

Качество программного продукта
Понятие качества программного продукта (software product quality) тесно связано с понятиями дефекта (defect) и ошибки (error, bug).
Дефект программного продукта (defect) – это любое наблюдаемое несоответствие его фактического поведения в допустимых условиях эксплуатации, ожидаемому поведению, как оно определено в спецификации требований.
Ошибка (error) – это причина наблюдаемого дефекта, как правило, присутствующая в коде, но коренящаяся либо в коде, либо в проекте, либо в спецификации требований, либо в аппаратуре.
В англоязычной литературе под ошибкой часто понимается «любая проблема, обнаруженная на той же фазе ЖЦ, где она возникла», а под дефектом – «проблема, обнаруженная на какой-либо из последующих фаз ЖЦ после ее возникновения». Термин fault, используемый наряду с error и defect, означает одновременно и ошибку, и дефект в указанном выше смысле; т.е., любую проблему в программном продукте, независимо от фазы ЖЦ, на которой она была обнаружена.
Таким образом, дефект лишь обнаруживает наличие ошибки в реализации продукта; причем бывает, что один дефект является следствием нескольких различных ошибок и, наоборот, одна и та же ошибка является причиной нескольких разных дефектов. Чем дальше по линии ЖЦ разработки отстоит место обнаружения дефекта в программном продукте от места совершения ошибки, его вызвавшей, тем более высока для исполнителя стоимость выявления места этой ошибки, ее исправления и проверки того, что исправление действительно устранило обнаруженный дефект и не привнесло в продукт новых дефектов. Эти затраты образуют так называемую стоимость плохого программирования (Cost Of Poor Quality – COPQ), снижение которой является важным резервом исполнителя в повышении эффективности своей работы. Эти затраты никак не оплачиваются заказчиком, а лишь повышают себестоимость разработки, снижая тем самым остающуюся у разработчиков прибыль от разработки.
С выявлением дефектов связано понятие «дублирования», когда разные в своем наблюдаемом проявлении дефекты являются по существу одним и тем же дефектом; т.е., сводятся к общей проблеме и, соответственно, к общей ошибке или группе ошибок в коде как своей причине. Устранение этой причины устраняет все эти дефекты.
На основании обследования огромного числа (свыше 3000) реальных программных проектов еще в начале 1980-х годов Боэм (Barry Boehm) установил экспоненциальный рост этих затрат (кривая Боэма – Рис. 2), который с тех пор только постоянно подтверждался дальнейшими исследованиями. Практический вывод из этого наблюдения – стараться не позволять совершаемым в процессе разработки ошибкам «перерастать» в дефекты, а находить их и устранять как можно раньше, сразу же по мере их возникновения, используя различные методы и практики предотвращения дефектов (defect prevention).
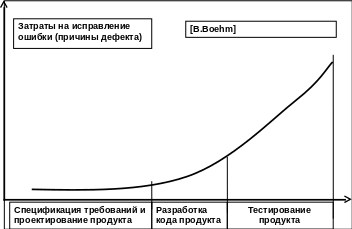
Рис. 2. Кривая Боэма – рост затрат на поиск и устранение причин дефектов
Качество программного продукта – это оценка числа оставшихся в нем дефектов, которые могут проявиться при его эксплуатации. Эти оставшиеся дефекты могут быть как известные разработчикам (с поправкой на дублирование), но по разным причинам еще не исправленные, так и еще не выявленные. Для оценки числа оставшихся в коде дефектов, принимаются следующие предположения:
а) каждая ошибка является причиной ровно одного дефекта, а каждый дефект является следствием только одной ошибки; т.е. суммарное число дефектов в продукте (уже известных и еще не выявленных) равно числу ошибок в его коде (это не всегда так, но позволяет упростить ход рассуждений);
б) плотность ошибок (среднее число совершаемых разработчиком ошибок на 1000 строк кода) в создаваемом документе (например, в тексте программы) постоянна и не зависит от его размера (для программ это число «содержательных» строк кода без комментариев и пустых строк);
в) ошибки не зависят друг от друга.
Тогда, если обозначить плотность ошибок через R, а размер кода – через S, то оценка числа ошибок M в этом коде очевидна: M=R×S. Именно столько ошибок (причин дефектов) и следует искать (и устранять!) в данном коде, чтобы рассчитывать на бездефектный (defect-free) продукт.
В процессе разработки продукта ошибки в коде постепенно обнаруживаются и, как правило, устраняются. Если фиксировать (заносить в БД проекта) все наблюдаемые дефекты и находимые по ним ошибки, устраняя дублирование и «ложные тревоги» (обозначив их общее число через N), то текущее качество программного продукта Q определяется как (M-N)/S в предположении, что M≥N. Если это значение устраивает заказчика, то процесс разработки можно заканчивать, в противном случае надо продолжать искать дефекты, выявляя и устраняя их причины – ошибки. Если же в какой-то момент оказалось, что M<N, то это говорит о неточности в определении M, которая, скорее всего, проистекает из-за заниженной оценки для плотности совершения ошибок R. В этом случае надо понять причины такой неточности и устранить ее.

Рис. 3. Измерение качества программного продукта
Этот процесс нахождения и устранения ошибок отображается S-кривой на графике, показывающим зависимость числа найденных (и исправленных!) ошибок от времени (Рис. 3). На графике хорошо видны два характерных «скачка»; обычно первый связан с синтаксическими ошибками, выявляемыми транслятором, а второй – с логическими ошибками, обнаруживаемыми при прогоне тестов. При дальнейшем тестировании новые ошибки обнаруживаются все реже и реже, так что S-кривая становится практически пологой, что говорит о «насыщении» процесса поиска ошибок данными средствами. Если текущее качество продукта не устраивает заказчика, то надо создавать дополнительные тесты или применять какие-либо другие методы верификации и валидации программного обеспечения.
На практике качество поставляемого программного продукта принято оценивать по плотности поставленных дефектов, известных и неизвестных, в пересчете на размер программного кода в 1000 KAELOC.
Можно предположить, что дефекты, содержащиеся в программном коде, являются случайными независимыми событиями и вызывающие их ошибки могут встречаться в каждой строке. При таком условии число случайных событий-дефектов может быть более одного миллиона. Тогда можно предположить, что распределение вероятности присутствия ошибок на строках кода подчиняется нормальному закону.
График плотности вероятности такого распределения показан на Рис. 4. Считают, что качество программного продукта имеет уровень i сигма (сигма – это среднеквадратическое отклонение случайных событий – присутствия дефектов на строках кода), если количество строк кода, не содержащих дефектов, попадает в интервал ±i сигма относительно его математического ожидания m (Рис. 4). Оставшиеся за пределами этого интервала строки кода, содержащие дефекты, определяют плотность дефектов в поставляемом продукте.
В действительности распределение вероятности того, что строка кода, содержит ошибки, часто отклоняется от нормального. По этой причине и по некоторым другим аналогиям из промышленного производства сложных промышленных изделий, на практике для оценки качества программного продукта используются несколько увеличенные плотности дефектов, приведенные в Табл. 3.
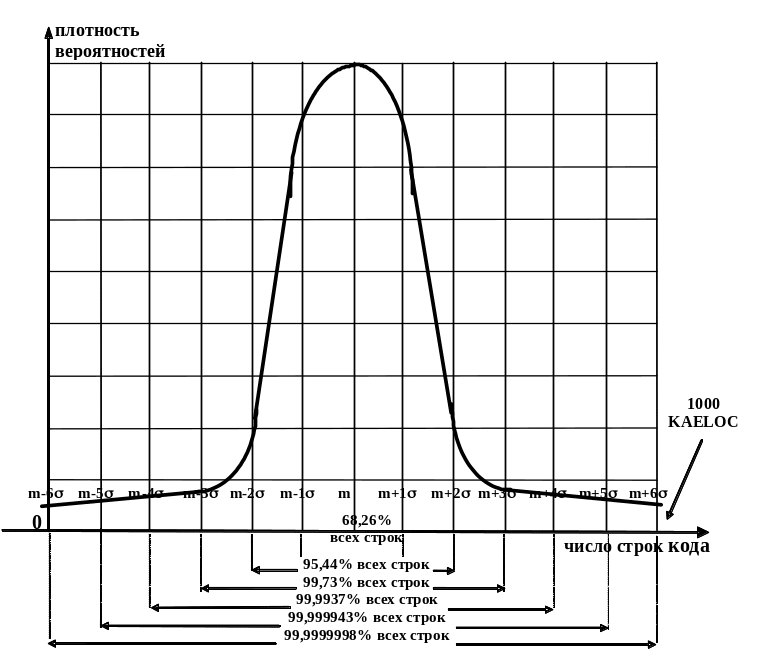
Рис. 4. Распределение вероятности присутствия дефектов на строках кода
Как видно из приведенных цифр, программный продукт с уровнем качества 6 сигма может содержать в своем программном коде лишь 3,4 дефекта на один миллион строк на языке ассемблера; т.е., только 3,4 строки из 1 миллиона являются дефектными – содержат ошибку. Этот уровень качества является очень высоким, но реально достижимым при наличии очень высокой дисциплины труда и с соблюдением всех директив стандартного процесса.
Табл. 3. Уровни сигма и оценка числа остаточных дефектов
Уровень сигма |
Дефектов на 1 миллион исходов |
Процент дефектов |
Процент успеха |
1 |
691 462 |
69 |
31 |
2 |
308 538 |
31 |
69 |
3 |
66 807 |
6,7 |
93,3 |
4 |
6 210 |
0,62 |
99,38 |
5 |
233 |
0,023 |
99,977 |
6 |
3,4 |
0,00034 |
99,99966 |
Если объем кода программного продукта в KLOC или KAELOC легко измерить или подсчитать, то как быть с плотностью совершения ошибок? На практике она определяется постепенно, путем фиксирования в БД проектов и подсчета всех найденных ошибок. Если таких проектов выполнено достаточно много для статистически значимой выборки, то по ним можно вычислить среднее значение этой величины, с определенной поправкой на ошибки, оставшиеся не найденными (эта поправка определяется экспертным путем). Интересно отметить, что это значение меняется достаточно медленно и является индивидуальным для данного разработчика или группы разработчиков на протяжении длительного периода времени.
Кроме того, из практики замечено, что плотность ошибок при внесении изменений в код (в частности, при исправлении уже найденных ошибок) в 3 раза выше, чем обычная плотность совершения ошибок при написании кода заново. Это означает, что при внесении изменений в код надо быть предельно внимательным и учитывать это отличие при планировании таких деятельностей.