

16.Матричные микропроцессоры
Матричные микропроцессоры можно рассмотреть с двух сторон: на уровне транзисторных матриц и матриц процессоров.
Использование матриц при проектировании процессоров может быть двухсторонним: матрицы транзисторов для проектирования микропроцессоров и матрицы микропроцессоров для проектировании процессорных систем.
Использование матриц при построении процессорных систем не ограничивается соединением процессоров по конвейерному принципу. Подобную архитектуру можно использовать также и при проектировании ИС с использованием транзисторных матриц, выполненных по МОП-технологии. Рассмотрим оба варианта применения матриц.
ТРАНЗИСТОРНЫЕ МАТРИЦЫ
Сокращение сроков проектирования микропроцессоров и повышение надежности проектов требуют применения соответствующих систем автоматизации проектирования. Одним из самых перспективных направлений в настоящее время считается подход к сквозной автоматизации проектирования, называемой кремниевой компиляцией, позволяющий исходное задание на проектирование - функциональное описание, представленное на языке высокого уровня, преобразовать в топологические чертежи. Кремниевые компиляторы используют в качестве базовых регулярные матричные структуры, хорошо приспособленные к технологии СБИС. Большое распространение получили программируемые логические матрицы (ПЛМ) и их различные модификации. Они ориентированы на матричную реализацию двухуровневых (И, ИЛИ) логических структур, а также для оптимизации их параметров (площади, быстродействия) известны различные методы. Реализация многоуровневых логических структур СБИС часто опирается на матричную топологию: в этом случае компиляторы генерируют топологию по ее матричному описанию.
Транзисторные матрицы
Особым стилем реализации топологии в заказных КМОП СБИС являются транзисторные матрицы. В лэйауте (англ. layout - детальное геометрическое описание всех слоев кристалла) транзисторных матриц все p-транзисторы располагаются в верхней половине матрицы, а все n-транзисторы - в нижней. Транзисторные матрицы имеют регулярную структуру, которую составляют взаимопересекающиеся столбцы и строки. В столбцах матрицы равномерно расположены полосы поликремния, образующие взаимосвязанные затворы транзисторов. По другим полюсам транзисторы соединяются друг с другом сегментами металлических линий, которые размещаются в строках матрицы. Иногда, для того чтобы соединить сток и исток транзисторов, находящихся в различных строках, вводят короткие вертикальные диффузионные связи. В дальнейшем ТМ будет представляться абстрактным лэйаутом.
Абстрактный лэйаут - схематический рисунок будущего кристалла, где прямоугольники обозначают транзисторы, вертикальные линии - поликремниевые столбцы, горизонтальные - линии металла, штриховые - диффузионные связи, точки - места контактов, стрелки - места подключения транзисторов к линиям Gnd и Vdd. При переходе к послойной топологии стрелки должны быть заменены полосками в диффузионном слое, по которому осуществляются соединения между строками ТМ.
На рис. 1.а представлена транзисторная схема, а на рис. 1.б - транзисторная матрица, реализующая данную схему.
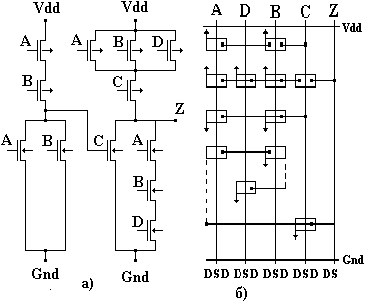
Символическое представление топологии транзисторных матриц.
Одной из завершающих стадий получения топологии транзисторных матриц является переход от символического лэйаута к топологическому описанию схемы на уровне слоев. Символические лэйауты конструируются путем размещения символов не решетке, которая служит для создания топологии заданной схемы. Каждый символ представляет геометрию, которая может включать любое число масочных уровней. Схемотехника транзисторных матриц позволяет использовать небольшое число различных символов, требуемых для описания лэйаута:
N - n-канальный транзистор;
P - p-канальный транзистор;
+ - надпересечение - металл над диффузией; металл над поликремнием; пересекающиеся вертикальный и горизонтальный металлы;
![]() -
контакт (к поликремнию либо диффузии);
-
контакт (к поликремнию либо диффузии);
! - p-диффузия;
![]() -
n-диффузия,
либо поликремний;
-
n-диффузия,
либо поликремний;
: - металл в вертикальном направлении;
![]() -
металл в горизонтальном направлении.
-
металл в горизонтальном направлении.
Каждый символ транзистора соответствует транзистору минимального размера. Однако ширина канала может увеличиваться многократным повторением символа. Только один символ “+” требуется для того, чтобы обозначить пересечение всех трех уровней взаимосвязей: а именно, металл над диффузией, металл над поликремнием и пересекающийся вертикальный и горизонтальный металлы. Символ контакта “ ” используется для того, чтобы определить контакт металла к поликремнию или диффузии. Символ “ ” используется для представления либо поликремниевых, либо n-диффузионных проводников. Символ для диффузии p-типа “!” требуется для различия ее от диффузии n-типа, которая может существовать в том же столбце. Символы для металла “:” либо “-” обозначают вертикальные или горизонтальные линии металла соответственно. На рис. 1.в. дано символьное представление лэйаута транзисторной матрицы, а на рис. 1.г. - заключительный лэйаут.
Если логическая схема построена на базе элементов, для которых нет транзисторных описаний в библиотеках, то возникает сложная задача получения требуемых представлений схемы, особенно, когда имеются дополнительные требования к параметрам - площади, быстродействию и т.д. Задача перехода от логического описания комбинационной логики в одном базисе к описанию в другом базисе в настоящее время решается по нескольким направлениям.
Глобальная оптимизация. Сначала осуществляется переход к системе дизъюнктивных нормальных форм (ДНФ), которая обычно минимизируется, а затем представляется в виде многоуровневой логической сети, реализуемой в требуемом базисе. Основная оптимизация ведется при построении многоуровневой сети - обычно это сеть в базисе И, ИЛИ, НЕ, а основным критерием сложности является критерий числа литералов (букв) в символическом (алгебраическом) представлении булевых функций. Методы оптимизации опираются либо на функциональную декомпозицию, либо на факторизацию (поиск общих подвыражений) в алгебраических скобочных представлениях функций, реализуемых схемой. Заключительный этап - реализацию в требуемом базисе принято называть технологическим отображением. Именно на этом этапе можно оценить максимальную задержку схемы - задержку вдоль критического пути. Предполагается, что в узлах схемы установлены базисные элементы.
Локальная оптимизация. Замена одних базисных логических операторов другими осуществляется путем анализа локальной области схемы. Поиск фрагментов и правила их замены другими может осуществляться с помощью экспертной системы. Так, например, устроена система LSS.
Подробно обзор многих методов оптимизации многоуровневых логических схем приведен в [0].
МАТРИЧНЫЕ ПРОЦЕССОРЫ
Матричные процессоры наилучшим образом ориентированы на реализацию алгоритмов обработки упорядоченных (имеющих регулярную структуру) массивов входных данных. Они появились в середине 70-х годов в виде устройств с фиксированной программой, которые могли быть подключены к универсальным ЭВМ; но к настоящему времени в их программирования достигнута высокая степень гибкости. Зачастую матричные процессоры используются в качестве вспомогательных процессоров, подключенных к главной универсальной ЭВМ. В большинстве матричных процессоров осуществляется обработка 32-х разрядных чисел с плавающей запятой со скоростью от 5000000 до 50000000 флопс. Как правило они снабжены быстродействующими портами данных, что дает возможность для непосредственного ввода данных без вмешательства главного процессора. Диапазон вариантов построения матричных процессоров лежит от одноплатных блоков, которые вставляются в существующие ЭВМ, до устройств, конструктивно оформленных в виде нескольких стоек, которые по существу представляют собой конвейерные суперЭВМ.
Типичными видами применения матричных процессоров является обработка сейсмической и акустической информации, распознавание речи; для этих видов обработки характерны такие операции, как быстрое преобразование Фурье, цифровая фильтрация и действия над матрицами. Для построения относительно небольших более экономичных в работе матричных процессоров используются разрядно-модульные секции АЛУ в сочетании с векторным процессором, основанном на основе биполярного СБИС-процессора с плавающей запятой.
Вероятно, в будущем матричные процессоры будут представлять собой матрицы процессоров, служащие для увеличения производительности процессоров сверх пределов, установленных шинной архитектурой.
Для реализации обработки сигналов матрицы МКМД могут быть организованы в виде систолических или волновых матриц.
Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседними посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном процессоре по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающий на все элементы.
В волновой матрице происходит распределение функций между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице.
АВТОМАТИЗАЦИЯ ПРОЕКТИРОВАНИЯ ЦИФРОВЫХ СБИС НА БАЗЕ МАТРИЦ ВАЙНБЕРГЕРА И ТРАНЗИСТОРНЫХ МАТРИЦ
Введение. Все большую долю в общем объеме ИС составляют заказные цифровые ИС, выполненные в основном, по МОП-технологии. Сокращение сроков проектирования и повышение надежности проектов требуют применения соответствующих систем автоматического проектирования. Одним из самых перспективных направлений в настоящее время считается подход к сквозной автоматизации проектирования, называемой кремниевой компиляцией, позволяющей исходное задание на проектирование - функциональное описание, представленное на языке программирования высокого уровня, преобразовать в топологические чертежи. Кремниевые компиляторы используют в качестве базовых регулярные матричные структуры, хорошо приспособленные к технологии СБИС. Большое распространение получили программируемые логические матрицы (ПЛМ) и их различные модификации. Они ориентированы на матричную реализацию двухуровневых (И, ИЛИ) логических структур, а также для оптимизации их параметров (площади, быстродействия) известны различные методы.
Заключительный этап - реализацию в требуемом базисе принято называть технологическим отображением. Именно на этом этапе можно оценить максимальную задержку схемы - задержку вдоль критического пути. Предполагается, что в узлах схемы установлены базисные элементы.
Локальная оптимизация. Замена одних базисных логических операторов другими осуществляется путем анализа локальной области схемы. Поиск фрагментов и правила их замены другими может осуществляться с помощью экспериментальной системы. Так, например, устроена система LSS.
Оптимизация МВ на логическом уровне представляет более простую задачу. На этом этапе обычно минимизируется число операторов f = k1 V ... V kl - по существу число столбцов МВ. Минимизация числа строк происходит на этапе топологического проектирования.
Подробно обзор многих методов оптимизации многоуровневых логических схем приведена в [4]. Заключая данный раздел, можно сказать, что актуальной проблемой является проблема разработки методов оптимизации многоуровневых структур с учетом последующей базовой топологической реализации. Проблема осложняется тем, что нужно выработать еще соответствующие критерии оптимизации. Если для ПЛМ критерий минимальности числа термов адекватен сложности последующей топологической реализации, то для МВ и, особенно для ТМ, типичной дилеммой при минимизации площади является следующая - провести дополнительную связь, либо установить дополнительный элемент. Может оказаться так, что сильная связность схемы может быть неприемлемой из-за больших затрат площади кристалла под соединения элементов.
Заключение. В обзоре представлены основные подходы к проектированию структур заказных цифровых СБИС на базе основных моделей матриц Вайнбергера и транзисторных матриц.
Модификация основной модели МВ, когда снимаются требования подключения каждого столбца к линии “земли”; реализация каждой переменной только в одной стоке матрицы; невозможности дублирования линий “земли” и нагрузки; приводит к новым формальным постановкам задач оптимизации параметров МВ, хотя и для основной модели не все проблемы решены - открыта, например, проблема синтеза МВ с заданным быстродействием.
Таким образом, важнейшими проблемами, решаемыми в настоящее время для МВ и ТМ, являются проблемы разработки формальных методов синтеза, которые позволяли бы гибко оптимизировать такие характеристики, как площадь, быстродействие, габариты, электрические параметры схем. Данные проблемы в настоящее время актуальны не только для МВ и ТМ - подобные проблемы находятся в центре внимания разработчиков САПР заказных цифровых СБИС и применительно к другим базовым структурам.
Матричные процессоры
Матричные процессоры наилучшим образом ориентированы на реализацию алгоритмов обработки упорядоченных (имеющих регулярную структуру) массивов входных данных. Они появились в середине 70-ых годов в виде устройств с фиксированной программой, которые могли быть подключены к универсальным ЭВМ; но к настоящему времени в их программировании достигнута высокая степень гибкости. Зачастую матричные процессоры используются в качестве вспомогательных процессоров, подключаемых к главной универсальной ЭВМ. В большинстве матричных процессоров осуществляется обработка 32 разрядных циклов с плавающей запятой со скоростью от 5000000 до 50000000 флопс. Как правило, они снабжены быстродействующими портами данных, что дает возможность для непосредственного ввода данных без вмешательства главного процессора. Диапазон вариантов построения матричных процессоров лежит от одноплатных блоков, которые вставляются в существующие ЭВМ до устройств, конструктивно оформленных в виде нескольких стоек, которые по существу представляют собой конвейерные суперЭВМ.
Типичными видами применения матричных процессоров является обработка сейсмической и акустической информации, распознавание речи; для этих видов обработки характерны такие операции, как быстрое преобразование Фурье, цифровая фильтрация и действия над матрицами. Для построения относительно небольших более экономичных в работе матричных процессоров используются разрядно-модульные секции АПУ в сочетании с векторным процессором, реализованным на основе биполярного СБИС-процессора с плавающей запятой.
Вероятно, в будущем матричные процессоры будут представлять собой матрицы процессоров, служащие для увеличения производительности процессоров сверх пределов, установленных шинной архитектурой.
Главным архитектурным различием между традиционными ЭВМ, предназначенными для обработки научной и коммерческой информации, является то, что последние (мини-, супермини-, универсальные и мега-универсальные ЭВМ) имеют главным образом скалярную архитектуру, а машины для научных расчетов (супер-, минисупер-ЭВМ и матричные процессоры) - векторную. Скалярная ЭВМ (рис. 1.) имеет традиционную фон-неймановскую, то есть SISD-организацию, для которой характерно наличие одной шины данных и последовательное выполнение обработки одиночных элементов данных. Векторная машина (рис. 2.) имеет в своем составе раздельные векторные процессоры или конвейеры, и одна команда выполняется в ней над несколькими элементами данных (векторами)
Векторные архитектуры - это в основном архитектуры типа SISD, но некоторые из них могут относиться к классу MIMD. Векторная обработка увеличивает производительность процессорных элементов, но не требует наличия полного параллелизма в ходе обработки задачи.
Для реализации обработки сигналов матрицы МЛМД могут быть реализованы в виде систолических или волновых матриц.
Систолическая матрица состоит из отдельных процессорных узлов, каждый из которых соединен с соседним посредством упорядоченной решетки. Большая часть процессорных элементов располагает одинаковыми наборами базовых операций, и задача обработки сигнала распределяется в матричном процессоре по конвейерному принципу. Процессоры работают синхронно, используя общий задающий генератор тактовых сигналов, поступающий на все элементы.
В волновой матрице происходит распределение функций между процессорными элементами, как в систолической матрице, но в данном случае не имеет места общая синхронизация от задающего генератора. Управление каждым процессором организуется локально в соответствии с поступлением необходимых входных данных от соответствующих соседних процессоров. Результирующая обрабатывающая волна распространяется по матрице по мере того, как обрабатываются входные данные, и затем результаты этой обработки передаются другим процессорам в матрице.
МКМД (множественный поток команд, множественный поток данных.) Множественный поток команд предполагает наличие нескольких процессорных узлов и, следовательно, нескольких потоков данных. Примерами такой архитектуры являются мультипроцессорные матрицы.
Транспьютер Inmos Т414 предназначен для построения МКМД структур; для обмена информацией с соседними процессорами в нем предусмотрены четыре быстродействующие последовательных канала связи. Имеется встроенная память большой емкости, которая может быть подключена к интерфейсу шины памяти. Разрядность местной памяти каждого транспьютера наращивает разрядность памяти системы; таким образом, полная разрядность памяти пропорциональна количеству транспьютеров в системе. Суммарная производительность также возрастает прямо пропорционально числу входящих в систему транспьютеров.
В дополнение к параллельной обработке, реализуемой транспьютерами, предусмотрены специальные команды для разделения процессорного времени между одновременными процессорами и обмена информацией между процессорами. Хотя программирование транспьютеров может выполняться на обычных языках высокого уровня, для повышения эффективности параллельной обработки был разработан специальный язык Okkam.
Транзисторные матрицы (ТМ) являются одной из популярных структур для проектирования топологии макроэлементов заказных цифровых СБИС, выполняемых по КМОП-технологии, ТМ имеют регулярную матричную топологию, получение которой может быть автоматизировано, что привлекает к ним разработчиков кремниевых компиляторов. Известные методы проектирования ТМ ориентированы на минимизацию площади кристалла, занимаемую информационными транзисторами, и оставляет в стороне вопрос о минимизации площади, требуемой для разводки шин “земли” (Gnd) и “питания” (Vdd). В данной статье предлагается метод минимизации числа шин Gnd и Vdd в ТМ, после того, как ее площадь была минимизирована с помощью методов [4,5].
Структура ТМ.
В лэйауте (англ. layout - детальное геометрическое описание всех слоев кристалла) транзисторных матриц все p-транзисторы располагаются в верхней половине матрицы, а все n-транзисторы - в нижней. Транзисторные матрицы имеют регулярную структуру, которую составляют взаимопересекающиеся столбцы и строки. В столбцах матрицы равномерно расположены полосы поликремния, образующие взаимосвязанные затворы транзисторов. По другим полюсам транзисторы соединяются друг с другом сегментами металлических линий, которые размещаются в строках матрицы. Иногда, для того чтобы соединить сток и исток транзисторов, находящихся в различных строках, вводят короткие вертикальные диффузионные связи. В дальнейшем ТМ будет представляться абстрактным лэйаутом.
Абстрактный лэйаут - схематический рисунок будущего кристалла, где прямоугольники обозначают транзисторы, вертикальные линии - поликремниевые столбцы, горизонтальные - линии металла, штриховые - диффузионные связи, точки - места контактов, стрелки - места подключения транзисторов к линиям Gnd и Vdd. При переходе к послойной топологии стрелки должны быть заменены полосками в диффузионном слое, по которому осуществляются соединения между строками ТМ. Очевидно, что подведению вертикальных связей к линиям Gnd, Vdd могут препятствовать транзисторы, расположенные в других строках транзисторной матрицы, либо расположенные в тех же столбцах диффузионные связи между строками (горизонтальные линии металла не являются препятствием). В следствие этого приходится размещать несколько линий Gnd в n-части ТМ и несколько линий Vdd в p-части ТМ. Возникает задача минимизации числа этих линий. Будем рассматривать ее только для n-части ТМ, задача минимизации числа линий Vdd для p-части ТМ решается аналогичным образом.
Пример абстрактного лэйаута для КМОП-схемы (рис. 1.а.) показан на рис. 1.б.
Формализация задачи.
Пусть транзисторная матрица размером n на m задана абстрактным лэйаутом. Представим последний троичной матрицей S размером n на 2m, поставим ее строки в соответствие строкам ТМ, а пары соседних столбцов - столбцам ТМ. Таким образом, каждый элемент матрицы S представляет некоторую позицию лэйаута и получает значение 1, если там стоит стрелка, значение 0 - если там не показан ни транзистор, ни диффузионная связь, и значение * - в остальных случаях. Легко видеть, что значение * свидетельствует о невозможности проведения через данную точку диффузионной связи от стока некоторого транзистора к линии Gnd.
17. VLIW-архітектура. Архитектура сверхдлинного командного слова (VLIW — Very Long Instruction Word) берет свое начало от параллельного микрокода, применявшегося еще на заре вычислительной техники, и от суперкомпьютеров Control Data CDC6600 и IBM 360/91. В 1970 году многие вычислительные системы оснащались дополнительными векторными сигнальными процессорами, использующими VLIW-подобные длинные инструкции, прошитые в ПЗУ. Эти процессоры применялись для выполнения быстрого преобразования Фурье и других вычислительных алгоритмов. Первыми настоящими VLIW-компьютерами стали мини-суперкомпьютеры, выпущенные в начале 1980 года компаниями MultiFlow, Culler и Cydrome, но они не имели коммерческого успеха. Планировщик вычислений и программная конвейризация были предложены Фишером и Рау (Cydrome). Сегодня это является основой технологии VLIW-компилятора.
Первый VLIW-компьютер компании MultiFlow 7/300 использовал два арифметико-логических устройства для целых чисел, два АЛУ для чисел с плавающей точкой и блок логического ветвления — все это было собрано на нескольких микросхемах. Его 256bit командное слово содержало восемь 32bit кодов операций. Модули для обработки целых чисел могли выполнять две операции за один такт длиной 130ns (т.е. всего четыре при двух АЛУ), что при обработке целых чисел обеспечивало быстродействие около 30 MIPS. Можно было также комбинировать аппаратные решения так, чтобы получать из или 256bit, или 1024bit вычислительные машины. Первый VLIW-компьютер Cydrome Cydra-5 использовал 256bit инструкцию и специальный режим, обеспечивающий выполнение команд как последовательности из шести 40bit операций, поэтому его компиляторы могли генерировать смесь параллельного кода и обычного последовательного. Существует мнение, что в то время, как эти VLIW-ВМ использовали несколько микросхем, процессор Intel i860 стал первым VLIW-процессором на одной микросхеме. Однако, i860 можно отнести к VLIW достаточно условно — по сути у него есть всего лишь программно-управляемое спаривание инструкций, в отличие от более позднего программно-неуправляемого, ставшего частью суперскалярных процессоров. В качестве исторической справки также хотелось бы упомянуть компьютеры фирмы FPS (AP-120B, AP-190L и все более поздние под маркой FPS), также основанные на VLIW-архитектуре, которые были в свое время достаточно распространенными и успешными на рынке. Кроме этого, существовали такие «канонические» машины, как М10 и М13 Карцева, а также «Эльбрус-3» — при всем «неуспехе» последнего проекта, он все же явился этапом VLIW. Вообще, быстродействие VLIW-процессора в большей степени зависит от компилятора, нежели от аппаратуры, поскольку здесь эффект от оптимизации последовательности операций превышает результат, возникающий от повышения частоты.
18. Конвеєрні комп’ютери. Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
19. Суперскалярні комп’ютери. Суперскалярный процессор представляет собой нечто большее, чем обычный последовательный (скалярный) процессор. В отличие от последнего, он может выполнять несколько операций за один такт. Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств. В исполняющих устройствах могут быть конвейеры. Суперскалярные процессоры реализуют параллелизм на уровне команд.
Примером компьютера с суперскалярным процессором является IBM RISC/6000. Тактовая частота процессора у ЭВМ была 62.5 МГц, а быстродействие системы на вычислительных тестах достигало 104 Mflop (Mflop - единица измерения быстродействия процессора - миллион операций с плавающей точкой в секунду). Суперскалярный процессор не требует специальных векторизующих компиляторов, хотя компилятор должен в этом случае учитывать особенности архитектуры.
20. RISC- архітектури. Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к
компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета. Такие компьютеры основаны на архитектуре, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт).
Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC-архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные. Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
21. CISC- архітектури. Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года и дошло до наших дней, например, в таких мейнфреймах как IBM/370, IBM ES/9000, APX i432, "Ельбрус" та ін.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно:
- сравнительно небольшое число регистров общего назначения; - большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; - большое количество методов адресации; - большое количество форматов команд различной разрядности; - преобладание двухадресного формата команд; - наличие команд обработки типа регистр-память.
22. Основні принципи, закладені в розробку архітектур. Переваги та недоліки.
Событийно-ориентированные архитектуры
В событийно-ориентированной архитектуре мы отказываемся от взгляда на исполнение
программы как на последовательный процесс. Вместо этого мы реализуем программу в виде
набора функций или методов-обработчиков, которые вызываются в ответ на возникновение
событий. События могут быть как внешними по отношению к нашей программе (например,
прибытие порции данных из сетевого соединения, сработка таймера или нажатие клавиши
пользователем), так и внутренними. Внутренние события используются для взаимодействия
между разными обработчиками.
Как правило, событийно-ориентированная архитектура предполагает наличие специального
модуля, называемого диспетчером или менеджером событий. Этот модуль тем или иным
образом собирает информацию о возникших событиях, организует сообщения о событиях
и обработчики в очереди в соответствии с теми или иными правилами и вызывает обработчики.
Главная сложность при разработке событийно-ориентированного приложения –
это гарантировать, что все обработчики событий будут завершаться достаточно быстро.
Как правило это означает, что обработчики не должны вызывать блокирующихся системных
вызовов. Если удастся соблюсти это требование, то событийно-ориентированная архитектура
позволяет получить многие преимущества многозадачности и многопоточности
без использования собственно многопоточности. В этом смысле можно даже сказать,
что событийно-ориентированная архитектура – это альтернатива многозадачным
и многопоточным приложениям.
Событийно-ориентированные архитектуры применяются во множестве различных случаев.
Таким образом реализуются программы с графическим пользовательским интерфейсом,
сетевые серверы и некоторые клиентские сетевые программы, приложения реального времени,
игры и др. Ядра большинства современных операционных систем, таких, как Windows, Linux
и BSD Unix, также имеют событийно-ориентированную архитектуру.
Преимущества
1. Высокая производительность. Грамотно разработанное событийно-ориентированное
приложение может одновременно обрабатывать множество событий в рамках одного
потока и одного процесса. Некоторые событийно-ориентированные приложения
обрабатывают сотни и тысячи сетевых соединений в одном потоке.
Недостатки:
1. Не для всех приложений эта архитектура подходит. Так, если обработка события
требует длительных вычислений или ее невозможно реализовать без использования
блокирующихся системных вызовов, это может затормозить обработку других событий.
2. Разработка событийно-ориентированного приложения требует высокой квалификации
разработчиков. На практике это может привести, и обычно приводит, к высокой
стоимости разработки.
3. Код, рассчитанный на другую архитектуру (например, использующий блокирующиеся
системные вызовы), невозможно переиспользовать в событийно-ориентированном
приложении. Напротив, многие из приемов кодирования, необходимых в событийно-
ориентированных приложениях, бесполезны и даже вредны в других архитектурах.
4. Низкая надежность. Фатальная ошибка при обработке любого события приводит
к аварийному завершению всего процесса.
5. Низкая безопасность. Поскольку все события обрабатываются одним процессом, то все
обработчики работают от имени одного и того же пользователя. Невозможно
реализовать принцип минимально необходимых привилегий.
Гибридные архитектуры
Гибридные архитектуры отличаются большим разнообразием. Они позволяют сочетать
преимущества, характерные для различных типов простых архитектур. Так, разработчик
интерактивного приложения может реализовать пользовательский интерфейс в рамках
событийно-ориентированной архитектуры, а для сложных вычислений (например,
для переразбиения текста на страницы) запускать фоновые нити.
Однако важно понимать, что очень часто гибридные архитектуры сочетают не только
преимущества, но и недостатки используемых базовых архитектур. Поэтому создание
приложения с гибридной архитектурой предъявляет высокие требования к квалификации
архитектора приложения и большинства разработчиков.
В конце лекции 9 мы рассматривали архитектуру «рабочих нитей» (worker threads),
сочетающую многопоточность с событийной ориентацией. Ряд приложений, в том числе
Apache 2.0, используют такую архитектуру.
Архитектуры вычислительных программ
Ранее мы рассматривали преимущества и недостатки многопроцессных и многопоточных
архитектур с точки зрения приложений, занимающихся обработкой внешних событий –
серверных и интерактивных приложений. Однако большой интерес представляют также
вычислительные приложения, предназначенные для научных и инженерных расчетов.
Такие приложения не занимаются обработкой внешних событий и в ряде отношений работают
в тепличных условиях (по сравнению, скажем, с серверными приложениями, подключенными к
Интернет). Так, разработчика вычислительной программы, как правило, не интересуют
вопросы безопасности: его задача работает с минимальным уровнем привилегий на
выделенном компьютереи не взаимодействует с внешним миром, поэтому заниматься ее
взломом обычно и неинтересно, и практически невозможно.
Однако и для вычислительных задач не существует единой оптимальной архитектуры,
приемлемой для всех случаев.
Решающим вопросом при выборе архитектуры является вопрос о том, насколько хорошо
распараллеливается алгоритм, какой объем разделяемых данных должны иметь процессы или
нити и как часто им нужно синхронизовать эти данные.
Важным параметром задачи является также предсказуемость времени исполнения ее частей.
Действительно, если время исполнения нитей алгоритма строго одинаково, мы легко можем
распределить эти нити между процессорами или между машинами вычислительного кластера.
Если же время исполнения нитей различается и при этом труднопредсказуемо, у нас может
возникнуть желание переносить нити или задачи между процессорами во время исполнения.
Такая ситуация возникает при расчете трехмерных изображений методом трассировки лучей с
реалистичным моделированием рассеивания света. Перенос процессов сопряжен с большими
сложностями и хорошие алгоритмы балансировки загрузки не известны (даже при известных
временах исполнения процессов задача их распределения по процессорам является NP-полной, так называемой «задачей о рюкзаке»), поэтому разработчики параллельных задач все-таки
стараются обеспечить равномерное распределение расчетов между процессами или нитями. В
случаях, когда это не удается, обычно создается большое количество процессов – значительно
большее, чем количество процессоров – и затем эти процессы распределяются между
процессорами случайным образом.
Примеры очень хорошо распараллеливающихся задач с малым объемом разделяемых данных –
взлом шифра методом «грубой силы» (например, перебором пространства ключей) или
вычисление интеграла методом Монте-Карло. Примеры вовсе не распараллеливаемых задач –
вычисление ряда, определяемого индуктивной формулой a(n)=f(a(n-1)) или поиск минимума
многомерной функции методом градиентного спуска.
Два основных подхода к реализации параллельных вычислительных программ – это
параллельные программы с разделяемой памятью и программы, обменивающиеся
сообщениями.
Программы с разделяемой памятью удобны, когда нити алгоритма должны часто обмениваться
большими объемами данных и/или осуществлять произвольный доступ к разделяемым данным
большого объема. Программы, обменивающиеся сообщениями, удобны, когда объем
разделяемых данных невелик, а эти данные изменяются редко и в предсказуемых местах.
Крайний случай программ, обменивающихся сообщениями – это уже упоминавшийся взлом
шифра, когда каждая программа при запуске получает свой участок работы (дешифруемое
сообщение, критерий успешности расшифровки и диапазон пространства ключей), выполняет
свою часть работы независимо от других и сообщает о результате.
Наиболее распространенная технология параллельных вычислений с разделяемой памятью –
OpenMP. Приложения OpenMP разрабатываются на специальных диалектах языков C и Fortran.
Эти диалекты отличаются от базовых языков наличием специальных директив (в C это #pragma
omp), описывающих, какие участки кода следует исполнять параллельно и какие переменные
должны разделяться между нитями. Кроме директив компилятора OpenMP предоставляет
также API для взаимодействия нитей. Некоторые компиляторы, например Sun Studio 11, могут
автоматически распараллеливать программы, написанные на обычном C и Fortran.
OpenMP использует fork-join модель многопоточности, когда программа в начале блока
разветвляется на несколько нитей, а в конце блока собирает результаты исполнения этих нитей.
Таким образом, параллелизм программы имеет блочную структуру, аналогичную структуре
кода в C и Java. Разумеется, это резко сужает количество возможных программ, но в то же
время это значительно упрощает разработку и отладку. Поэтому считается, что OpenMP
предоставляет более высокоуровневую модель многопоточности, чем POSIX Threads.
OpenMP позволяет управлять количеством нитей программы во время запуска при помощи
переменной среды OMP_NUM_THREADS. Сама программа также может управлять
количеством нитей через специальный API. Как правило, рекомендуется, чтобы количество
нитей программы на машине с N процессорами было равно N или N-1. По умолчанию
программа OpenMP запускается с количеством нитей, которое равно количеству доступных
процессоров. Если несколько пользователей запускают свои задачи на одной машине, им
следует договориться об используемом количестве процессоров. Solaris предоставляет
средства для принудительного управления количеством процессоров, доступных пользователю,
такие, как зоны, контейнеры и проекты.
Программы OpenMP исполняются как несколько потоков в рамках одного процесса. Это
практически исключает возможность исполнения таких программ – во всяком случае, в чистом
виде - на многомашинных комплексах. Тем не менее, существуют вычислительные комплексы_
с большим количеством процессоров, предоставляющие разделяемую память, пригодную для
исполнения многопоточных программ – так называемые NUMA-системы (Non-Uniform
Memory Access, неоднородный доступ к памяти). Такие системы состоят из процессорных
модулей, которые обычно имеют несколько процессоров и локальную память. Модули
соединены между собой высокоскоростной коммутируемой или маршрутизуемой магистралью,
которая обеспечивает доступ к ОЗУ других модулей. Разумеется, доступ к памяти другого
модуля происходит медленнее, чем к локальному ОЗУ, но все-таки быстрее, чем копирование
содержимого ОЗУ по сети. Многие реализации NUMA - CC-NUMA (Cache Coherent NUMA,
NUMA с когерентным кэшем), COMA (Cache Only Memory Architecture) в том или ином виде
реализуют локальное кэширование при межмодульном доступе к памяти.
NUMA системы с умеренным количеством процессоров (16, 32 или 64) применяются не только
для вычислений, но и в качестве серверов баз данных и серверов приложений и производятся
серийно. Именно такую архитектуру имеют старшие модели серверов Sun Fire.
Для вычислительных задач иногда применяются NUMA-системы с сотнями и тысячами
процессоров. Межмодульная магистраль в таких системах обычно представляет собой
маршрутизуемую сеть сложной (чаще всего гиперкубической) топологии. Такие машины
делаются на заказ или небольшими сериями и, как правило, допускают установку
дополнительных процессорных модулей. Именно такую архитектуру имел компьютер IBM
DeepBlue, который в 1997 году выиграл матч у чемпиона мира по шахматам Г. Каспарова.
Наиболее распространенная технология разработки параллельных вычислительных программ с
обменом сообщениями так и называется – MPI (Message Passing Interface, интерфейс передачи
сообщений). MPI представляет собой библиотеку, реализующую высокоуровневый обмен
типизованными сообщениями между процессами. Передача сообщений может осуществляться
как по сети, так и через локальные средства IPC. Также предоставляется имитация семафоров,
барьеров и разделяемой памяти при помощи сообщений. MPI обеспечивает запуск
многопроцессных вычислительных приложений как на одном компьютере (даже
однопроцессорном – это может быть полезно при отладке), так и на многомашинных
вычислительных кластерах. Для большинства задач необходимо, чтобы эти машины были
соединены высокопроизводительными сетевыми интерфейсами.
В последние годы возник интерес к гибридным приложениям MPI/OpenMP. Действительно, в
современных вычислительных кластерах часто используются многопроцессорные машины.
Кроме того, приложения MPI часто проводят довольно много времени в ожидании обмена
данными; в это время машина могла бы заниматься исполнением другой части работы. На
некоторых задачах использование гибридной вычислительной модели позволяет достичь
улучшения на десятки процентов и даже в разы по сравнению с чистыми MPI и OpenMP.
Для задач, которые нуждаются в редком обмене сообщениями небольшого объема, интересны
вычислительные сети типа GRID. Такие сети представляют собой обычные персональные
компьютеры, соединенные обычной офисной локальной сетью или даже через Интернет. Эти
сети часто допускают произвольное подключение и отключение машин. В этом случае, GRID-
система позволяет использовать персональные компьютеры во время простоя. Например, в
научно-исследовательском учреждении во время рабочего дня компьютеры используются
сотрудниками, а ночью или даже во время обеденного перерыва они подключаются к GRID и
занимаются вычислениями. Разумеется, это возможно только если алгоритм допускает
разбиение на совершенно автономные подзадачи, не нуждающиеся во взаимодействии друг с
другом. Примерами таких задач являются уже упоминавшиеся взлом шифров методом грубой
силы и вычисление интегралов методом Монте-Карло, а также поиск внеземных цивилизаций__
23. Архітектура PowerPC. Последняя из ныне здравствующих процессорных RISC-архитектур - это, конечно же, знаменитая PowerPC, детище альянса Apple, IBM и Motorola (AIM). Сегодня на PowerPC есть четкие спецификации, следуя которым любой желающий может разработать совместимый с ним процессор. Ничего особо интересного в нем нет - это самый что ни на есть классический RISC-процессор без специальных "примочек". Существуют 32- и 64-разрядные версии PowerPC (причем 64-разрядные совместимы с 32-разрядным кодом), а равно и ряд стандартизованных расширений (типа эппловского набора инструкций AltiVec). В то время как MIPS и ARM "специализировались" на тех или иных применениях, PowerPC, подобно x86, позиционировалась в основном для обычных персоналок и серверов. Вплоть до 2001 года x86 и PowerPC развивались более или менее синхронно, однако из-за технологических проблем и неспособности угнаться за процессорами AMD и Intel в "гонке мегагерц" PPC шаг за шагом сдавала позиции. А исчерпав "запас прочности" и застряв на частотах 1,0-1,4 ГГц, она стала стремительно проигрывать архитектуре x86, по-прежнему сохранявшей высокие темпы развития из-за ожесточенной схватки Intel и AMD. Поскольку "отступать" PowerPC было в общем-то некуда (нишу интегрированных процессоров оккупировали ARM и MIPS), то многие посчитали ее верным кандидатом на вымирание. Даже Apple недавно "отреклась" от своей архитектуры, переметнувшись в стан приверженцев x86. Только крайне дорогие серверные процессоры POWER, выпускавшиеся на пределе технологических возможностей Голубого гиганта (Power4, в частности, стали первыми в мире двухъядерниками), еще довольно уверенно чувствуют себя в линейке продуктов IBM. Однако ситуация, похоже, начала меняться: именно архитектура PowerPC положена в основу будущих многоядерных процессоров всех игровых приставок шестого поколения (от Sony, Microsoft и Nintendo), поскольку ни MIPS, ни тем более ARM на эту роль не годятся; процессоры Intel в их текущем варианте плохо подходят для создания игровых приставок нового поколения; о процессорах AMD и говорить не приходится - компания просто не в состоянии обеспечить достаточный объем их производства. Вот и остается единственным кандидатом на роль нового "суперпроцессора" только всем доступная, технологически более простая, нежели x86, и достаточно производительная архитектура PowerPC.