

Введение в ассортимент микроконтроллеров STM32 |
4 |
которых 10 миллиардов было произведено в 2013 году. Процессорами на базе ARM оснащены примерно 75 процентов мобильных устройств в мире. Многие крупносерийные
ипопулярные 64-разрядные и многоядерные процессоры, используемые в устройствах
иставшие иконами в электронной промышленности (например, iPhone от Apple), основаны на архитектуре ARM (ARMv8-A).
Будучи своего рода широко распространенным стандартом, существует множество компиляторов и инструментов, а также операционных систем (Linux является наиболее используемой ОС на процессорах Cortex-A), которые поддерживают данные архитектуры, предлагая разработчикам множество возможностей для создания своих приложений.
1.1.1. Cortex и процессоры на базе Cortex-M
ARM Cortex является обширным набором 32/64-разрядных архитектур и ядер, довольно популярных в мире встраиваемых систем. Микроконтроллеры Cortex делятся на три основных подсемейства:
•Cortex-A, что означает Application – прикладной, представляет собой серию процессоров, предоставляющих широкий спектр решений для устройств, выполняющих сложные вычислительные задачи, такие как хостинг платформы операционной системы (ОС) мобильных устройств (rich OS) (наиболее распространенными являются Linux и его производные Android) и поддержка нескольких программных приложений. Ядрами Cortex-A оснащены процессоры большинства мобильных устройств, таких как смартфоны и планшеты. В данном сегменте рынка мы можем найти несколько производителей интегральных схем: от тех, кто продает каталог компонентов (TI или Freescale) до тех, кто производит процессоры для других лицензиатов. Среди наиболее распространенных ядер в этом сегменте можно выделить 32-разрядные процессоры Cortex-A7 и Cortex-A9, а также новейшие высокопроизводительные 64-разрядные ядра Cortex-A53 и
Cortex-A57.
•Cortex-M, что означает eMbedded – встраиваемый, представляет собой линейку масштабируемых, совместимых, энергоэффективных и простых в использовании процессоров, предназначенных для недорогого встраиваемого рынка. Семейство Cortex-M оптимизировано для чувствительных к стоимости и энергопотреблению микроконтроллеров, подходящих для таких приложений, как Интернет вещей (Internet of Things, IoT), связь, управление двигателем, интеллектуальный учет, устройства взаимодействия с человеком (human interface devices, HID), автомобильные и промышленные системы управления, домашняя бытовая техника, потребительские товары и медицинские инструменты. В данном сегменте рынка мы можем найти многих производителей интегральных схем, которые производят процессоры Cortex-M: ST Microelectronics является одним из них.
•Cortex-R, что означает Real-Time – реального времени, представляет собой серию процессоров, предлагающих высокопроизводительные вычислительные решения для встраиваемых систем, где необходимы надежность, высокая доступность, отказоустойчивость, ремонтопригодность и детерминированный отклик в реальном времени. Процессоры серии Cortex-R обеспечивают быструю и детерминированную обработку и высокую производительность при одновременном решении сложных задач в режиме реального времени. Они объединяют эти функции
Введение в ассортимент микроконтроллеров STM32 |
5 |
в корпусе, оптимизированном по производительности, энергопотреблению и занимаемой площади, что делает их верным выбором в надежных системах, требовательных к отказоустойчивости.
В следующих параграфах будут представлены основные возможности процессоров Cortex-M, особенно с точки зрения встраиваемого разработчика.
1.1.1.1.Регистры ядра
Как и все архитектуры RISC, процессоры Cortex-M являются машинами загрузки/хранения, которые выполняют операции только с регистрами ЦПУ, за исключением2 двух инструкций: load и store, используемых для передачи данных между регистрами ЦПУ и ячейками памяти.
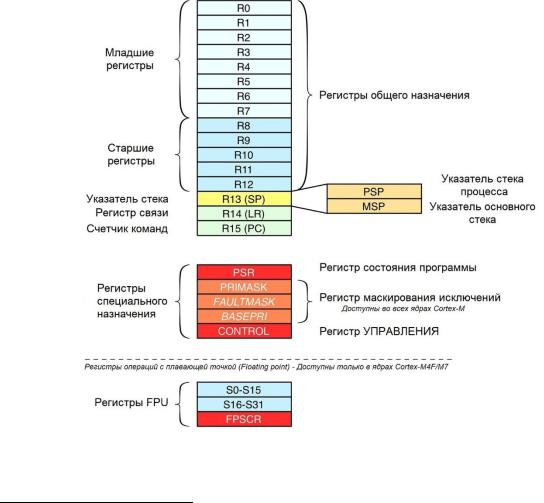
На рисунке 2 показаны основные регистры Cortex-M. Некоторые из них доступны только в высокопроизводительных сериях, таких как M3, M4 и M7. R0-R12 являются регистрами общего назначения и могут использоваться в качестве операндов для инструкций ARM. Однако некоторые регистры общего назначения могут использоваться компилятором в качестве регистров со специальными функциями. R13 – регистр указателя стека (Stack Pointer, SP), который также считается банковым. Это означает, что содержимое регистра изменяется в соответствии с текущим режимом ЦПУ (привилегированным или непривилегированным). Данная функция обычно используется операционными системами реального времени (ОСРВ) для переключения контекста.
Рисунок 2: Регистры ядра ARM Cortex-M
2 Это не совсем верно, поскольку в архитектуре ARMv6/7 доступны другие инструкции, обращающиеся к ячейкам памяти, но для целей данного обсуждения лучше всего считать это предположение верным.

Введение в ассортимент микроконтроллеров STM32 |
6 |
Например, рассмотрим следующий код Cи с использованием локальных переменных
“a”, “b”, “c”:
...
uint8_t a,b,c;
a = 3; b = 2;
c = a * b;
...
Компилятор сгенерирует следующий ассемблерный код ARM3:
1 |
movs |
r3, #3 |
;поместить "3" в регистр |
r3 |
||
2 |
strb |
r3, [r7, #7] |
;сохранить содержимое |
r3 |
в "a" |
|
3 |
movs |
r3, #2 |
;поместить "2" в регистр |
r3 |
||
4 |
strb |
r3, [r7, #6] |
;сохранить содержимое |
r3 |
в "b" |
|
5 |
ldrbr |
r2, [r7, #7] |
;загрузить содержимое |
"a" |
в r2 |
|
6 |
ldrb |
r3, [r7, #6] |
;загрузить содержимое |
"b" |
в r3 |
|
7 |
smulbb |
r3, r2, r3 |
;перемножить "a" на "b" и |
сохранить результат в r3 |
||
8 |
strb |
r3, [r7, #5] |
;сохранить результат в "c" |
|
||
Как мы видим, все операции всегда выполняются с регистром. Команды в строках 1-2 перемещают число 3 в регистр r3 и затем сохраняют его содержимое (то есть число 3) в ячейке памяти, заданной регистром r7 (который является указателем стекового кадра (frame pointer), как мы увидим в Главе 20) плюс смещение в 7 ячеек памяти – это ячейка, в которой хранится переменная. То же самое происходит для переменной b в строках 3-4. Затем строки 5-7 загружают содержимое переменных a и b и выполняют умножение. Наконец, строка 8 сохраняет результат в ячейке памяти переменной c.
1.1.1.2.Карта памяти
ARM определяет стандартизированное адресное пространство памяти, общее для всех ядер Cortex-M, что обеспечивает переносимость кода между различными производителями интегральных схем. Адресное пространство размером 4 ГБ и состоит из нескольких секций с различными логическими функциями. На рисунке 3 показана карта памяти (или схема распределения памяти) процессора Cortex-M4.
3 Этот ассемблерный код был скомпилирован в режиме thumb с отключенной оптимизацией, вызывая GCC следующим образом:
$ arm-none-eabi-gcc -mcpu=cortex-m4 -mthumb -fverbose-asm -save-temps -O0 -g -c file.c
4 Хотя организация памяти и размер секций (а, следовательно, и их адресов) стандартизированы для всех ядер Cortex-M, некоторые функции могут отличаться. Например, Cortex-M7 не предоставляет области доступа к битам (битовых лент), а некоторые периферийные устройства в области Шины собственных периферийных устройств (Private Peripheral Bus, PPB) различаются. Всегда обращайтесь к справочному руководству по архитектуре, которую вы рассматриваете.
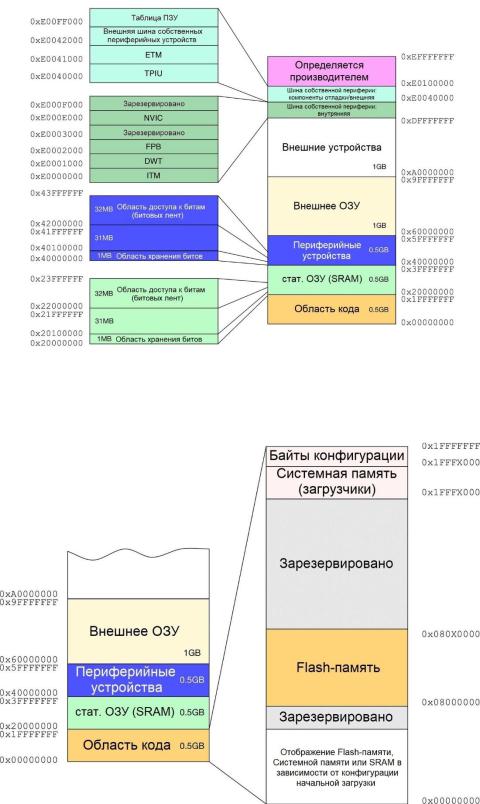
Введение в ассортимент микроконтроллеров STM32 |
7 |
Рисунок 3: Фиксированное адресное пространство памяти Cortex-M
Первые 512 МБ выделены для области кода. Устройства STM32 дополнительно делят эту область на несколько секций, как показано на рисунке 4. Давайте кратко рассмотрим их.
Рисунок 4: Карта памяти области кода на микроконтроллерах STM32

Введение в ассортимент микроконтроллеров STM32 |
8 |
Все процессоры Cortex-M отображают область кода, начиная с адреса 0x0000 00005. Данная область также включает указатель на начало стека (обычно помещается в SRAM) и таблицу векторов, как мы увидим в Главе 7. Расположение области кода стандартизировано среди всех других производителей Cortex-M, несмотря на то что архитектура ядра достаточно гибкая, чтобы позволить им организовать данную область по-другому. Фактически, для всех устройств STM32 область, начинающаяся с адреса 0x0800 0000, связана с внутренней Flash-памятью микроконтроллера и является областью, в которой находится программный код. Тем не менее, благодаря определенной конфигурации начальной загрузки, которую мы рассмотрим в Главе 22, данная область также отражается (aliased) на адрес 0x0000 0000. Это означает, что вполне возможно ссылаться на содержимое Flashпамяти, начиная с адреса 0x0800 0000 и 0x0000 0000 (например, процедура, расположенная по адресу 0x0800 16DC, также доступна из 0x0000 16DC).
Последние две секции выделены под Системную память и Байты конфигурации (Option bytes). Первая – это область ПЗУ, зарезервированная для загрузчиков. Каждое семейство STM32 (и их подсемейства – low density, medium density и т. д.) предоставляет загрузчик, предварительно запрограммированный в микросхему во время производства. Как мы увидим в Главе 22, данный загрузчик можно использовать для загрузки кода с нескольких периферийных устройств, включая USART, USB и CAN-шину. Область Байтов конфигурации содержит последовательность битовых флагов, которые могут использоваться для конфигурации некоторых аспектов микроконтроллера (таких как защита от чтения Flash-памяти, аппаратный сторожевой таймер, режим начальной загрузки и т. д.) и связаны с конкретным микроконтроллером STM32.
Возвращаясь ко всему 4 ГБ адресному пространству, следующая основная область – это область, ограниченная внутренним статическим ОЗУ (SRAM) микроконтроллера. Она начинается с адреса 0x2000 0000 и потенциально может расширяться до 0x3FFF FFFF. Однако фактический конечный адрес зависит от действующего количества внутреннего SRAM. Например, в случае микроконтроллера STM32F103RB с 20 КБ SRAM конечный адрес 0x2000 4FFF6. Попытка получить доступ к ячейке за пределами данной области вызовет исключение отказа шины Bus Fault (подробнее о нем позже).
Следующие 0,5 ГБ памяти предназначены для отображения периферийных устройств. Каждое периферийное устройство, предоставляемое микроконтроллером (таймеры, интерфейсы I²C и SPI, USART и т. д.), имеет отображение в данной области. Организация данного пространства памяти зависит от конкретного микроконтроллера.
1.1.1.3.Технология битовых лент (bit-banding)
Во встроенных приложениях достаточно часто необходимо работать с отдельными битами слова, используя битовое маскирование. Например, предположим, что мы хотим установить или сбросить 3-й бит (бит 2) беззнакового байта. Мы можем сделать это, просто воспользовавшись следующим кодом Си:
5Чтобы улучшить читабельность, все 32-битные адреса в данной книге написаны так, что старшие два байта отделены от младших. Таким образом, всякий раз, когда вы видите адрес, записанный таким образом (0x0000 0000), вы должны интерпретировать его как один общий 32-битный адрес (0x00000000). Данное правило не распространяется на исходные коды языков Си и ассемблера.
6Конечный адрес вычисляется следующим образом: 20 КБ = 20 * 1024 Байт, которые в шестнадцатеричной системе счисления равны 0x5000. Но адреса начинаются с 0, следовательно, конечный адрес 0x2000 0000 +
0x4FFF.

Введение в ассортимент микроконтроллеров STM32 |
9 |
...
uint8_t temp = 0;
temp |= 0x4; temp &= ~0x4;
...
Битовое маскирование используется, когда мы хотим сэкономить место в памяти (используя одну переменную и назначая различное значение для каждого из ее битов) или когда нам приходится иметь дело с внутренними регистрами микроконтроллера и периферийными устройствами. Разбирая предыдущий код Си, мы увидим, что компилятор сгенерирует следующий ассемблерный код ARM7:
#temp |= 0x4; |
|
|
|
|
a: |
79fb |
|
ldrb |
r3, [r7, #7] |
c: |
f043 |
0304 |
orr.w |
r3, r3, #4 |
10: |
71fb |
|
strb |
r3, [r7, #7] |
#temp &= ~0x4; |
|
|
|
|
12: |
79fb |
|
ldrb |
r3, [r7, #7] |
14: |
f023 |
0304 |
bic.w |
r3, r3, #4 |
18: |
71fb |
|
strb |
r3, [r7, #7] |
Как мы видим, такая простая операция требует трех ассемблерных инструкций (fetch, modify, save – выборка, изменение, сохранение). Это приводит к двум типам проблем. Во-первых, это пустая трата тактовых циклов процессора, использующихся на выполнение этих трех инструкций. Во-вторых, данный код работает нормально, если процессор работает в режиме одной задачи, и у нас есть только один поток выполнения, но, если мы имеем дело с одновременным выполнением, другая задача (или просто процедура прерывания) может повлиять на содержимое памяти перед завершением операции «битовое маскирование» (например, если между командами в строках 0xC-0x10 или 0x14- 0x18 в вышеприведенном ассемблерном коде происходит прерывание).
Битовые ленты – это способность отображать каждый бит определенной области памяти на целое слово в участке памяти области доступа к битам (битовых лент), англ. alias bit-banding region, обеспечивая атомарный доступ к такому биту. На рисунке 5 показано, как процессор Cortex отражает содержимое адреса памяти 0x2000 0000 с областью доступа к битам (битовых лент) 0x2200 0000-1c. Например, если мы хотим изменить бит 2 ячейки памяти 0x2000 0000, мы можем просто получить доступ к ячейке памяти
0x2200 0008.
Формула для вычисления адресов областей доступа к битам (битовых лент):
bit_band_address = alias_region_base + (region_base_offset x 32) + (bit_number x 4)
где:
alias_region_base – базовый адрес области доступа к битам; region_base_offset – смещение области доступа к битам;
bit_number – номер бита.
7 Этот ассемблерный код был скомпилирован в режиме tumb с отключенной оптимизацией, вызывая GCC следующим образом:
$ arm-none-eabi-gcc -mcpu=cortex-m4 -mthumb -fverbose-asm -save-temps -O0 -g -c file.c

Введение в ассортимент микроконтроллеров STM32 |
10 |
Рисунок 5: Отображение памяти адреса SRAM 0x2000 0000 в области битовых лент (показаны первые 8 из 32 битов)
Например, учитывая адрес памяти на рисунке 5, для доступа к биту 2:
alias_region_base = 0x22000000 region_base_offset = 0x20000000 - 0x20000000 = 0
bit_band_address = 0x22000000 + 0 × 32 + (0x2 × 0x4) = 0x22000008
ARM определяет две области хранения битов для микроконтроллеров на базе Cortex-M8, каждая из которых размером 1 МБ и отображается в 32-Мбитной области доступа к битам. Каждое последовательное 32-битное слово в области доступа к битам (bit-band alias) относится к каждому последовательному биту в области хранения бит (bit-band region) (что объясняет данное соотношение размеров: 1 Мбит <-> 32 Мбит). Первая область хранения бит начинается с 0x2000 0000 и заканчивается в 0x200F FFFF, а область доступа к битам с отраженными битами начинается от 0x2200 0000 до 0x23FF FFFF. Область доступа к битам предназначена для битового доступа к ячейкам памяти SRAM.
Рисунок 6: Карта памяти и области доступа к битам (битовых лент)
Другая область хранения битов начинается с 0x4000 0000 и заканчивается 0x400F FFFF, как показано на рисунке 6. Эта область посвящена отображению памяти периферийных
8 К сожалению, микроконтроллеры на базе Cortex-M7 не предоставляют возможности битовых лент.

Введение в ассортимент микроконтроллеров STM32 |
11 |
устройств. Например, ST отображает регистр GPIO выходных данных (Output Data Register, ODR) (GPIO->ODR) периферийного устройства GPIOA с 0x4002 0014. Это означает, что каждый бит слова, расположенного по адресу 0x4002 0014, позволяет изменять состояние вывода GPIO (с НИЗКОГО на ВЫСОКОЕ, и наоборот). Поэтому, если мы хотим изменить состояние вывода PIN5 порта GPIOA9, используя предыдущую формулу, то получим:
alias_region_base = 0x42000000
region_base_offset = 0x40020014 - 0x40000000 = 0x20014
bit_band_address = 0x42000000 + 0x20014 × 32 + (0x5 × 0x4) = 0x42400294
Мы можем определить два макроса в Си, которые позволяют легко вычислять адреса слов в области доступа к битам (битовых лент):
1// Определение базового адреса области хранения бит SRAM
2#define BITBAND_SRAM_BASE 0x20000000
3// Определение базового адреса области доступа к битам SRAM
4#define ALIAS_SRAM_BASE 0x22000000
5// Преобразование адресов SRAM (области хранения бит) в адреса области доступа к битам
6#define BITBAND_SRAM(a,b) ((ALIAS_SRAM_BASE + ((uint32_t)&(a)-BITBAND_SRAM_BASE)*32 + \
7(b*4)))
8 9 // Определение базового адреса области хранения бит периферийных устройств
10#define BITBAND_PERI_BASE 0x40000000
11// Определение базового адреса области доступа к битам периферийных устройств
12#define ALIAS_PERI_BASE 0x42000000
13// Преобразование адресов PERI (области хранения бит) в адреса области доступа к битам
14#define BITBAND_PERI(a,b) ((ALIAS_PERI_BASE + ((uint32_t)a-BITBAND_PERI_BASE)*32 + (b*4)))
Продолжая использовать приведенный выше пример, мы можем быстро изменить состояние вывода PIN5 порта GPIOA следующим образом:
1#define GPIOA_PERH_ADDR 0x40020000
2#define ODR_ADDR_OFF 0x14
3
4uint32_t *GPIOA_ODR = GPIOA_PERH_ADDR + ODR_ADDR_OFF;
5uint32_t *GPIOA_PIN5 = BITBAND_PERI(GPIOA_ODR, 5);
6
7 *GPIOA_PIN5 = 0x1; // GPIO переключается на ВЫСОКИЙ
1.1.1.4.Thumb-2 и выравнивание памяти
Исторически процессоры ARM предоставляют систему 32-битных команд. Это не только обеспечивает богатую систему команд, но и также гарантирует наилучшую производительность при выполнении команд, включающих арифметические операции и передачу данных из памяти между регистрами ядра и SRAM. Однако 32-битная система команд имеет высокую стоимость с точки зрения объема памяти встроенного микропро-
9 Любой, кто уже играл с платами Nucleo, знает, что пользовательский светодиод LD2 (зеленый) подключен к этому выводу порта.
Введение в ассортимент микроконтроллеров STM32 |
12 |
граммного обеспечения (или, как говорят, «прошивки», firmware). Это означает, что про-
грамме, написанной с 32-битной Архитектурой системы команд (Instruction Set Architecture, ISA), требуется больший объем Flash-памяти, что влияет на энергопотребление и общие затраты на микроконтроллер (кремниевые подложки дороги, и производители постоянно сокращают размер чипов для снижения их стоимости).
Для решения указанных проблем ARM представила 16-битную систему команд Thumb, которая является подмножеством наиболее часто используемых 32-битных. Инструкции Thumb имеют длину 16 бит и автоматически «переводятся» в соответствующую 32-бит- ную инструкцию ARM, обладающую тем же эффектом в модели процессора. Это означает, что 16-битные инструкции Thumb прозрачно расширяются (с точки зрения разработчика) до полных 32-битных инструкций ARM в режиме реального времени без потери производительности. Код Thumb обычно составляет 65% размера кода ARM и обеспечивает 160% производительность последнего при работе из 16-битной системы памяти; однако в Thumb 16-битные коды операций (opcodes) имеют меньшую функциональность. Например, только ветви (branches) могут быть условными, а многие коды операций ограничены доступом только к половине всех регистров общего назначения ЦПУ.
После этого ARM представила систему команд Thumb-2, представляющую собой смесь 16- и 32-битных систем команд в одном рабочем состоянии. Thumb-2 – это система команд переменной длины, которая предлагает гораздо больше инструкций по сравнению с Thumb, что обеспечивает схожую плотность кода.
Cortex-M3/4/7 предназначен для поддержки полных систем команд Thumb и Thumb-2, а некоторые из них поддерживают другие системы команд, предназначенные для опера-
ций с плавающей точкой (Cortex-M4/7), и инструкции управления потоками данных
(Single Instruction Multiple Data, SIMD-команды) (также известными как инструкции
NEON).
Другой интересной особенностью ядер Cortex-M3/4/7 является возможность делать невыровненный доступ к памяти. Процессоры на базе ARM традиционно способны получать доступ к байту (8-разрядных), полуслову (16-разрядных) и слову (32-разрядных) знаковых и беззнаковых переменных без увеличения количества ассемблерных инструкций, как это происходит в 8-разрядных архитектурах микроконтроллеров. Однако ранние архитектуры ARM не могли осуществлять невыровненный доступ к памяти, что приводило к бесполезной трате ячеек памяти.
Рисунок 7: Разница между выровненным и не выровненным доступом к памяти
Чтобы понять проблему, рассмотрим левую диаграмму на рисунке 7. Здесь у нас есть восемь переменных. В случае выровненного доступа к памяти мы имеем в виду, что для доступа к переменным длиной в слово (1 и 4 на диаграмме) нам нужно получить доступ

Введение в ассортимент микроконтроллеров STM32 |
13 |
к адресам, кратным 32 бит (4 Байт). То есть переменная длиной в слово может быть сохранена только в 0x2000 0000, 0x2000 0004, 0x2000 0008 и так далее. Каждая попытка получить доступ к ячейке, не кратной 4, вызывает исключение отказа программы Usage Fault. Таким образом, следующая псевдокоманда ARM неверна:
STR R2, 0x20000002
То же самое относится к чтению полуслова: можно получить доступ к ячейкам памяти, хранящимся в нескольких байтах: 0x2000 0000, 0x2000 0002, 0x2000 0004 и т. д. Это ограничение вызывает фрагментацию в оперативной памяти. Чтобы решить данную проблему, микроконтроллеры на базе Cortex-M3/4/7 могут осуществлять невыровненный доступ к памяти, как показано на правой диаграмме на рисунке 7. Как мы видим, переменная 4 хранится, начиная с адреса 0x2000 0007 (в ранних архитектурах ARM это было возможно только с однобайтовыми переменными). Это позволяет нам хранить переменную 5 в ячейке памяти 0x2000 000b, в результате чего переменная 8 будет храниться в 0x2000 000e. Теперь память «упакована», и мы сэкономили 4 Байта SRAM.
Однако невыровненный доступ ограничен следующими инструкциями ARM:
•LDR, LDRT
•LDRH, LDRHT
•LDRSH, LDRSHT
•STR, STRT
•STRH, STRHT
1.1.1.5.Конвейер
Всякий раз, когда мы говорим об исполнении инструкций, мы делаем ряд нетривиальных допущений. Перед выполнением инструкции ЦПУ должно извлечь ее из памяти и декодировать. Данная процедура использует несколько тактовых циклов ЦПУ, в зависимости от памяти и архитектуры ядра ЦПУ, которая добавляется к фактической стоимости инструкции (то есть к числу тактовых циклов, необходимых для выполнения этой инструкции).
Современные ЦПУ предоставляют способ распараллеливания данных операций, чтобы увеличить их пропускную способность инструкций (количество инструкций, которые могут быть выполнены за единицу времени). Основной цикл инструкций разбит на последовательность шагов, как если бы инструкции проходили по конвейеру (pipeline). Вместо последовательной обработки каждой инструкции (по одной, заканчивая одну инструкцию перед началом следующей), каждая инструкция разбивается на последовательность шагов, так что различные шаги могут выполняться параллельно.
Рисунок 8: Трехступенчатый конвейер инструкций

Введение в ассортимент микроконтроллеров STM32 |
14 |
Все микроконтроллеры на базе Cortex-M представляют собой конвейерную форму. Наиболее распространенным является трехступенчатый конвейер, как показано на рисунке 8. Трехступенчатый конвейер поддерживается ядрами Cortex-M0/3/4. Ядра Cortex-M0+, которые предназначены для микроконтроллеров с пониженным энергопотреблением, предоставляют двухступенчатый конвейер (хотя конвейеризация помогает сократить временные затраты, связанные с циклом выборки/декодирования/исполнения инструкции, она вводит затраты энергии, которые должны быть минимизированы в приложениях с пониженным энергопотреблением). Ядра Cortex-M7 обеспечивают
шестиступенчатый конвейер.
При работе с конвейерами ветвление является проблемой, требующей решения. Выполнение программы заключается в том, чтобы идти различными путями; это достигается посредством ветвления (if equal goto – если равно, то перейти). К сожалению, ветвление вызывает аннулирование потоков конвейера, как показано на рисунке 9. Последние две инструкции были загружены в конвейер, но они отбрасываются из-за использования дополнительного пути ветвления (мы обычно называем их тенями ветвления, англ. branch shadows)
Рисунок 9: Ветвление при выполнении программы, связанное с конвейерной обработкой
Даже в этом случае есть несколько методов минимизации влияния ветвления. Их часто называют методами прогнозирования ветвления (branching prediction techniques). Идеи, ле-
жащие в основе данных методов, состоят в том, что ЦПУ начинает извлекать и декодировать как инструкции, следующие за ветвлением, так и те, которые будут достигнуты, если произойдет ветвление (на рисунке 9 либо инструкция MOV, либо ADD). Однако существуют и другие способы реализации схемы прогнозирования ветвлений. Если вы хотите глубже изучить данную тему, этот пост1011 на официальном форуме поддержки ARM станет хорошей отправной точкой.
10https://community.arm.com/developer/ip-products/processors/f/cortex-m-forum/3190/cortex-m3-pipeline- stages-branch-prediction
11В оригинальной книге автор использует укороченные ссылки на интернет-ресурсы от сервисов типа bit.ly, которые заблокированы на территории РФ Роскомнадзором. В связи с этим в переводе все заблокированные сокращенные ссылки были заменены на полные. (прим. переводчика)

Введение в ассортимент микроконтроллеров STM32 |
15 |
1.1.1.6.Обработка прерываний и исключений
Обработка прерываний и исключений – одна из самых мощных функций процессоров на базе Cortex-M. Прерывания и исключения являются асинхронными событиями, которые изменяют ход программы. Когда происходит исключение или прерывание, ЦПУ приостанавливает выполнение текущей задачи, сохраняет свой контекст (т. е. свой указатель стека) и начинает выполнение процедуры, предназначенной для обработки события прерывания. Эта процедура называется Обработчиком исключений (Exception Handler) в случае исключений и Процедурой обслуживания прерывания (Interrupt Service Routine, ISR) в случае события прерывания. После обработки исключения или прерывания ЦПУ возобновляет предыдущий поток выполнения, и предыдущая задача может продолжить свое выполнение12.
В архитектуре ARM прерывания являются одним из типов исключений. Прерывания обычно генерируются от встроенных периферийных устройств (например, таймера) или внешних входов (например, тактильного переключателя, подключенного к GPIO), и в некоторых случаях они могут запускаться программно. Исключения, напротив, связаны с выполнением программного обеспечения, а само ЦПУ может быть источником исключений. Это могут быть события отказов, такие как попытка доступа к неверной ячейке памяти, или события, сгенерированные операционной системой, если таковые имеются.
Каждое исключение (а, следовательно, и прерывание) имеет номер, который однозначно идентифицирует его. В таблице 1 показаны предопределенные исключения, общие для всех ядер Cortex-M, а также переменное число пользовательских прерываний, относящихся к управлению. Это число отражает позицию процедуры обработчика исключения внутри таблицы векторов, где хранится фактический адрес процедуры. Например, позиция 15 содержит адрес памяти области кода, содержащей обработчик исключений для прерывания от SysTick, сгенерированного при достижении таймером SysTick нуля.
Кроме первых трех, каждому исключению может быть назначен уровень приоритета, который определяет порядок обработки в случае одновременных прерываний: чем меньше число, тем выше приоритет. Например, предположим, что у нас есть две процедуры прерывания, связанные с внешними входами A и B. Мы можем назначить прерывание с более высоким приоритетом (с более низким числом) для входа A. Если прерывание, связанное с A, поступает при обработке процессором прерывания со входа B, то выполнение B приостанавливается, что позволяет немедленно выполнить процедуру обработки прерывания с более высоким приоритетом.
12 Термин задача (task) означает последовательность команд, которые составляют основной поток выполнения. Если наша микропрограмма (firmware) основана на ОС, сценарий может быть более четко сформулирован. Кроме того, в случае спящего режима с пониженным энергопотреблением, ЦПУ может быть сконфигурировано на возврат в спящий режим после выполнения процедуры обслуживания прерывания.

Введение в ассортимент микроконтроллеров STM32 |
16 |
|||
Номер |
Тип исключения |
Приоритетa |
Описание |
|
1 |
Reset |
-3 |
Сброс |
|
2 |
NMI |
-2 |
Немаскируемое прерывание |
|
|
|
|
Любой отказ, если отказ не может быть |
|
3 |
Hard Fault |
-1 |
активирован из-за приоритета или |
|
программируемый обработчик отказа не |
||||
|
|
|
||
разрешен.
4 |
Memory |
Программируемыйb |
|
Managementc |
|||
|
|
||
5 |
Bus Faultc |
Программируемый |
|
6 |
Usage Faultc |
Программируемый |
Несоответствие MPU, включая нарушение прав доступа и отсутствие совпадений. Используется, даже если модуль MPU отключен или отсутствует.
Отказ предвыборки, отказ доступа к памяти и другие, связанные с адресом/памятью.
Ошибка в программе, такая как выполнение неопределенной инструкции или недопустимая попытка перехода между состояниями.
7-10 |
— |
— |
ЗАРЕЗЕРВИРОВАНО |
11 |
SVCall |
Программируемый |
Вызов системной службы командой SVC. |
12 |
Debug monitorc |
Программируемый |
Монитор отладки – для программной отладки. |
13 |
— |
— |
ЗАРЕЗЕРВИРОВАНО |
14 |
PendSV |
Программируемый |
Отложенный запрос для системной службы |
15 |
SYSTICK |
Программируемый |
Срабатывание системного таймера |
16-[47/240]d |
IRQ |
Программируемый |
Вход внешнего прерывания |
aЧем ниже значение приоритета, тем выше приоритет.
bМожно изменить приоритет исключения, назначив другой номер. Для процессоров Cortex-M0/0+ это число колеблется от 0 до 192 с шагом 64 (т. е. доступно 4 уровня приоритета). Для Cortex-M3/4/7 колеблется от 0 до 255.
cДанные исключения не доступны в Cortex-M0/0+.
dCortex-M0/0+ допускает 32 внешних конфигурируемых прерывания. Cortex-M3/4/7 допускает 240 конфигурируемых внешних прерываний. Однако на практике количество входов прерываний, реализованных в реальном микроконтроллере, намного меньше.
Таблица 1: Типы исключений Cortex-M
И исключения, и прерывания обрабатываются отдельным модулем, который называется
Контроллер вложенных векторных прерываний (Nested Vectored Interrupt Controller, NVIC).
Контроллер NVIC обладает следующими особенностями:
•Гибкое управление исключениями и прерываниями: NVIC может обрабаты-
вать как сигналы/запросы прерываний, поступающие от периферийных устройств, так и исключения, поступающие от ядра процессора, что позволяет нам разрешать/запрещать их в программном обеспечении (кроме NMI13).
•Поддержка вложенных исключений/прерываний: NVIC позволяет назначать уровни приоритета исключениям и прерываниям (кроме первых трех типов исключений), предоставляя возможность классифицировать прерывания в зависимости от потребностей пользователя.
13 Также нельзя запретить исключение сброса Reset, т. к. говорить о запрете исключения сброса некорректно, поскольку это первое исключение, сгенерированное после сброса микроконтроллера. Как мы увидим в Главе 7, исключение сброса является фактической точкой входа для каждого приложения STM32.
Введение в ассортимент микроконтроллеров STM32 |
17 |
•Векторный переход к исключению/прерыванию: NVIC автоматически опреде-
ляет расположение обработчика исключений, связанного с исключением/прерыванием, без необходимости в дополнительном коде.
•Маскирование прерываний: разработчики могут приостанавливать выполнение всех обработчиков исключений (кроме NMI) или приостанавливать некоторые из них на основе уровня приоритета благодаря набору отдельных регистров. Это позволяет выполнять критические задачи безопасным способом, исключив асинхронные прерывания.
•Детерминированное время реакции на прерывание: еще одна интересная осо-
бенность NVIC – детерминированная задержка обработки прерывания, которая равна 12 тактовым циклам для всех ядер Cortex-M3/4, 15 тактовым циклам для Cortex-M0, 16 тактовым циклам для Cortex-M0+ независимо от текущего состояния процессора.
•Перемещение обработчиков исключений: как мы рассмотрим далее, обработ-
чики исключений могут быть перемещены в другие ячейки Flash-памяти, а также в совершенно другую, даже внешнюю память, не ПЗУ (ROM). Это обеспечивает большую степень гибкости для продвинутых приложений.
1.1.1.7.Системный таймер SysTick
Процессоры на базе Cortex-M могут дополнительно предоставлять системный таймер, также известный как SysTick. Хорошей новостью является то, что все устройства STM32 оснащены им, как показано в таблице 3.
SysTick – это 24-разрядный таймер нисходящего отсчета, используемый для предостав-
ления системного тика для операционных систем реального времени (Real Time Operating Systems, RTOS), таких как FreeRTOS. Он используется для того, чтобы генерировать периодические прерывания для запланированных задач. Программисты могут задавать частоту обновления таймера SysTick, устанавливая его регистры. Таймер SysTick также используется HAL для STM32 для генерации точных задержек, даже если мы не используем ОСРВ. Подробнее об этом таймере в Главе 11.
1.1.1.8.Режимы питания
Современная тенденция в электронной промышленности, особенно когда речь идет о разработке мобильных устройств, связана с управлением питанием. Снижение до минимума энергопотребления является основной целью всех разработчиков аппаратных средств и программистов, занимающихся разработкой устройств с батарейным питанием. Процессоры Cortex-M предоставляют несколько уровней управления питанием, которые можно разделить на две основные группы: внутренние особенности и определя-
емые пользователем режимы питания.
Говоря о внутренних особенностях, мы ссылаемся на те естественные возможности, касающиеся энергопотребления, которые определены во время проектирования как ядра Cortex-M, так и всего микроконтроллера. Например, в ядрах Cortex-M0+ устанавливается только двухступенчатый конвейер для снижения энергопотребления при предварительной выборке инструкций. Другое естественное поведение, связанное с управлением питанием, – высокая плотность кода системы команд Thumb-2, которая позволяет разработчикам выбирать микроконтроллеры с меньшей Flash-памятью для снижения энергопотребления.

Введение в ассортимент микроконтроллеров STM32 |
18 |
Рисунок 10: Потребление питания Cortex-M в различных режимах работы
Традиционно процессоры Cortex-M предоставляют определенные пользователем ре-
жимы питания через Регистр управления системой (System Control Register, SCR). При пер-
вом включении запускается Рабочий режим, англ. Run mode (см. рисунок 10), в котором ЦПУ работает на полную мощность. В Рабочем режиме энергопотребление зависит от тактовой частоты и используемых периферийных устройств. Спящий режим (Sleep mode)
— это первый доступный режим пониженного энергопотребления. При активации данного режима большинство функциональных возможностей приостанавливается, частота ЦПУ снижается, а его активность снижается до той, которая необходима для его активации. В режиме Глубокого сна (Deep sleep mode) все тактирование останавливается, и ЦПУ требуется внешнее событие для выхода из этого состояния.
Рисунок 11: Потребляемая мощность STM32F2 в различных режимах питания
Однако данные режимы питания являются только общими моделями, которые в дальнейшем реализуются в реальном микроконтроллере. Например, рассмотрим рисунок 11, отображающий энергопотребление микроконтроллера STM32F2, работающего на

Введение в ассортимент микроконтроллеров STM32 |
19 |
80МГц при 30°C14. Как мы видим, максимальное энергопотребление достигается в Рабочем режиме (т. е. в Активном режиме) при отключенном ускорителе ART™ Accelerator. Используя ускоритель ART™ Accelerator, мы можем сэкономить до 10 мАч, одновременно добиваясь лучших вычислительных характеристик. Все это четко показывает, что реальная реализация микроконтроллера может вводить различные уровни питания.
Семейства STM32Lx предоставляют несколько дополнительных промежуточных уровней питания, позволяя точно выбирать предпочтительный режим питания и, следовательно, производительность и энергопотребление микроконтроллера.
Мы углубимся в данную тему в Главе 19.
1.1.1.9.CMSIS
Одним из ключевых преимуществ платформы ARM (как для производителей интегральных схем, так и для разработчиков приложений) является наличие полного набора инструментов разработки (компиляторы, библиотеки среды выполнения (run-time libraries), отладчики и т. д.), которые могут многократно использоваться несколькими производителями.
ARM также активно работает над способом стандартизации программной инфраструктуры среди производителей микроконтроллеров. Стандарт программного интерфейса микроконтроллеров Cortex (Cortex Microcontroller Software Interface Standard, CMSIS)
представляет собой независимый от производителя уровень аппаратной абстракции для серии процессоров Cortex-M и определяет интерфейсы отладчика. CMSIS состоит из следующих компонентов:
•CMSIS-CORE: API-интерфейс для ядра и периферии процессора Cortex-M. Он обеспечивает стандартизированный интерфейс для Cortex-M0/3/4/7.
•CMSIS-Driver: Определяет общие интерфейсы периферийных драйверов для промежуточного программного обеспечения (middleware), делая их многоразовыми на поддерживаемых устройствах. API-интерфейс не зависит от ОСРВ и соединяет периферийные устройства микроконтроллера с промежуточным программным обеспечением, которое, помимо прочего, реализует стеки связи, файловые системы или графические пользовательские интерфейсы.
•CMSIS-DSP: Коллекция библиотек DSP с более чем 60 функциями для различных типов данных: с фиксированной точкой (дробная q7, q15, q31) и с плавающей точкой одинарной точности (32-разрядная). Библиотека доступна для Cortex-M0, Cortex-M3 и Cortex-M4. Реализация для Cortex-M4 оптимизирована для системы команд SIMD.
•CMSIS-RTOS API: Общий API-интерфейс для операционных систем реального времени. Он обеспечивает стандартизированный интерфейс программирования, который переносится на многие ОСРВ и, следовательно, позволяет использовать программные шаблоны, промежуточное программное обеспечение, библиотеки и другие компоненты, которые могут работать в поддерживаемых ОСРВ. Мы поговорим о данном уровне API-интерфейса в Главе 23.
•CMSIS-Pack: используя файл описания пакета на основе XML с расширением «PDSC», описывает соответствующие пользовательские компоненты и компоненты устройства из коллекции файлов (именуемых «software pack»), которые
14 Источник – ST AN3430