

Страничная организация виртуальной памяти
Страничная организация виртуальной памяти позволяет решить проблему внешней фрагментации ОЗУ. Она реализуется даже проще сегментной организации. Основная идея состоит в том, чтобы выделять память только блоками одинакового размера.
При использовании страничной организации, виртуальное адресное пространство разбивается на блоки одинакового размера – страницы (pages). Физическое адресное пространство ОЗУ разбивается на такие же блоки – страничные кадры (page frames).
Задача системы трансляции адресов при этом сводится к установлению однозначного соответствия между страницами и страничными кадрами. При этом записи таблицы отображения могут иметь следующую структуру (рис. 31).
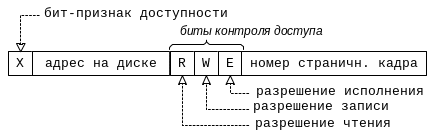
Рис.31. Структура записи в таблице отображения при страничной организации
Ввиду того, что
размеры всех страниц и страничных кадров
одинаковы, можно сократить размер записи
в таблице отображения: вместо физического
адреса хранить в таблице номер страничного
кадра (PFN). Физический
адрес начала страницы
![]() при необходимости можно будет легко
вычислить по формуле (0).
при необходимости можно будет легко
вычислить по формуле (0).
![]() (
0 )
(
0 )
Заметим, что в силу одинакового размера страничных кадров, внешняя фрагментация ОЗУ возникнуть не может, но опять же в силу одинакового размера страниц, возникает внутренняя фрагментация. Сущность внутренней фрагментации состоит в том, что не все выделенные страницы полностью используются программами.
Например, пусть в некоторой системе используются страницы, размером 4 K. Пусть теперь некоторой программе требуется разместить массив, размером 1.8 K. В силу фиксированного размера страницы, ей будет выделено 4 K памяти, при этом 2.2 K не будет использовано программой. Это и есть потери на внутреннюю фрагментацию.
На практике, потери на внутреннюю фрагментацию обычно оказываются существенно меньшими, чем потери на внешнюю фрагментацию при сегментной организации.
Однако, страничная организация также имеет свой недостаток. Если даже программа выделяет для хранения некоторой структуры данных или участка кода сразу несколько страниц, система виртуальной памяти никак не учитывает это, и поэтому не может оптимизировать работу ни по совместному доступу, ни по защите, ни по хранению.
В современной многозадачной операционной системе, где совместное использование участков программного кода и межпрограммное взаимодействие играют важнейшую роль, отмеченный недостаток оказывается весьма существенным.
Сегментно-страничная организация виртуальной памяти
Сегментно-страничная организация виртуальной памяти сочетает достоинства страничной и сегментной организации. Однако переход к такой организации требует усложнения подсистемы трансляции адресов. Виртуальный адрес теперь должен состоять не из двух, а из трех компонентов: номера сегмента, номера страницы внутри сегмента и смещения внутри страницы. На рис. 32 показана структурная схема подсистемы трансляции адресов с ассоциативным буфером трансляции при сегментно-страничной организации виртуальной памяти.

Рис.32. Трансляция адреса при сегментно-страничной организации памяти
Основная идея заключается в том, чтобы разбить сегменты виртуального адресного пространства на страницы с возможностью произвольного отображения этих страниц на страничные кадры ОЗУ, как показано на рис. 33.

Рис.33. Структура адресного пространства при сегментно-страничной организации
Таким образом, сегментно-страничная организация, с одной стороны, поддерживает сегментную организацию виртуального адресного пространства, что упрощает защиту и совместный доступ к данным, а с другой стороны, позволяет использовать несвязное распределение физической памяти, исключая внешнюю фрагментацию, как в ОЗУ, так и в страничном файле на дисковом накопителе.