

belyuchenko_i_s_smagin_a_v_i_dr_analiz_dannykh_i_matematiche
.pdfговорят. Качественные данные с помощью специальных процедур часто могут быть переведены в количественную форму.
Документирование и представление первичных данных.
Данные, независимо от их объема, должны быть тщательно документированы. Это облегчает преемственность работы с ними разных специалистов, позволяет возвращаться к анализу этих данных в связи с появлением новых гипотез. Такое документирование обязательно должно включать в себя имя исследователя, имена собранных массивов данных и способов анализа.
Все это достигается при современном уровне математического обеспечения ЭВМ довольно простыми средствами, но позволяет при этом решать очень важные задачи, связанные с контролем переменных при проведении дальнейшего статистического анализа, обнаружения неточностей и ошибок. Если экспериментальных данных достаточно много, то возникает проблема их группировки, т. е. представления в более компактной и наглядной форме. При этом надо различать вопросы, связанные с представлением динамических рядов, и группировкой тех данных, для которых пространственные и временные факторы не играют существенной роли.
4.2Компьютерная система функционального анализа данных
Построение любой модели экосистемы начинается, как правило, с организации оперативного и непротиворечивого доступа к массивам первичных данных экспедиционных исследований.
Полная компьютерная система, предназначенная для поддержки аналитической деятельности конкретного экологического проекта может быть представлена следующей ие-
31
рархией из семи ступенями функционального анализа данных:
–первичная группировка или склеивание данных в «ку-
чи» (heaping) с использованием средств, которые обеспечивают хранение разнородной информации, ведение идентификационных справочников и сортировку сведений на три кучи: «ценную» (valuable hill), «рабочую» (work hill) и «отбросы, в которых может быть найдена жемчужина» (dung hill);
–складирование данных (data warehousing, DWH) и их маркирование, удобное для описания и извлечения различных семантических группировок; результат DWH представляется в виде многомерного куба, каждая точка внутри которого соответствует набору семантически однородных элементарных объектов;
–совмещение, комбинирование данных (combining) – создание многомерного пространства, где каждая координата соответствует элементу набора или точке куба DWH, отображенной на линейно–упорядоченные градуированные оси (только в этом пространстве могут быть установлены отношения взаимосвязи и проведен анализ на основе метрической близости);
–компьютерная томография или визуальный много-
мерный анализ (visual multidimensional analysis) – позволяет конструировать двух- и трехмерные визуальные образы (паттерны) сложных взаимосвязей между рядам данных, наблюдать динамику образования и развитие аномалий;
–разведывательный анализ данных (data mining) – «просеивание» информации с целью нахождения в ней особенностей и аномалий, заданных описанием шаблонов или пороговых значений;
–восстановление зависимостей (forecasting) по эмпи-
рическим выборкам – математическая обработка многомер-
32
ных наблюдений (статистический и прецедентный анализ, оценка тренда временных рядов и проч.);
– принятие решений, планирование и управление
(deciding – computer aided engineering) – отображается спе-
циальной сетью «ресурсы – потоки – события».
4.3 Правила составления сводных таблиц
При решении различных вопросов экологического исследования необходимо знать правила планирования исследования, сбора и статистической обработки описательного материала.
Результатом полевого этапа экологического исследования и этапа камеральной обработки является, например данные по химическому или физическому анализу проб почвы, воды, воздуха.
В большинстве случаев обработку целесообразно начать
ссоставления таблиц (сводных таблиц) полученных данных. Пример такой таблицы представлен на рисунке 4.1.
По строкам занесены значения показателей в опреде-
ленной точке отбора проб. По столбцам расположены значения каждого заносимого в таблицу признака (измеренного параметра) − в одном столбце находятся значения одного признака по всем точкам отбора проб. Все строки и все столбцы должны быть пронумерованы. Последовательность признаков может быть упорядочена по разным основаниям (например, по времени).
На рисунке 4.1 представлены данные по содержанию тяжелых металлов в почвах на территории определенного хозяйства. По строкам расположены точки отбора проб, а по столбцам содержание подвижной формы меди в различные времена года.
33
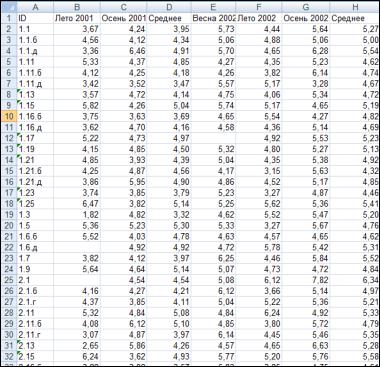
Рисунок 4.1 – Пример таблицы сводных данных
4.4 Проверка данных
После создания таблицы на бумаге или электронной таблицы на компьютере необходимо проверить качество полученных данных. Для этого часто достаточно внимательно осмотреть массив данных. Начать проверку следует с выявления ошибок (описок), которые заключаются в том, что неправильно написан порядок числа. Например, 100 написано вместо 10; 9,4 вместо 94 и т.п. При внимательном просмотре по столбцам это легко обнаружить, поскольку сравнительно редко встречаются параметры, которые сильно варьируют. Чаще всего значения одного параметра имеют один порядок
34
или ближайшие порядки. При наборе данных на компьютере важно соблюдать требования к формату данных в используемой статистической программе. Прежде всего, это относится к знаку, который должен отделять в десятичном числе целую часть от дробной (точка или запятая).
Затем массив данных надо проверить на наличие «вы-
скакивающих» или выделяющихся значений, которые могли быть получены в результате неточных измерений, ошибок в записях, отвлечения внимания и т. д. Если обнаружены «подозрительные» значения, то нужно принять обоснованное решение об их выбраковке. Его можно принять, используя достаточно мощный параметрический критерий t (критерий выпада). Он рассчитывается по следующей формуле:
t |
V M |
t , |
(4.1) |
S кр
где t − критерий выпада;
V − выпадающее значение признака;
М − средняя величина признака для всей группы; S – стандартное отклоненение;
tкр − стандартные значения критерия выпадов.
Заметим, что последний показатель определяется для трех уровней доверительной вероятности по таблице «Значения критерия t для обработки выпадающих вариант при разных уровнях значимости ()». Смысл критерия в том, чтобы определить, находится ли данное значение в интервале, характерном для большинства членов выборки, или же вне его.
Допустим, нами принят уровень значимости = 0,05 (доверительная вероятность 0,95), а значение критерия t составило 1,5. Поскольку при 95 % вероятности выборка имеет пределы М ± 1,96 σ (1,5 меньше 1,96), следовательно, данное значение лежит в указанном интервале. Если же значение критерия больше, чем 2,4 (например), то это означает,
35
что данное значение с 95 % вероятностью не относится к анализируемой совокупности (выборке), а есть проявление иных закономерностей, ошибок и прочее и, должно быть, поэтому исключено из рассмотрения.
После исключения выпадающих значений первичные статистические параметры вычисляются заново.
4.5 Планирование выборочных исследований
Общее понятие о выборочном методе. Множество всех единиц совокупности, обладающих определенным признаком и подлежащих изучению, носит в статистике название
генеральной совокупности.
На практике не всегда возможно или же нецелесообразно рассматривать всю генеральную совокупность. Тогда ограничиваются изучением лишь некоторой ее части. Затем полученные результаты распространяют на всю генеральную совокупность, т. е. применяют выборочный метод. Для этого из генеральной совокупности особым образом отбирается часть элементов, так называемая выборка, и результаты обработки выборочных данных (например, средние арифметические значения) обобщаются на всю совокупность.
Теоретической основой выборочного метода является закон больших чисел. В силу этого закона при ограниченном рассеивании признака в генеральной совокупности и достаточно большой выборке с вероятностью, близкой к полной достоверности, выборочная средняя может быть сколь угодно близка к генеральной средней. Закон этот, включающий в себя группу теорем, доказан строго математически. Таким образом, средняя арифметическая, рассчитанная по выборке, может с достаточным основанием рассматриваться как показатель, характеризующий генеральную совокупность в целом.
36
В целях выполнения правила репрезентативности (представительности) проводимого исследования тщательно подбирается метод отбора элементов выборки из генеральной совокупности. Как доказано в ряде теорем математической статистики, таким способом при условии достаточно большой выборки является метод случайного отбора элементов генеральной совокупности. При таком отборе каждый элемент генеральной совокупности имеет равный с другими элементами шанс попасть в выборку. Выборки, полученные таким способом, называются случайными (рандомизирован-
ными) выборками. Случайность выборки является, таким образом, существенным условием применения выборочного метода.
Кроме того, необходимо определить объем выборки, то есть число изучаемых единиц. Обоснованный объем выборки не зависит от размера генеральной совокупности. Например, для отдельной площадки он может быть не больше, чем для ареала в целом.
4.6Доверительный интервал. Определение объема выборки
С помощью методов математической статистики может быть определен вероятностно обоснованный объем выборки, позволяющий получить данные с определенной точностью и достоверностью.
Определим некоторые понятия математической статистики, необходимые для ее расчета.
В статистике изменчивость признака характеризуется его вариацией. Например, количество определенного вида бактерий в пробах почв на различных участках будет различным, т. е. варьирует.
Вариация – это степень несхожести измерения признака.
37
В качестве меры вариации обычно принимается среднеквадратическое отклонение (стандартная ошибка, стандартное отклонение), которое характеризует отличие отдельных величин признака от средней величины.
Доверительный интервал – это диапазон величин признака, куда попадает определенный процент измерений.
Доверительный интервал прямо пропорционален стандартному отклонению и тем шире, чем выше доверительная вероятность, к которой по мере роста объема выборки приближается доля попавших в интервал величин измерений. (Уровень доверительной вероятности определяется степенью важности (ответственности) выводов или степенью точности проводимых исследований). Для биологических и экологических исследований обычно принимается 95 %-й уровень доверительной вероятности.
Пусть, к примеру, мы каким-то образом установили математическое ожидание концентрации примесей в атмосферном воздухе. Но этого недостаточно – необходимо хотя бы оценить степень колебания этой концентрации, ответить на вопрос – а какова вероятность того, что она будет лежать в таких-то пределах?
Такие задачи решаются безо всяких проблем, если установить факт принадлежности данной случайной величины к такому классическому распределению как нормальное. Так как для «теоретических» законов, каким является нормальный закон распределения, разработаны методы расчета всех показателей распределения, зафиксированы связи между ними, построены алгоритмы расчета.
Обратим внимание на еще одно важное обстоятельство: даже если нам достаточно одного единственного показателя
– среднее значение данной случайной величины – то и в этом случае возникает вопрос о надежности данных об этом показателе.
38

Пример. Дано выборочное распределение случайной величины X (например, количественное содержание мезофауны в пробах почвы в виде 100 наблюдений над этой величиной). Необходимо оценить интервал, куда с доверительной вероятностью 95 % попадет среднее значение этого показателя в генеральной совокупности.
Решение. Если, например, уже доказана (точнее – принята) гипотеза о нормальном распределении, то интервал для генеральной средней можно выразить так:
|
|
|
|
|
(4.2) |
( x tSx / |
n; x tSx / n ), |
||||
где x – среднее значение случайной величины; Sx – стандартное отклонение;
n – объем выборки;
t – нормированное отклонение, которое выбирается в зависимости от уровня доверительной вероятности (таблица 4.1.).
Таблица 4.1 – Значение отклонения доверительного интервала t от среднего значения в зависимости от доверительной вероятности (Р) результатов
Р, % |
60 |
70 |
80 |
90 |
95 |
97 |
99 |
99,73 |
t |
0,84 |
1,03 |
1,29 |
1,65 |
1,96 |
2,18 |
2,58 |
3,0 |
|
|
|
|
|
|
|
|
|
Пусть мы рассчитали среднее Мх и оно составило 125 экз./м2 при колебаниях от 50 до 200 экз./м2 и выборке 100 наблюдений. Рассчитаем Sx = 5 экз./м2. По специальной таблице находим нормированное отклонение (для доверительной вероятности 95 % оно равно 1,96). Тогда доверительный интервал окажется следующим: (125–1,96∙5/10; 125+1,96∙5/10) или (124; 126) экз./м2. Это означает, что с до-
верительной вероятностью 95 % можно утверждать, что генеральная средняя находится между 124 и 126 экз./м2.
39
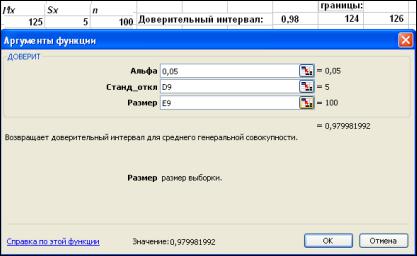
Рисунок 4.2 – Расчет доверительного интервала в EXCEL
Этот же результат получаем в электронной таблице EXCEL, используя встроенную функцию «доверительный интервал» fx = ДОВЕРИТ(0,05;5;100) (Рисунок 4.2). Для этого надо записать в ячейки значения среднего, стандартного отклонения и размера выборки, нажать на fx, выбрать из списка «статистические» функцию ДОВЕРИТ и заполнить три ее аргумента – уровень значимости (Альфа), стандартное отклонение (Станд_откл) и размер выборки (Размер) либо непосредственно числами, либо ссылками на ячейки, где эти значения записаны. Так на рисунке 4.2. это ссылки на ячейки D9 и Е9. Уровень значимости ( ), напомним это «1–вероятность» , если вероятность выражена в долях или «(100-вероятность)/100», если вероятность – в процентах. Так для принятой 95 % вероятности = 0,05. Программа рассчитывает доверительный интервал (в нашем примере 0,98 с точностью до второго знака), а отнимая его от среднего значения и прибавляя к нему, получаем границы генеральной средней (124 и 126 экз./м2). Заметим, что расчеты среднего значения и стандартного отклонения по исходной
40