

Метод расщепление цикла
Достаточно часто выполнение цикла сводится к простому повторению определенных действий над некоторыми независимыми данными с независимым сохранением результатов каждой итерации, например, как показано в следующем фрагменте кода.
for (i = 0; i < N; ++i) A[i] = B[i] + C[i];
Очевидно, что подобный цикл может быть легко разделен на два независимых цикла следующим образом:
for (i = 0; i < N/2; ++i) A[i] = B[i] + C[i];
for (i = N/2; i < N; ++i) A[i] = B[i] + C[i];
При наличии двух процессоров, оба цикла могут выполняться одновременно. При наличии большего числа процессоров, цикл легко разделит на большее количество независимых более коротких циклов. В этом и состоит идея расщепления цикла.
Расщепление цикла очень легко явно реализовать в программе, при этом может быть получен весьма ощутимый выигрыш в скорости работы.
Метод редукции высоты дерева
Скрытую возможность распараллеливания вычислений зачастую можно обнаружить в простых арифметических выражениях. Обычно компиляторы раскрывают арифметические выражения, основываясь только на приоритетах операций: сначала операции в скобках, затем операции умножения и деления и, наконец, операции сложения и вычитания. В результате определяется последовательный порядок действий для нахождения результата.
Однако, используя коммутативные и ассоциативные свойства арифметических выражений можно в ряде случаев перейти к параллельным вычислениям.
Например, рассмотрим
следующее выражение
![]() .
Обычный порядок действий при его
вычислении показан на рис. 11 слева.
.
Обычный порядок действий при его
вычислении показан на рис. 11 слева.
Однако, указанное
выражение можно переписать как
![]() и выполнить, как показано на рис. 11
справа.
и выполнить, как показано на рис. 11
справа.
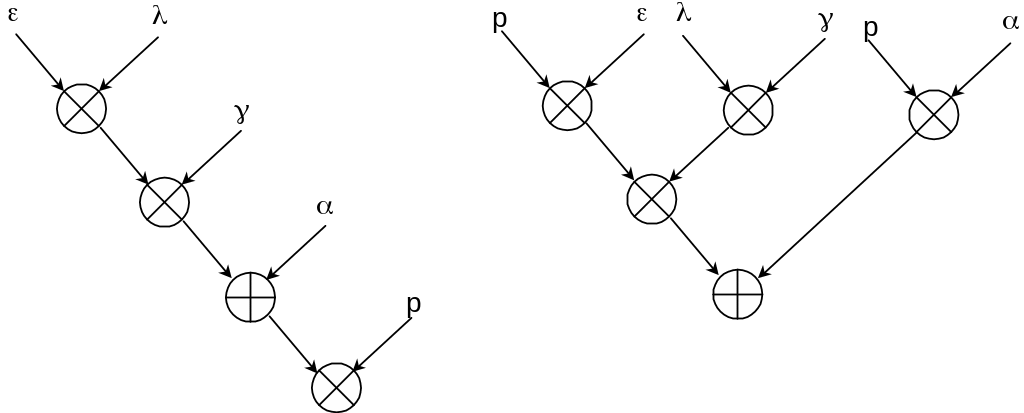
Рис.11. Редукция высоты дерева вычислений
В результате вместо четырех действий мы получили шесть, но многие действия теперь могут выполняться параллельно, так что высота дерева сократилась с 4 до 3 последовательных операций.
Безусловно, если
числа
![]() являются просто числами, то описанный
пример не имеет особого смысла – затраты
на порождение параллельных процессов
превзойдут выигрыш от параллельных
вычислений, но если
представляют собой более сложные
объекты, например матрицы большой
размерности, то выигрыш от параллельной
обработки может быть ощутимым.
являются просто числами, то описанный
пример не имеет особого смысла – затраты
на порождение параллельных процессов
превзойдут выигрыш от параллельных
вычислений, но если
представляют собой более сложные
объекты, например матрицы большой
размерности, то выигрыш от параллельной
обработки может быть ощутимым.
Параллельное вычисление по альтернативным ветвям
Практически все программы содержат в своем коде ветвления, предусматривающие альтернативные пути исполнения программы, в зависимости от сложившихся условий.
Принять окончательное решение о том, какую именно ветвь вычислений следует использовать, можно только после вычисления условия ветвления, однако, если в компьютере есть избыток процессоров, то можно заранее выполнить вычисление по всем альтернативным ветвям, а когда будет получено условие, просто воспользоваться полученным результатом для требуемой ветви.
Такой подход известен, как правило “никогда не ждать”. Его применение может сократить время выполнения практически любой программы, но за счет резкого возрастания объема вычислений.
Для сокращения накладных расходов можно выполнять вычисления не для всех, а только для наиболее вероятных альтернативных ветвей. Безусловно, иногда может сложиться ситуация, что вычисление для требуемой ветви не было сделано заранее, но если прогнозирование ветвления будет верным в большинстве случаев, то выигрыш в скорости выполнения программы все равно будет получен, а накладные расходы сократятся по сравнению с предварительным расчетом по всем ветвям.