на основе комбинированного отображения применяется в большинстве современных процессоров.
Работа процессорного кэша в режиме записи данных
Рассматривая различные варианты архитектуры и работы процессорного кэша, мы не акцентировали внимание на конкретном режиме работы – чтение или запись данных. Между тем, эти режимы существенно различаются. Рассмотрим, как работает кэш при выполнении операций записи данных.
Основной проблемой, с которой приходится сталкиваться при выполнении операций записи, является проблема когерентности (т.е. согласованности) данных между ОЗУ и процессорным кэшем.
Строго говоря, проблема когерентности данных существует при использовании любой многоуровневой памяти, будь это системный дисковый кэш или виртуальная память, но в этих случаях, в отличие от случая процессорного кэша, проблема когерентности решается автоматически – все данные гарантировано проходят через кэш, т.к. прямые обращения к нижележащему уровню памяти невозможны (см. рис. 54), и возможное несовпадение данных в ОЗУ и на диске просто не имеет значения.
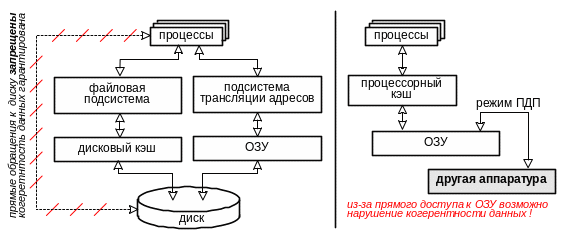
Рис.54. Возможность нарушения когерентности данных при использовании процессорного КЭШа
В случае же процессорного кэша, во многих случаях возможен прямой доступ внешних устройств к данным в ОЗУ минуя процессор, и для поддержания когерентности данных необходимо применять специальные меры. Как минимум, в процессоре необходимо предусмотреть специальную команду для объявления недействительной указанной записи процессорного кэша.
Для упрощения задачи поддержания когерентности данных, в процессорном кэше часто применяется сквозная запись, когда данные одновременно записываются в кэш и в ОЗУ компьютера, а при промахе кэша – только в ОЗУ.
Заметим, что существуют реализации процессорного кэша и с отложенной записью, но они более сложны с точки зрения поддержания когерентности данных, а реальный выигрыш в производительности может быть не столь заметным.
К счастью, при работе реальных программ наблюдается сильная асимметрия между количеством операций чтения и записи данных. На операции чтения обычно приходится не менее 90% всех операций с памятью. В таких условиях процессорный кэш оказывается весьма эффективным, несмотря даже на проблемы с записью.