

belyuchenko_i_s_smagin_a_v_i_dr_analiz_dannykh_i_matematiche
.pdfтельная информация позволяет заранее определить число кластеров.
10.5Пример процедуры кластеризации в пакете
STATISTICA
В кластерном анализе разбиение на кластеры существенно зависит от абсолютных значений исходных данных. Эту проблему решают с помощью нормировки (стандартизации). Для этого из всех значений по каждому фактору вычитают выборочное среднее этого фактора и полученные разности делят на среднее квадратическое отклонение.
х |
х х |
, |
(10.4) |
|
S |
||||
|
|
|
где x – исходное данное;
х – выборочное среднее;
|
1 |
|
n |
|
S |
|
(xi x)2 , – среднее квадратическое отклонение. |
||
n 1 |
||||
|
i 1 |
|||
|
|
|
||
При этом стандартизованные значения будут иметь выборочные средние равные нулю, а выборочные дисперсии – равные единице. Другими словами, мы все факторы свели в одну весовую категорию. Для осуществления этой операции в пакете STATISTICA нужно вызвать модуль Data Management (Стандартизация).
Предполагается, что матрица исходных данных имеет вид Х[n,k], где n –количество, k – количество факторов. Поэтому при кластеризации элементов в пакете STATISTICA следует выбирать режим: cases (rows) – строки, а при кластеризации факторов: variables (columns) – столбцы.
Пример. В этом примере будут исследованы 20 стран с целью оценки их социально-экономического благополучия. В качестве переменных используются следующие характе-
121
ристики: число врачей на 10000 населения; смертность на 100000; ВВП по ППС, в % к США; Расходы на здравоохранение, в % к ВВП; Урожайность зерновых и зернобобовых, ц/га. Исходные данные представлены в таблице 10.1.
Таблица 10.1 – Исходные данные для классификации стран по соответствующим показателям (1994 г.)
|
Число |
Смерт- |
ВВП |
Расходы |
Урожай- |
|
|
врачей |
ность |
||||
|
ность на |
по |
на здра- |
|||
|
на |
зерновых |
||||
Страны |
100 000 |
ППС, в |
вохра- |
|||
10 000 |
и зерно- |
|||||
|
населе- |
% к |
нение, в |
|||
|
насе- |
бобовых, |
||||
|
ния |
США |
% к ВВП |
|||
|
ления |
ц / га |
||||
|
|
|
|
|||
Россия |
44,5 |
84,98 |
20,4 |
3,2 |
14,4 |
|
Австралия |
32,5 |
30,58 |
71,4 |
8, 5 |
11,6 |
|
Австрия |
33,9 |
38,42 |
78,7 |
9,2 |
56,1 |
|
Азербайджан |
38,8 |
60,34 |
12,1 |
3,3 |
16,4 |
|
Армения |
34,4 |
60,22 |
10,9 |
3,2 |
13,5 |
|
Беларусь |
43,6 |
60,79 |
20,4 |
5,4 |
22,4 |
|
Бельгия |
41 |
29,82 |
79,7 |
8,3 |
65,5 |
|
Болгария |
36,4 |
70,57 |
17,3 |
5,4 |
27,8 |
|
Великобритания |
17,9 |
34,51 |
69,7 |
7,1 |
62,3 |
|
Венгрия |
32,1 |
64,73 |
24,5 |
6 |
39,8 |
|
Германия |
38,1 |
36,63 |
76,2 |
8,6 |
56,9 |
|
Греция |
41,5 |
32,84 |
44,4 |
5,7 |
37,4 |
|
Грузия |
55 |
62,64 |
11,3 |
3,5 |
18,6 |
|
Дания |
36,7 |
34,07 |
79,2 |
6,7 |
54,4 |
|
Ирландия |
15,8 |
39,27 |
57 |
6,7 |
64,2 |
|
Испания |
40,9 |
28,46 |
54,8 |
7,3 |
22,6 |
|
Италия |
49,4 |
30,27 |
72,1 |
8,5 |
46 |
|
Казахстан |
38,1 |
69,04 |
13,4 |
3,3 |
7,9 |
|
Канада |
27,6 |
25,42 |
79,9 |
10,2 |
25,4 |
|
Киргизия |
33,2 |
53,13 |
11,2 |
3,4 |
17 |
|
|
|
|
|
|
|
Экспортируем исходные данные из электронных таблиц EXCEL в программу STATISTICA и стандартизируем их,
122

вызвав процедуру Данные/Стандартизация. Получим стандартизованные значения исходных данных (рисунок 10.2).
Рисунок 10.2 – Стандартизация данных
Переключимся в модуль Многомерные исследователь-
ские методы и выберем Анализ кластера, затем в выпавшем окне выберем команду Analysis/Joining (tree clustering). Оп-
ределим все переменные, метод и меру расстояния. Нажмем
OK.
123
Рисунок 10.3 – Выбор модуля для расчета
Рисунок 10.4 – Выбор кластерного метода
В поле Кластер задается направление классификации. При кластеризации самих переменных помечаются Variables (переменные – столбцы), в данной задаче Cаses (наблюдения – строки).
124
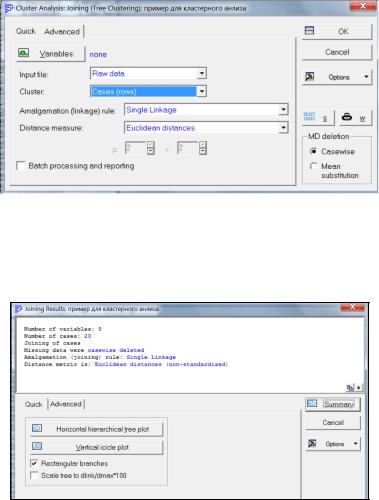
Вкачестве меры сходства в окошке Amalgation [linkage] rule устанавливаем Single Linkage (Метод одиночной связи «принцип ближайшего соседа»).
Вокошке Distance measure (Мера расстояния d) выбираем Euclidean distances (Евклидово расстояние).
Рисунок 10.5 – Определение параметров кластеризации
Появляется соответствующее диалоговое окно, в котором необходимо определить расположение графика (вертикальное или горизонтальное). Нажмем OK.
Рисунок 10.6 – Выбор вида диаграммы
125

Выбрав тип графика «вертикальный», получим следующую диаграмму.
Рисунок 10.7 – Диаграмма кластеризации
На данной дендрограмме горизонтальная ось представляет наблюдения, вертикальная – расстояние объединения. Таким образом, на первом шаге были объединены Дания и Германия, как имеющие минимальное расстояние, а на последнем – все уже объединенные в какие-либо кластеры.
Щелкнув по кнопке Amalgamation schedule (Схема объединения), можно выбрать таблицу результатов со схемой объединения. Первый столбец таблицы содержит расстояния для соответствующих кластеров. Каждая строка показывает состав кластера на данном шаге классификации. Например, на первом шаге (1 строка) объединились Германия и Дания, на втором (2 строка) – Австрия, Германия и Дания, на третьем – Армения и Киргизия и т. д.
126
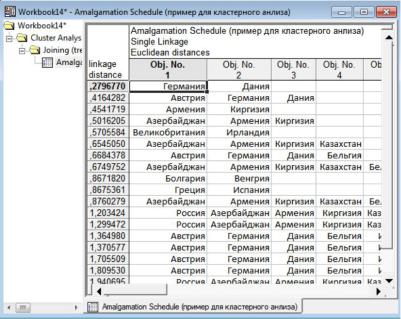
Рисунок 10.8 – Схема объединения данных в кластеры
Вкачестве основных методов анализа пакет
STATISTICA предлагает Joining (tree clustering) – группу иерархических методов (7 видов), которые используются в том случае, если число кластеров заранее неизвестно, и K-Means Clustering (метод К-средних), в котором пользователь заранее определяет количество кластеров.
Вгруппу иерархических методов входит Ward’s method
–метод Уорда, который хорошо работает с небольшим количеством элементов и нацелен на выбор кластеров с примерно одинаковым количеством членов.
Многообразие алгоритмов кластерного анализа часто дезориентирует пользователя. Поэтому он может прибегнуть к применению нескольких алгоритмов и отдать предпочтение какому-либо выводу на основании комплексной оценки совокупности результатов работы.
127
10.6Сущность и вычислительный подход дискриминантного анализа
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более совокупности (группы). Приведем примеры его использования.
Исследователь в области образования может захотеть установить, какие переменные относят выпускника университета к одной из трех категорий: (1) поступающий в аспирантуру, (2) работающий по специальности, или (3) не работающий по специальности. Для этой цели он должен собрать данные о различных переменных, связанных со студентами. После выпуска большинство студентов, естественно, попадут в одну из названных категорий. Дискриминантный анализ позволяет определить, какие переменные дают наилучшее предсказание выбора студентами дальнейшего пути.
Эколог может зарегистрировать характерные признаки проб почв из различных природно-климатических зон, например, такие, как общее количество фосфора и азота в процентах сухого вещества, рН почвы, наличие влаги и т. д., чтобы выяснить, какие характеристики определяют тип почвы, а затем относить каждую пробу к той или иной природ- но-климатической зоне.
На основании достаточно обширного экспериментального материала известны средние характеристики одного и того же вида животных или растений, занимающих разные экологические ниши. Экземпляры из разных мест обитания будут, как правило, отличаться по численным значениям некоторых характеристик. Если в распоряжении исследователя оказались одна или несколько особей, для которых известно, что они взяты из одного какого-то места обитания, но не известно из какого именно, то решить вопрос об их
128
принадлежности к той или иной экологической нише можно
спомощью дискриминантного анализа.
Свычислительной точки зрения дискриминантный анализ похож на дисперсионный анализ. Основная его идея заключается в том, чтобы определить, отличаются ли совокупности по среднему какой-либо переменной (или линейной комбинации переменных), и затем использовать эту переменную, чтобы предсказать для новых членов их принадлежность к той или иной группе.
10.7Метод главных компонент и факторный анализ
Главными целями факторного анализа являются:
–сокращение числа переменных (редукция данных);
–определение структуры взаимосвязей между переменными, т. е. классификация переменных.
Поэтому факторный анализ используется или как метод сокращения данных или как метод классификации.
Опишем принципы факторного анализа и способы его применения для достижения этих двух целей.
Факторный анализ как метод редукции данных. Пред-
положим, вы хотите измерить удовлетворенность людей экологической обстановкой в городе, для чего составляете вопросник с различными пунктами; среди других вопросов задаете следующие: удовлетворены ли люди экологической обстановкой в городе (пункт 1) и как интенсивно они стараются ее улучшить (пункт 2).
Результаты преобразуются так, что средние ответы (например, для удовлетворенности) соответствуют значению 100, в то время как ниже и выше средних ответов расположены меньшие и большие значения, соответственно. Две переменные (ответы на два разных пункта) коррелированны между собой.
129
Из высокой коррелированности двух этих переменных можно сделать вывод об избыточности двух пунктов опросника.
Объединение двух переменных в один фактор. Зависи-
мость между переменными можно обнаружить с помощью диаграммы рассеяния. Полученная путем подгонки линия регрессии, дает графическое представление зависимости.
Если определить новую переменную на основе линии регрессии, изображенной на диаграмме, то такая переменная будет включить в себя наиболее существенные черты обеих переменных. Итак, фактически, вы сократили число переменных и заменили две одной. Отметим, что новый фактор (переменная) в действительности является линейной комбинацией двух исходных переменных.
Анализ главных компонент. Пример, в котором две кор-
релированные переменные объединены в один фактор, показывает главную идею факторного анализа или, более точно, анализа главных компонент. Если пример с двумя переменными распространить на большее число переменных, то вычисления становятся сложнее, однако основной принцип представления двух или более зависимых переменных одним фактором остается в силе.
Выделение главных компонент. В основном процедура выделения главных компонент подобна вращению, максимизирующему дисперсию (варимакс) исходного пространства переменных.
Например, на диаграмме рассеяния вы можете рассматривать линию регрессии как ось X, повернув ее так, что она совпадает с прямой регрессии. Этот тип вращения называется вращением, максимизирующим дисперсию, так как критерий (цель) вращения заключается в максимизации дисперсии (изменчивости) «новой» переменной (фактора) и минимизации разброса вокруг нее.
Обобщение на случай многих переменных. В том случае,
когда имеются более двух переменных, можно считать, что
130