

Стратегии и дисциплины планирования загрузки процессоров
В общем случае,
дисциплина планирования загрузки
процессоров должна некоторым оптимальным
образом перераспределять
![]() готовых к выполнению процессов между
готовых к выполнению процессов между
![]() процессорами, причем
процессорами, причем
![]() ,
иначе решение задачи будет тривиальным
– все процессы смогут выполняться
одновременно.
,
иначе решение задачи будет тривиальным
– все процессы смогут выполняться
одновременно.
Для упрощения
изложения, в дальнейшем будем предполагать
однопроцессорную систему (![]() ),
при этом все полученные результаты и
выводы будут справедливы и для
многопроцессорной конфигурации. Частные
же особенности планирования загрузки
процессоров в многопроцессорных системах
будут рассмотрены отдельно.
),
при этом все полученные результаты и
выводы будут справедливы и для
многопроцессорной конфигурации. Частные
же особенности планирования загрузки
процессоров в многопроцессорных системах
будут рассмотрены отдельно.
Дисциплина планирования загрузки процессоров, как и любая другая дисциплина управления, реализует некоторую стратегию. Рассмотрим наиболее распространенные стратегии и наиболее известные дисциплины их реализации.
Стратегия одинакового среднего времени ожидания
Под временем ожидания понимается суммарное время, которое процесс провел в состоянии готовности к выполнению, ожидая выделение процессора. Стратегия одинакового среднего времени ожидания требует обеспечить равенство времени ожидания для всех исполняемых процессов.
Данная стратегия реализуется дисциплиной планирования FIFO (First Input – First Output – Первым вошел – первым вышел). Рассмотрим ее более внимательно.
Дисциплина планирования fifo
Дисциплина FIFO является одной из простейших дисциплин планирования. Она организует очередь готовых к выполнению процессов в порядке их появления в состоянии готовности. Дисциплина FIFO также известна под названием FCFS (First Come – First Served – Первым пришел – первым обслужился).
Дисциплина FIFO реализует планирование без переключения. Таким образом, если некоторой процесс получит в свое распоряжение процессор, то он будет выполняться до полного завершения или до перехода в состояние блокировки.
Схема работы дисциплины FIFO показана на рис. .3.
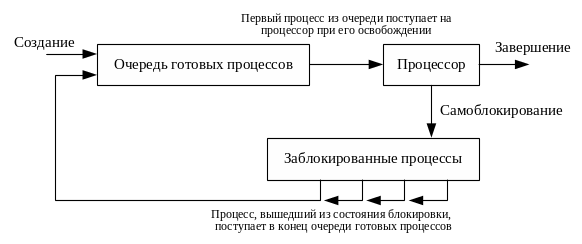
Рис.3. Планирование по принципу FIFO.=
Основными преимуществами дисциплины FIFO являются:
простота реализации;
не требуется какой-либо априорной информации о процессах;
хорошо предсказуемое время ожидания для каждого конкретного процесса.
В тоже время, дисциплине FIFO присущи определенные недостатки, сдерживающие ее применимость:
дисциплина FIFO, как и любая другая дисциплина без переключения, неприменима для интерактивных процессов;
при использовании дисциплины FIFO короткие и длинные процессы ждут одинаковое время, что снижает пропускную способность системы, поскольку короткие процессы выгоднее завершать первыми.
Справедливая стратегия
Данная стратегия предполагает выделение одинаковой величины процессорного времени всем исполняющимся процессам. Для реализации этой стратегии может быть предложена дисциплина, основанная на явном подсчете времени выполнения для каждого процесса. Однако такое решение ведет к дискриминации долго работающих процессов, т.к. вновь поступивший процесс, имеющий нулевое время выполнения, сразу же и надолго займет процессор. В результате дисциплина получается несправедливой (в смысле возможности бесконечного откладывания процесса) и слабо предсказуемой. Поэтому на практике существенно большее распространение получила квазиоптимальная дисциплина, известная под названием RR (Round Robin – Циклическое планирование).