

Буферизация ввода-вывода на пользовательском уровне
Файловые операции оказывают значительное влияние на скорость выполнения пользовательских процессов. Причем это влияние связано не только с ограниченной скоростью обмена данными с дисковым накопителем, но также с необходимостью выполнения системного вызова для передачи данных:
переключение в режим ядра и обратно, необходимое для выполнения системного вызова, занимает время;
в большинстве случаев процесс, инициировавший системный вызов, снимается с выполнения, и вынужден долго ждать процессор, чтобы продолжить работу.
При этом для большинства пользовательских программ характерны обращения к файлам для чтения или записи нескольких десятков байт. Переход в режим ядра ради удовлетворения такого запроса является слишком дорогим.
Поэтому стандартные библиотеки ввода-вывода современных языков высокого уровня поддерживают собственную буферизацию файлового обмена, которая позволяет сократить число системных вызовов при файловых операциях.
Рассмотрим буферизацию файлового обмена на примере библиотеки стандартного ввода-вывода языка C (заголовочный файл stdio.h).
Ключевым компонентом стандартной библиотеки ввода-вывода C является структура FILE:
struct FILE {
char _ptr; // указатель текущей позиции в буфере
int _cnt; // счетчик остатка (разный смысл при записи и чтении файла)
char *_base; // указатель на начало буфера
int _flag; // флаги состояния потока
int _file; // дескриптор файла
int _bufsiz; // размер буфера (в байтах)
char *_tmpfname; // имя файла, если он открыт как временный
}
При открытии файла средствами стандартной библиотеки ввода-вывода, создается новый экземпляр структуры FILE, и пользовательскому процессу возвращается указатель на него. Указатель на структуру FILE, полученный после открытия файла средствами библиотеки, затем используется при любой операции с этим файлом.
Если буферизация разрешена, то после первой же операции чтения или записи данных, будет создан новый буфер размером BUFSIZE (типично, 4096 байт). Указатель на начало буфера, и другие параметры, необходимые для буферизации данных файла, хранятся в экземпляре структуры FILE.
Структура буфера в режиме чтения файла и записи файла несколько различается. Эти различия поясняются на рис. 48 (режим чтения данных из файла) и рис. 49 (режим записи данных в файл).
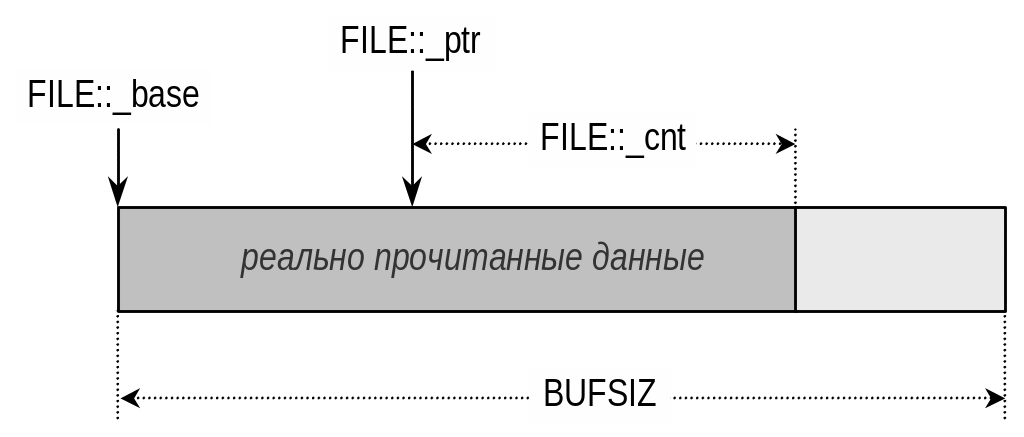
Рис.48. Файловый буфер в режиме чтения файла

Рис.49. Файловый буфер в режиме записи файла
Если запрошена операция чтения, и требуемых данных нет в буфере, то библиотека ввода-вывода автоматически переадресует запрос к операционной системе, и из файла будет прочитан блок данных, соответствующий размеру буфера (или весь файл, если он целиком умещается в буфере). Причем чтение будет выполнено за одно обращение к операционной системе, т.е. за один системный вызов. При последующих запросах пользовательского процесса на чтение очередного символа ему будут передаваться данные из буфера, без обращения к средствам операционной системы. В поле _cnt структуры FILE при этом будет храниться число данных, еще не переданных из буфера пользовательскому процессу.
Если запрошена операция записи, то данные, переданные пользовательским процессом для записи в файл, будут помещены в файловый буфер. Обращение к операционной системе для реальной записи данных в файл будет автоматически сгенерировано библиотекой ввода-вывода в одном из следующих случаев:
буфер заполнен и при попытке размещения в нем новых данных не оказалось свободного места;
пользовательский процесс закрыл файл;
пользовательский процесс явно потребовал сбросить буфер в файл;
пользовательский процесс потребовал изменить режим буферизации или явно назначил новый буфер.
В режиме записи, в поле _cnt структуры FILE храниться число символов, которое еще можно разместить в буфере.
Стандартная библиотека ввода-вывода C поддерживает три режима буферизации:
_IOFBF – режим полной буферизации, как только что рассмотрели, этот режим включается по умолчанию;
_IOLBF – режим построчной буферизации, для работы с текстовыми файлами, при этом, в режиме чтения в буфер считывается блок данных, ограниченный символом перевода строки (строка символов), а в режиме записи буфер сбрасывается в файл, когда в него передается символ перевода строки;
_IONBF – режим отсутствия буферизации, может быть полезен, если обмен с файлом проводится программой крупными блоками, и дополнительная буферизация уже не требуется.