

Бригадное планирование процессов в многопроцессорной системе
Бригадное планирование ориентировано для работы в составе многопроцессорных систем, в которых для реализации параллельных вычислений поддерживается множество потоков в рамках одного процесса. При этом число потоков в каждом процессе не должно превышать число процессоров. Основная идея бригадного планирования состоит в том, чтобы согласовать выполнение потоков одного и того же процесса. Когда планировщик ставит на выполнение процесс, он в любом случае ставит на выполнение все его потоки, независимо от их готовности.
Процесс может выполняться, например, в течение некоторого заранее определенного кванта времени, или до появления в системе нового, более приоритетного процесса. В наиболее жестком варианте бригадного планирования используется не вытесняющее планирование, т.е. процесс выполняется вплоть до завершения.
Если после размещения процесса на выполнение в системе еще остались свободные процессоры, то можно попытаться распланировать другой процесс и т.д.
Очевидно, что при использовании бригадного планирования коэффициент загрузки процессоров будет небольшим, многие процессоры будут простаивать в ожидании готовности потока, назначенного на процессор. Но при наличии большого числа процессоров в системе меняются стратегические цели – вместо максимальной загрузки процессора пытаются достичь максимальной пропускной способности. А при наличии большого числа процессоров очередь готовности продвигается довольно быстро даже при использовании дисциплин без переключения.
Возможный выигрыш в производительности, достигаемый от бригадного планирования объясняется следующим. В многопотоковых процессах, выполняющих параллельно некоторые вычисления, потоки, как правило, являются взаимосвязанными. Выполнив некоторую часть работы над общими данными, поток часто должен дождаться завершения действия параллельного потока. Если такая межпотоковая синхронизация требуется относительно часто, то накладные расходы на снятие/постановку потока на выполнение могут быть весьма значительными. При наличии большого числа процессоров зачастую оказывается выгоднее, если поток дождется возможности продолжить работу на процессоре. Кроме того, потоки при этом оказываются прикреплены к процессорам, что позволяет эффективно использовать процессорный кэш. Наконец, совместная работа потоков одного процесса создает благоприятные условия для работы системного кэша ввода-вывода и виртуальной памяти, что также хорошо сказывается на общей производительности системы.
2.6 Синхронизация выполнения процессов
Синхронизация выполнения процессов – одна из наиболее важных задач управления процессами, решаемая в многозадачных операционных системах. Задача синхронизации возникает при взаимодействии процессов – прямом или опосредованном, через разделяемые ресурсы.
Например, один процесс (писатель) помещает данные в разделяемый буфер с целью передачи их другому процессу (читателю). Писатель не должен повторно записывать данные в буфер, пока старые данные из буфера не прочитаны читателем, иначе старые данные будут потеряны. С другой стороны, читатель не должен повторно читать данные из буфера, пока они не будут обновлены писателем. Поскольку планировщик переключает процессы по своим собственным критериям, не синхронизируя моменты переключения с выполнением прикладных программ, согласованная работа читателя и писателя не будет достигнута автоматически, необходимо будет предусмотреть специальную процедуру их синхронизации.
Рассмотрим более сложный пример – совместный доступ к разделяемому ресурсу со стороны нескольких процессов, для определенности, пусть это будет простейший односвязный список, показанный на рис. 12.
Каждый элемент списка хранит адрес следующего элемента в поле next (рис. 12a): 2 = 1->next, 3 = 2->next и т.д.
Процессы могут искать, добавлять или удалять элементы списка. Пусть требуется добавить в список четвертый элемент после первого. Процесс, включающий в список новый элемент, должен сделать следующие действия:
создать элемент 4;
присвоить 4->next = 1->next;
присвоить 1->next = 4.
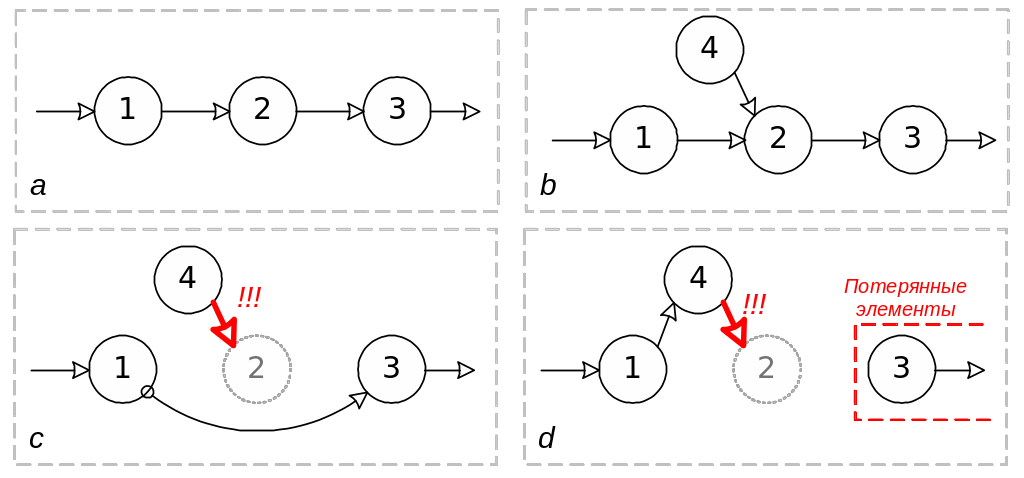
Рис.12. Исключение элемента из списка
Вспомним теперь, что в многозадачной операционной системе планировщик может в любой момент снять процесс с выполнения. При этом процесс, включающий в список четвертый элемент, может быть снят с выполнения после выполнения первого и второго действия, не успев выполнить третье. Тогда список окажется в состоянии, показанном на рис. 12b.
Пусть теперь другой процесс, который получил управление, решил удалить из списка элемент 2. Для этого необходимо сделать следующие действия:
присвоить 1->next = 2->next (обойти элемент 2);
удалить элемент 2.
Теперь список будет в состоянии, показанном на рис. 12c. Заметим, что элемент 4 ссылается на удаленный (не существующий) элемент 2.
Пусть теперь управление вернулось к первому процессу. Он возобновляет работу и завершает вставку элемента 4 в список, выполняя третье действие. В результате список будет в состоянии, показанном на рис. 12d. Элементы 3 и далее потеряны, на них больше нет ссылок. Элемент 4 ссылается на несуществующий элемент 2. Такое состояние списка, скорее всего, приведет к аварийному завершению любого процесса, выполнившего попытку обращения к списку.
Как видно, проблема состоит в том, что операция вставки элемента в список не является атомарной, она требует нескольких действий, и пока вставка не будет завершена, другие действия над списком недопустимы. Операции над разделяемым ресурсом, во время выполнения которых другие действия над этим ресурсом недопустимы, называются критическими операциями. Ресурсы, доступ к которым сопряжен с критическими операциями, называются критическими ресурсами, а участки программ, из которых выполняется доступ к критическим ресурсам, называются критическими секциями.
Режим синхронизации, при котором только один из процессов может получить доступ к разделяемому ресурсу, называется взаимоисключением.
В любой реальной компьютерной системе всегда представлено множество критических ресурсов. Заметим, что ресурсы, критические по одним видам доступа, например, по записи данных, могут оказаться не критическими по другим видам доступа, например по чтению.
На практике, задача синхронизации процессов сводится к тому, чтобы гарантировать, что в любой момент времени в критической секции, связанной с определенным критическим ресурсом, будет находиться не более одного процесса. Так как скорость выполнения программ в многозадачных системах непредсказуема, то нельзя полагаться на какой-то априорно определенный порядок входа в критические секции. Для реализации взаимоисключений необходим специальный системный механизм, который приостанавливал бы выполнение процессов перед критической секцией, если в ней уже находится программа другого процесса, а после ее выхода из критической секции – пробуждал бы эти процессы.
Общепринятым здесь является следующий подход:
перед входом в критическую секцию программа информирует операционную систему о своем намерении войти в критическую секцию посредством специального системного вызова;
если критическая секция свободна, то системный вызов быстро завершается и программа продолжает свою работу в критической секции; если же критическая секция занята – то системный вызов не завершится до освобождения критической секции, т.о. программа дождется освобождения критической секции;
при выходе из критической секции программа информирует об этом операционную систему посредством специального системного вызова, чтобы она могла разрешить вход в критическую секцию другой программе.
Таким образом, границы критических секций отслеживаются самими программами, а операционная система гарантирует взаимоисключение при входе в них, реализую тот или иной алгоритм взаимоисключений. При этом, к алгоритмам взаимоисключений предъявляются следующие требования:
алгоритм должен реализовывать взаимоисключение, т.е. должна исключаться возможность входа в критическую секцию нескольких процессов одновременно;
алгоритм должен исключать бесконечное откладывание для любого из процессов, ожидающих входа в критическую секцию;
алгоритм не должен полагаться на порядок или скорость выполнения процессов.
Практическая реализация алгоритма взаимоисключений является сложной нетривиальной задачей. Рассмотрим основные подходы, которые могут быть при этом использованы.