

Управление резидентным множеством страниц процесса
Важнейшим положительным моментом использования виртуальной памяти является тот факт, что при ее наличии процессы могут выполняться, будучи только частично загруженными в ОЗУ компьютера. Память процесса разделяется на страницы, и для исполнения программы достаточно отобразить на ОЗУ только часть из них.
Множество страниц виртуального адресного пространства процесса, для которых в данный момент времени установлено отображение на ОЗУ компьютера, называется резидентным множеством страниц процесса.
Подсистема виртуальной памяти осуществляет постоянное управление резидентным множеством каждого процесса, пытаясь достичь его оптимального размера. При этом существуют определенные предпосылки как для увеличения, так и для уменьшения резидентного множества страниц процесса:
резидентное рабочее множество следует уменьшать, потому, что при уменьшении резидентного множества увеличивается число одновременно запущенных процессов, следовательно, вероятность простоя процессора из-за отсутствия готовых процессов снижается;
резидентное множество следует увеличивать, потому, что при увеличении резидентного множества снижается вероятность страничного отказа, следовательно, снижаются общие накладные расходы на подкачку страниц и время простоя конкретных процессов в ожидании подкачки страниц.
От того, насколько эффективно удастся достичь компромисса в размере резидентного множества, существенно зависит общая производительность компьютера.
Понятие рабочего множества страниц процесса
Понятие рабочего множества впервые было введено Деннингом в конце 60-х, и в последующем сыграло решающую роль в становлении системы виртуальной памяти.
Рабочее множество страниц некоторого процесса это тот набор страниц, с которыми процесс работал в последнее время. Безусловно, с течением времени рабочее множество постоянно меняется, кроме того, состав рабочего множества зависит и от времени наблюдения, действительно, что считать «последним временем».
Количественно,
рабочего множество страниц процесса
определяется следующим образом. Рабочее
множество
![]() в момент времени
в момент времени
![]() включает в себя все страницы памяти, к
которым процесс выполнил хотя бы одно
обращение на интервале времени
включает в себя все страницы памяти, к
которым процесс выполнил хотя бы одно
обращение на интервале времени
![]() .
.
Безусловно, в
приведенном определении по-прежнему
сохраняется неоднозначность: фактический
размер рабочего множества зависит от
неопределенной величины
![]() ,
но в данный момент для нас больший
интерес представляет качественный
характер поведения
как функции времени, к количественным
же характеристикам мы вернемся несколько
позже.
,
но в данный момент для нас больший
интерес представляет качественный
характер поведения
как функции времени, к количественным
же характеристикам мы вернемся несколько
позже.
Если для некоторого процесса построить график зависимости величины рабочего множества от времени при различных , то получатся результаты, качественный характер которых показан на рис. 36.
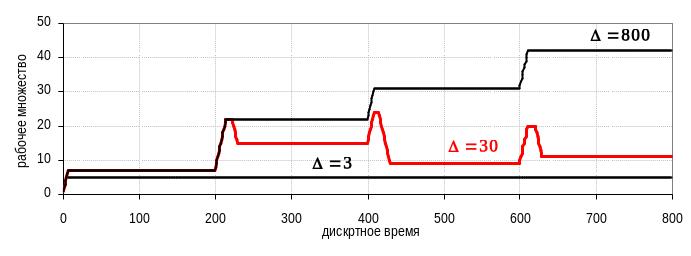
Рис.36. Рабочие множества для разных окон наблюдения
Наибольший практический интерес представляет график, полученный при среднем значении . Он показывает, что при работе процесса существуют временные интервалы стабильности, в течение которых рабочее множество практически не изменяется. Чтобы заметить эти области стабильности, надо, чтобы интервал был много меньше интервала стабильности, но достаточно большим, чтобы за это время процесс успел хотя бы раз обратиться к каждой странице рабочего множества.
На практике, в каждом интервале стабильности, процесс работает с десятками, может быть, сотнями страниц, в то время как интервал стабильности сохраняется на протяжении сотен тысяч или даже миллионов обращений к памяти. Поэтому выбрать подходящий интервал не составляет особого труда.
Отслеживание рабочего множества страниц исполняющихся процессов, позволяет подсистеме замещения оптимальным образом поддерживать резидентный набор для каждого из запущенных процессов.