

Оптимизация списка свободных блоков
Наиболее простым и в то же время весьма эффективным способом оптимизации структуры списка свободный блоков является метод парных меток, рассмотрим его.
Метод парных меток для поддержания списка блоков кучи
Операция слияния освобождаемых блоков памяти выполнялась бы гораздо проще, если бы список свободных блоков был бы упорядочен по их адресам с возможностью быстрого доступа к соседним, относительно освобождаемого блока, блокам.
Существует простое и эффективное решение для организации такого упорядоченного списка, известное как метод парных меток. При этом, вместо традиционного списка свободных блоков кучи, поддерживается единый упорядоченный двусвязный список свободных и занятых блоков кучи.
Структура списка свободных и занятых блоков, построенного методом парных меток, показана на рис. 56.
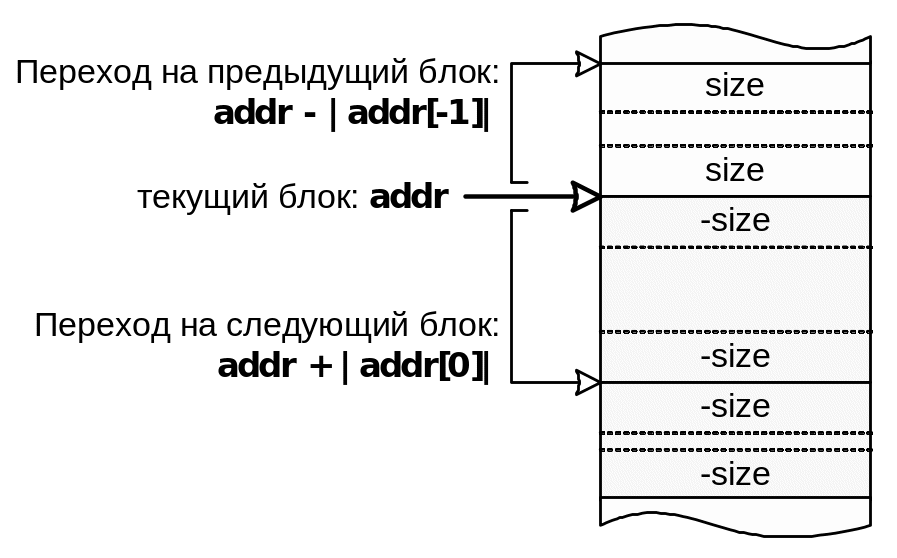
Рис.56. Организация списка по методу парных меток
Организация списка по методу парных меток приводит к незначительным накладным расходам памяти кучи, т.к. в начале и в конце каждого блока требуется хранить его размер, причем для занятых блоков размер берется со знаком "минус", что служит индикатором занятости блока. Но, получаемый выигрыш в простоте и эффективности освобождения памяти, перекрывает эти накладные расходы.
Теперь, имея адрес начала произвольного блока, и используя информацию о размере блоков, легко рассчитать адреса предшествующего или последующего блоков.
Адрес предшествующего
блока определяется по формуле
![]() ,
где
,
где
![]() - адрес текущего блока. Взятие модуля
необходимо на случай, если предыдущий
блок занят, и его размер хранится как
отрицательное число.
- адрес текущего блока. Взятие модуля
необходимо на случай, если предыдущий
блок занят, и его размер хранится как
отрицательное число.
Адрес следующего
блока определяется по формуле
![]() .
.
Алгоритм освобождения блока памяти с автоматическим объединением примыкающих блоков при использовании метода парных меток для организации списка, может быть, например, следующим (см. рис. 57).
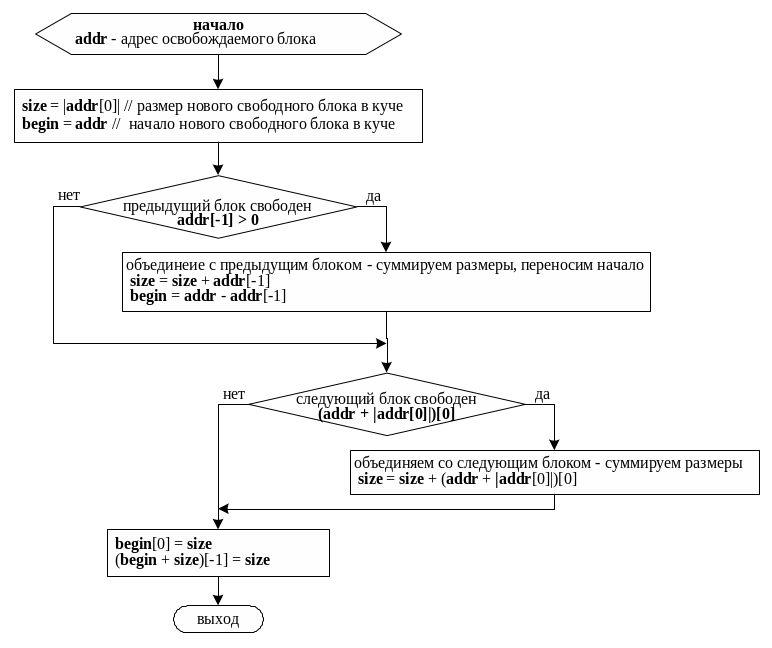
Рис.57. Алгоритм освобождения памяти при использовании для организации списка блоков метода парных меток
Данный алгоритм освобождения памяти может быть очень просто реализован на любом языке программирования, например, реализация данного алгоритма на языке C выглядит следующим образом.
void free(void *block) { // переходим на начало блока управления памятью __int32 *p = ((__int32*)block) - 1; // снимаем признак занятости блока в первой метке *p = –*p; // если предыдущий блок свободен – // выполняем слияние с ним // если следующий блок свободен – // выполняем слияние также и с ним if (p[–1] > 0) {p –= p[–1]; *p += p[*p];} if (p[*p] > 0) *p += p[*p]; // копируем первую метку во вторую метку // в конце блока p[*p – 1] = *p; }
В приведенной программе учитывается, что пользователи под адресом начала блока понимают адрес, начиная с которого они могут размещать свои данные. Нам же, перед началом освобождения памяти, необходимо переместить этот адрес на фактическое начало блока, определяемое структурой списка по методу парных меток.
Специальные алгоритмы динамического распределения памяти из кучи
Метод первого подходящего, реализованный на базе списка с использованием метода парных меток, оказывается достаточно эффективным и универсальным решением. Но в некоторых случаях, например в ядре операционной системы, или при решении задач реального времени, скорость выделения/освобождения блоков памяти приобретает первостепенное значение, так, что можно даже смириться с некоторым увеличением фрагментации памяти, в сравнении с методом первого подходящего.
Существует несколько оптимизированных алгоритмов динамического распределения памяти, способных существенно повысить быстродействие в частных случаях.