

27. Проверка параметров уравнения и показателей тесноты связи на существенность.
Коэффициент корреляции определяется по выборочным данным.
Линейный коэффициент корреляции оценивает тесноту связи рассматриваемых признаков в ее линейной форме. При нелинейном виде модели связь может оказаться достаточно тесной.
Квадрат линейного коэффициента корреляции называется коэффициентом детерминации. Он характеризует долю дисперсии результативного показателя y, объясняемую регрессией.
После того как построено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных ее параметров.
Оценка значимости уравнения регрессии в целом производится с помощью F-критерия Фишера.
С F-критерием тесно связана характеристика, называемая числом степеней свободы, которая применительно к исследуемой проблеме показывает, сколько независимых отклонений из n-возможных .
Проверка осуществляется на основе дисперсионного анализа
Fфак=Sв квадрате межгр/S в квадрате ост
Sв квадрате ост = Wост/ n-K
K-число параметров уравнения
Sв квадрате межгр= w межг/K-1
Tar=ar (квадратный корень n-2)/Gy
A1(b) ta(b)=a1 (квадратный корень n-2)Gx/Gy
Fr=R в квадрате/1- R в квадрате * n-m/n-1
Fr>Fk
Основной смысл проверка на существенность
28. Многомерные методы анализа и группировки: виды и содержание.
- раздел математич. статистики, посвященный математич. методам построения оптимальных планов сбора, систематизации и обработки многомерных статистич. данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практич. выводов.
Цель этих методов — классификация данных, иначе говоря, группировка на основе множества признаков.
Простейшим вариантом многомерной классификации является группировка на основе многомерных средних.
Многомерной средней называется средняя величина нескольких признаков для одной единицы совокупности.

где pj - многомерная средняя для i-единицы;
хij - значение признака х, для г-единицы;
хj - среднее значение признака xi,
k - число признаков;
j - номер признака;
i - номер единицы совокупности.
При большом объеме совокупности для выделения групп на основе многомерной средней необходимо установить интервалы значений многомерной средней;

1) кластерный анализ (таксономия) состоит в разбиении совокупности на классы (группы, типы, «кластеры», «таксоны»), границы которых наперед не заданы. Число кластеров может быть при этом задано или нет; з.
Каждая единица совокупности в кластерном анализе рассматривается как точка в заданном признаковом пространстве. Значение каждого из признаков у данной единицы служит ее координатой в этом «пространстве». Признаковое пространство - это область варьирования всех признаков совокупности изучаемых явлений.
Если мы уподобим это пространство обычному пространству, имеющему евклидову метрику, то тем самым мы получим возможность измерять «расстояния» между точками признакового пространства. Эти расстояния называют евклидовыми. Их вычисляют по тем же правилам, как и в обычной евклидовой геометрии.
В многомерном признаковом пространстве расстояние между точками р и q с k координатами:
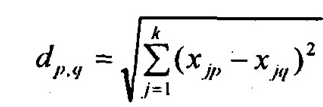
«Нормированная разность»

xjp-xjq – абсолютная разность
бxj – среднее квадратическое отклонение признака xj
Алгоритм:
1) вычисление средних величин каждого из классификационных признаков х?j в целом по совокупности;
2) вычисление средних квадратических отклонений каждого из признаков по совокупности – sxj или ?xj,
3) вычисление матриц нормированных разностей по каждому из группировочных признаков – djp,q;
4) вычисление евклидовых расстояний между каждой парой сочетаний единиц совокупности – dp,q;
5) выбор наименьшего из евклидовых расстояний – dp,qmin;
6) объединение единиц совокупности с наименьшим евклидовым расстоянием между ними в один кластер;
7) вычисление средних значений всех признаков для единиц, объединенных в кластер;
8) вычисление новых нормированных расстояний между объединенным кластером и остальными единицами;
9) вычисление новых евклидовых расстояний между объединенным кластером и остальными единицами (или кластерами);
10) выбор наименьшего из евклидовых расстояний;
11) повторение операций (6-10) и т.д.
Объединение в кластеры прекращается, когда все евклидовы расстояния превысят заданную критическую величину dкрит.
Взвешенное евклидово
расстояние (для разных «весов»
группировочных признаков)
W-вес признака (доля)
2) дискриминантный анализ состоит в установлении правила, на основании которого та или иная новая единица не может быть отнесена к данной совокупности объектов, имея в виду значения рассматриваемых у нее признаков;
3) распознавание образов состоит в отнесении объекта на основании сочетания признаков в ту или другую из заранее определенных и охарактеризованных групп совокупности;
4) метод главных компонент - если признаки отобраны правильной в них действительно отражается качественная природа объектов в рассматриваемом отношении, то эти признаки оказываются друг с другом связанными;
5) факторный анализ является дальнейшим развитием метода главных компонент. В нем охватываемая выделенными -главными компонентами» У вариация всех признаков X может затем между ними перераспределяться, причем между ними может быть допущена и корреляция.