

Алгоритм с переменным пробным интервалом – дисциплина vsws
Дисциплина VSWS (Variable-interval Sampled Working Set) ликвидирует основной недостаток дисциплины PFF – неоправданное увеличение резидентного набора процессов при смене рабочего множества. При этом сложность практической реализации по-прежнему остается вполне приемлемой.
Сущность дисциплины VSWS состоит в следующем. Всякий раз, при возникновении прерывания по отсутствию страницы, к резидентному множеству процесса, вызвавшего прерывание, добавляется новый страничный кадр. Следовательно, по ходу исполнения программы резидентное множество процесса растет.
Время от времени резидентное множество процесса сокращается за счет исключения из него страничных кадров, у которых не установлен бит обращения. Одновременно с этим, сбрасывается бит обращения у страничных кадров, оставшихся в резидентном множестве. Если к моменту следующей проверки у каких-то страничных кадров бит обращения не будет установлен, то они выбывают из рабочего набора.
Основное отличие дисциплины VSWS от дисциплины PFF состоит в том, что проверка битов обращения и сокращение резидентного набора проводится не периодически, а через неравные интервалы времени.
Проверка битов обращения и сокращение резидентного набора инициируется при выполнении хотя бы одного из следующих двух условий:
процесс инициировал более
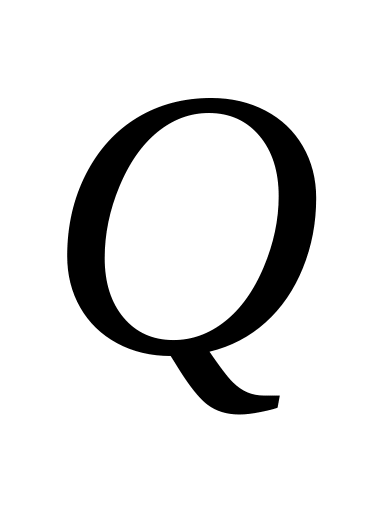 страничных прерываний, где
наперед заданное число: проверка
выполняется, если после последней
проверки истек минимальный интервал
времени
;
страничных прерываний, где
наперед заданное число: проверка
выполняется, если после последней
проверки истек минимальный интервал
времени
;с момента последней проверки истек предельный интервал времени
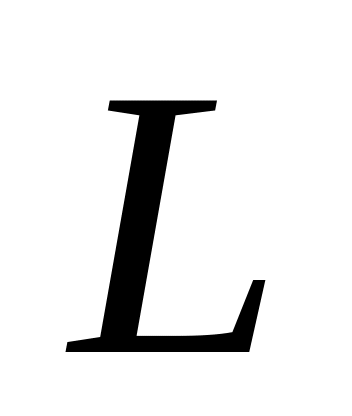 :
проверка выполняется независимо от
числа прерываний.
:
проверка выполняется независимо от
числа прерываний.
При этом значения
параметров
![]() ,
,
![]() и
и
![]() выбирают таким образом, чтобы проверка
преимущественно запускалась сразу
после возникновения
страничных прерываний, а временные
интервалы
и
предназначены больше для особых ситуаций.
выбирают таким образом, чтобы проверка
преимущественно запускалась сразу
после возникновения
страничных прерываний, а временные
интервалы
и
предназначены больше для особых ситуаций.
Преимущество дисциплины VSWS перед дисциплиной PFF состоит в том, что в моменты перехода программы от одного стабильного рабочего набора к другому, когда чаще возникают страничные прерывания, дисциплина VSWS чаще инициирует сокращение резидентного набора, не допуская его неоправданного роста.
Влияние размера страницы
По ходу изложения материала, мы не один раз отмечали преимущества страничной организации виртуальной памяти, однако, вопрос об оптимальном размере страницы не затрагивался до настоящего времени. Следует ли стремиться к увеличению или уменьшению размера страницы? На практике, можно указать аргументы как за, так и против увеличения размера страницы:
аргументы «за»:
размер страницы следует увеличивать, так как это сокращает размер таблицы трансляции адресов и, следовательно, сокращает потери первичной памяти;
размер страницы следует увеличивать с целью сокращения числа обменов с дисковым накопителем. При работе с диском выгодно передавать как можно больше данных за одно обращение к диску;
размер страницы следует увеличивать, так как при больших страницах реже будут происходить промахи при обращении к страницам, следовательно, менее интенсивной будет подкачка страниц;
аргументы «против»:
размер страницы следует уменьшать, так как при больших страницах целая страница оказывается загруженной ради небольшой части ее данных;
размер страницы следует уменьшать, так как реальные структуры данных обычно не выровнены на размер страницы, и в каждом сегменте в среднем теряется половина страницы.
Таким образом, при реализации виртуальной памяти необходимо искать компромиссный размер страницы. При этом труднее всего искать компромисс между размером страниц в сегменте кода и сегменте данных процесса. Для сегмента кода оптимальный размер страницы должен быть существенно больше, чем для сегмента данных. Действительно, при выполнении программы, изменение рабочего набора происходит целыми процедурами (началось выполнение процедуры – целесообразно перенести в ОЗУ весь ее код, закончилось – весь выгрузить), а их размер довольно значительный, десятки и сотни килобайт. С областями же данных удобнее работать более мелкими страницами.
Для решения отмеченной проблемы многие современные процессоры поддерживают возможность одновременной работы со страницами различного размера. При этом, для каждого сегмента виртуальной памяти можно выбрать из страниц какого размера он будет состоять. Типичный размер страницы современных процессоров лежит в диапазоне 0.5…8 Кбайт для малых страниц и в диапазоне 2…4 Мбайт для больших страниц.