

Мониторы
Семафоры позволяют эффективно реализовать взаимоисключения, но их применение, особенно в сложных программах, не вполне удобно. Системные вызовы wait() и release() быстро распределяются по всей программе, и их корректное использование не может быть гарантировано автоматически. Например, совсем непросто проверить, что системному вызову wait() при входе в критическую секцию всегда соответствует системный вызов release() при выходе из нее, особенно если в программе есть ветвления, и возможны альтернативные входы-выходы в критические секции.
Это приводит к трудно обнаруживаемым ошибкам, существенно усложняет процесс программирования и отладки. Для решения этой проблемы, в 1974 году Хоар (Hoare) предложил альтернативную концепцию реализации взаимоисключений – монитор. Идея монитора была усовершенствована Лемпсоном (Lampson) и Ределлом (Redell) в 80-х годах XX века и мониторы получили достаточно широкое распространение.
Монитор представляет собой программный модуль, объединяющий данные и процедуры доступа к ним, причем доступ к данным возможен только через процедуры монитора. Процесс, выполняющий процедуру монитора, считается вошедшим в монитор. Процедуры монитора должны быть организованы так, чтобы находиться в мониторе мог бы только один процесс, т.е. пока выполняется любая процедура монитора, доступ к другим процедурам монитора и повторный вход в исполняемую процедуру, должны быть блокированы.
Монитор предусматривает доступ к данным по условиям. Для каждой процедуры монитора должно быть определено условие, при выполнении которого разрешен доступ к данным через эту процедуру. С каждым условием должна быть сопоставлена очередь заблокированных процессов. Начав выполнение процедуры монитора, процесс проверяет условие доступа к данным, и если оно не выполняется, процесс блокируется, и ссылка на него сохраняется в соответствующей очереди.
После блокировки процесса монитор освобождается и в него может войти другой процесс. Условия доступа к данным должны быть согласованы таким образом, чтобы доступ к данным был бы разрешен хотя бы через одну процедуру монитора.
Если после манипуляции с данными монитора процесс обнаружит, что стал возможен доступ к данным по какому-либо ранее не выполняющемуся условию, он должен деблокировать процесс из очереди соответствующего условия.
Заметим, что в отличие от семафоров и спин-блокировок, монитор является не просто средством синхронизации процессов, но и контейнером для хранения данных, поэтому его реализация более целесообразна не на уровне операционной системы, а в языке программирования. Но при наличии в операционной системе семафоров, монитор несложно реализовать на пользовательском уровне.
Для реализации монитора требуется один семафор для взаимоисключающего доступа к процедурам монитора и по одному семафору на каждое условие для приостановки процессов в ожидании разрешения доступа к данным.
Процедура монитора может быть реализована по алгоритму, показанному на рис..16. При этом семафор монитора Sm должен быть инициализирован так, чтобы только один процесс мог бы пройти через него (начальное значение счетчика семафора равно 1), а семафоры условий S[] необходимо инициализировать с нулевыми значениями счетчика, чтобы при попытке пройти семафор, процесс сразу блокировался. Предполагается, что процедуры WaitForSyncObject() и ReleaseSyncObject() реализованы по алгоритмам рис. 14 и рис.15 соответственно.
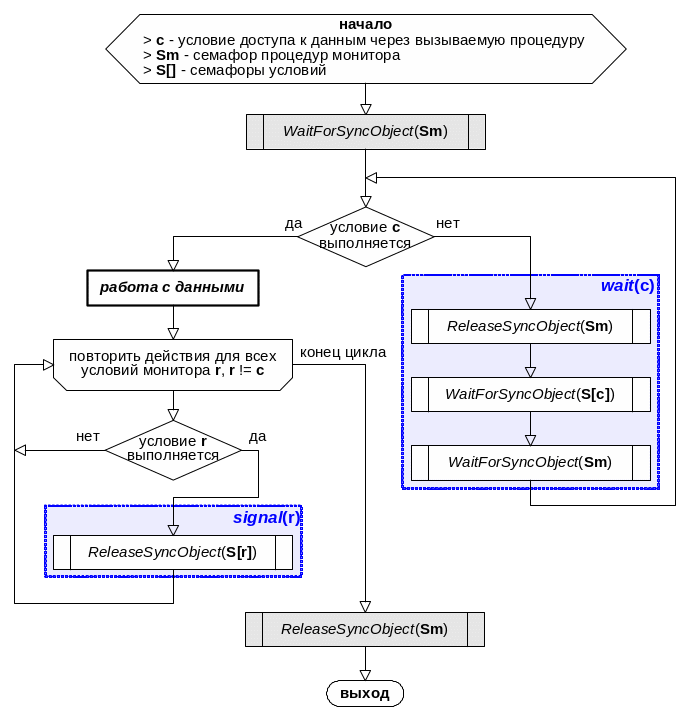
Рис.16. Алгоритм процедуры монитора
Рассмотрим блок-схему, показанную на рис. .16, более внимательно. Закрашенные на рисунке серым цветом стандартные процедуры WaitForSyncObject() и ReleaseSyncObject(), вызываемые соответственно в начале и в конце процедуры монитора, не зависят ни от алгоритма доступа к данным ни от типа данных, ни от условий доступа и могут автоматически внедряться в код программы компилятором.
Выделенная на рисунке последовательность вызовов стандартных процедур ReleaseSyncObject(Sm), WaitForSyncObject(S[c]), WaitForSyncObject(Sm), обычно оформляется в компиляторе в виде библиотечной функции wait(условие), которая переводит текущий процесс в состояние ожидания выполнения указанного условия (в алгоритме на рис. .16 условия c) и освобождает монитор.
Выделенный на рисунке вызов стандартной процедуры ReleaseSyncObject(S[r]) обычно оформляется в виде библиотечной функции signal(условие), которая пробуждает процесс из очереди, связанной с условием r.
Программа доступа к очереди через монитор, с учетом сказанного, может быть записана в стиле языка программирования, поддерживающего мониторы, следующем образом.
Monitor Queue { // защищенные данные монитора QUEUE queue; // условия доступа к данным монитора CONDITION queueNotEmpty, queueNotFull; // процедура записи данных в очередь // не может работать, если очередь заполнена PushData(data) { // проверяем условие доступа к данным // если очередь заполнена – ждем условия while(queue.length() > MAX_LEN) { wait(queueNotFull); } // помещаем данные в очередь queue.push(data); // сигнализируем, что очередь не пуста signal(queueNotEmpty); } // процедура извлечения данных из очереди // не может работать, если очередь пустая PopData(data) { // проверяем условие доступа к данным // если очередь пустая – ждем условия while(queue.length() = 0) { wait(queueNotEmpty); } // получаем данные из очереди data = queue.pop(); // сигнализируем, что очередь не заполнена signal(queueNotFull); } }
Мониторы оказались удобным средством для работы с разделяемыми данными, и быстро получили распространение. В 80-е гг. XX века они были включены в состав некоторых языков программирования. Однако по мере развития техники объектно-ориентированного программирования выяснилось, что монитор при необходимости довольно легко реализовать при помощи обычных семафоров.
Поэтому в наиболее мощных современных языках программирования (например, C++) нет встроенных мониторов – при необходимости их легко определить самостоятельно.