

59. Представлення чисел в форматі з плаваючою точкою (на прикладі пк).
Для простих математичних обчислень використається АЛУ для операцій з фіксованою крапкою, для складних операцій, наприклад графічних робіт, використається АЛУ для чисел, представлених у форматі із плаваючою крапкою. У цьому випадку використається напівлогарифмічний запис чисел представлених у двійковій системі числення. Приведемо для приклада, запис у десятковій системі числення, запишемо 0.000500 *103. Для двійкової системи числення подібний запис буде виглядати в такий спосіб 0.1100 .* 100000100. У такому поданні чисел у комірці пам"яті зберігається мантиса числа (0.1100 .) і порядок (0000100). Для мантиси, порядку й знака числа відведені певні розряди.
У процесорах Pentіum використається два АЛУ з фіксованою крапкою й два АЛУ із плаваючої, два 8-килобайтных кэш для команд і даних. Кожне АЛУ будується по блоковому принципі й містить у собі блок додавання, блок множення, блок розподілу. Операції із плаваючою крапкою виконуються процесором за один такт. Цікавим нововведенням процесорів Pentіum є невелика кэш - пам"ять (буфер міток переходів), що дозволяє пророкувати переходи у виконуваних програмах і заздалегідь підготовляти їх. Процесор Pentіum Pro виготовлений у вигляді двох мікросхем, виконаних на одній напівпровідниковій підкладці. Одна мікросхема - це властиво процесор, друга - кэш пам"ять другого рівня на 256 Кбайт - це швидка пам"ять, винесена за межі процесора. Швидкодія процесора порядку 300 MІPS, число транзисторів - 5.5 мільйонів.
60. Кодування ascii (American Standart Code for Information Interchange) та стандарт Unicode. Кодування українського тексту (Windows-1251, koi8 та ін.,.
В данной таблице для преобразования прописных букв в строчные достаточно к коду букву прибавить 32 и наоборот для преобразования строчных в прописные. В последующем данная таблица ASCII была принята как стандарт ведущими международными организациями по стандартизации:
ISO/IEC 646:1991 (ISO – http://www.iso.org/ – International Organization for Standardization и IEC – http://www.iec.ch/ – International Electrotechnical Commission – ведущие международные организации по стандартизации, в области электротехники – совместные стандарты),
ITU-T Recommendation T.50 (09/92) (The International Telecommunication Union – http://www.itu.int/),
ECMA-6 (European Computer Manufacturers Association).
Однако для нашей страны и многих других стран необходимо было добавить в кодовую таблицу символы национальных алфавитов. Для этого было предложено использовать 8-битную кодовую таблицу, которая могла содержать дополнительно ещё 128 символов (с 128 по 255).
В дальнейшем был принят стандарт на 8-битную таблицу ASCII – ISO/IEC 8859, в которой первые 128 символов оставались те же, что и в 7-битной таблице, а символы с 128 по 255 отводились для неанглийских символов.
В январе 1991 года возник консорциум UNICODE (Unicode Consortium), целью которого является продвижение, развитие и реализация стандарта Unicode как международной системы кодирования для обмена информацией, а также поддержание качества этого стандарта в будущих версиях. Стандарт UNICODE 4.0 представляет собой новую систему кодирования символов, выводимых на экран монитора или на принтер, позволяющую закодировать 1 114 112 символов (в стандарте из принято называть code points). Большинство символов, используемых в основных языках мира занимают 65 536 code points, образуя Basic Multilingual Plane (BMP) (Основной Многоязычный Уровень - мой перевод). Оставшиеся (более миллиона) code points вполне достаточно для кодирования всех известных символов, включая малораспространенные языки и исторические знаки. Стандарт UNICODE поддерживается тремя формами, 32-битной (UTF-32), 16-битной (UTF-16) и 8-битной (UTF-8). Восьмибитная форма UTF-8 была разработана для удобной совместимости с ASCII-ориентироваными системами кодирования. Стандарт UNICODE совместим с Международным стандартом International Standard ISO/IEC 10646.
Наиболее просто устроена форма UTF-32. В ней каждый символ закодирован при помощи 32-битного блока. Благодаря этому каждый символ UTF-32 обладает однозначным соответствием между декодированным символом и блоком кода. Это форма имеет фиксированную длину знакоместа. Она покрывает все кодовое пространство UNICODE - 0...10FFFF16. Это гарантирует полную совместимость с UTF-16 и UTF-8. Форма UTF-32 является наиболее предпочитаемой для большинства UNIX платформ.
Стандарт UNICODE содержит 96 382 символа, взятых их мировых шрифтов. Этих символов более чем достатонно для общения на всех известных языках мира, а также для написания классических (исторических ) шрифтов многих языков. UNICODE всключает в себя шрифты европейских алфавитов, средне-азиатское письмо, направленное справа на лево, шрифты Азии, и многие другие. Подмножество символов (code points) HUN включает 70 207 идеографических символов определяемых по национальным и промышленным стандартам Китая, Японии, Кореи, Тайвани, Вьетнама и Сингапура. Более того, UNICODE содержит знаки пунктуации, математические символы, технические символы, герметрические фотмы и графические метки (dingbats), фонетические знаки.
6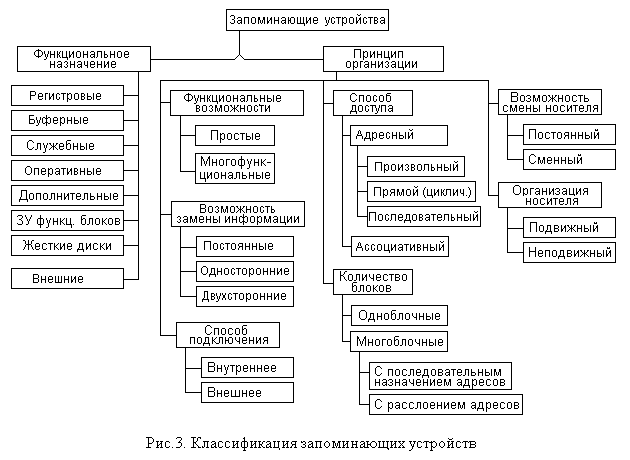 1.
Принципи кодування нечислових видів
інформації: текстів, чорно-білої та
кольорової графіки, звукової
інформації.7.5.1.ЭВМ
первых двух поколений могли обрабатывать
только числовую информацию, полностью
оправдывая свое название вычислительных
машин. Лишь переход к третьему поколению
принес изменения: к этому времени уже
назрела настоятельная необходимость
использования текстов.
Следуя ходу исторического развития, мы
тоже начнем наше рассмотрение с этого
вида информации. С точки зрения ЭВМ
текст состоит из отдельных символов. К
числу символов принадлежат не только
буквы (заглавные или строчные, латинские
или русские), но и цифры, знаки препинания,
спецсимволы типа "=",
"(",
"&"
и т.п. и даже (обратите особое внимание!)
пробелы между словами. Да, не удивляйтесь:
пустое место в тексте тоже должно иметь
свое обозначение. Каждый символ хранится
в виде двоичного кода, который является
номером символа. Можно сказать, что
компьютер имеет собственный алфавит,
где весь набор символов строго упорядочен.
Количество символов в алфавите также
тесно связано с двоичным представлением
и у всех ЭВМ равняется 256. Иными словами,
каждый символ всегда кодируется 8 битами,
т.е. занимает ровно один байт. При этом,
хранится не начертание буквы, а ее номер.
Именно по этому номеру воспроизводится
вид символа на экране дисплея или на
бумаге. Поскольку алфавиты в различных
типах ЭВМ не полностью совпадают, при
переносе с одной модели на другую может
произойти превращение разумного текста
в "абракадабру". Такой эффект иногда
получается даже на одной машине в
различных программных средах: например,
русский текст, набранный в MS DOS, нельзя
без специального преобразования
прочитать в Windows. Задача перекодировки
текста из одной кодовой таблицы в другую
довольно проста и при наличии программ
машина сама великолепно с ней справляется.
Наиболее стабильное положение в алфавитах
всех ЭВМ занимают латинские буквы, цифры
и некоторые специальные знаки. Это
связано с существованием международного
стандарта ASCII.
Украинские буквы не стандартизированы
и могут иметь различную кодировку. Ниже
в качестве примера приводится таблица
стандартной части алфавита ЭВМ - символы
с шестнадцатиричными кодами с 20 до 7F.
Согласно стандарта
ASCII, каждый
символ текста имеет свой числовой код,
но не каждому коду соответствует
отображаемый на экране символ. Речь
идет о существовании так называемых
‘управляющих
кодов’,
величина которых меньше шестнадцатиричного
числа 20 (т.е. 32 в десятичной системе
счисления). При получении этих кодов
внешние устройства не изображают
какого-либо символа, а выполняют те или
иные управляющие действия. Так, код 07
вызывает подачу стандартного звукового
сигнала, а код 0C
- очистку экрана. Особую роль играют
коды 0A
(перевод
строки,
обозначаемый часто LF) и 0D
(возврат
каретки
- CR). Первый вызывает перемещение в
следующую строку без изменения позиции,
а второй - на начало текущей строки.
Таким образом, для перехода на начало
новой строки требуются оба кода и в
любом тексте эта "неразлучная пара"
кодов хранится после каждой строки.
Обратим
внимание на то,
что названия возврат каретки и перевод
строки имеют историческое происхождение
и связаны с устройством пишущей машинки.
Основные
принципы хранения в памяти ЭВМ графической
информации.
В отличии от только что рассмотренного
текстового режима дисплея, когда
минимальной единицей изображения
является символ, при отображении графики
картинка строится из отдельных элементов
– ‘пикселов’
(от английских слов PICture ELement, означающих
"элемент картинки"). Очень часто
пиксел совпадает с точкой дисплея, но
это совсем необязательно: например, в
некоторых видеорежимах 1 пиксел может
состоять из 2 или 4 точек экрана.Каждый
пиксел характеризуется цветом. Как и
вся остальная информация в ЭВМ, цвет
кодируется числом. В зависимости от
количества допустимых цветов, число
двоичных разрядов на один пиксел будет
различным. Так, для черно-белой картинки
закодировать цвет точки можно одним
битом: 0 - черный, 1 - белый. Для случая 16
цветов требуется уже по 4 разряда на
каждую точку, а для 256 цветов - 8, т.е. 1
байт. Для того, чтобы наглядно представить
себе, как хранится в памяти ЭВМ простейшее
изображение, рассмотрим для примера
белый квадратик на черном фоне размером
4х4. В черно-белом режиме это будет
выглядеть наиболее компактно (сначала
для наглядности приведен двоичный, а
затем шестнадцатиричный вид). В режиме
16-цветной графики это же самое изображение
потребует памяти в 4 раза больше: Наконец,
при 256 цветах на каждую точку требуется
уже по байту и наш квадратик разрастется
еще вдвое: При этом, белый цвет, как самый
яркий, обычно имеет максимально возможный
номер. Поэтому для черно-белого режима
он равен 1, для 16-цветного - 15, а для 256
цветов - 255.Кодирование
промежуточные цвета.
Методы кодирования цвета даже для одной
и той же ЭВМ могут довольно существенно
различаться. Причем не только в зависимости
от конструкции дисплея, но и от графического
режима, в котором тот в данный момент
работает! Более того, соответствие между
номерами цветов и их представлением на
экране можно переопределять по усмотрению
пользователя (это называется изменением
палитры).
Поэтому ограничимся в качестве примера
сандартным 16-цветным набором для наиболее
распространенного компьютера IBM PC: Таким
образом, графическая информация, также
как числовая и текстовая, в конечном
счете заносится в память в виде двоичных
чисел.Кодирование
звуковой
информации
(ЭВМ третьего поколения еще не умела
обрабатывать этот вид информации).
Принцип преобразования звукового
сигнала в цифровую форму и его последующее
воспроизведение показаны на рис.2.Запись
звука происходит следующим образом.
Выбирается система равноотстоящих друг
от друга уровней напряжения сигнала и
каждому из них ставится в соответствие
определенный номер. Затем через равные
очень небольшие промежутки времени
измеряется уровень входного сигнала и
определяется, к какому из стандартных
уровней он ближе всего подходит; номер
найденного уровня и записывается в
память в качестве громкости звука в
данный момент. Для высококачественной
стереофонической записи используется
частота 44000 Гц, т.е. измерение происходит
десятки тысяч раз в секунду. При
воспроизведении данные считываются, и
с такой же самой, как и при записи, высокой
частотой компьютер изменяет интенсивность
звука в зависимости от прочитанных
номеров уровней. Интересно, что регулировка
громкости при таком методе воспроизведения
в самом прямом смысле осуществляется
с помощью умножения: например, чтобы
увеличить громкость вдвое, перед
воспроизведением номер уровня необходимо
также удвоить. Таким образом, рассмотрев
принципы хранения в ЭВМ различных видов
информации, можно сделать важный вывод
о том, что все они так или иначе
преобразуются в
числовую форму
и кодируются
набором нулей и единиц.
Благодаря
такой универсальности представления
данных, если из памяти наудачу извлечь
содержимое какой-нибудь ячейки, то
принципиально невозможно определить,
какая именно информация там закодирована:
текст, число или картинка.
1.
Принципи кодування нечислових видів
інформації: текстів, чорно-білої та
кольорової графіки, звукової
інформації.7.5.1.ЭВМ
первых двух поколений могли обрабатывать
только числовую информацию, полностью
оправдывая свое название вычислительных
машин. Лишь переход к третьему поколению
принес изменения: к этому времени уже
назрела настоятельная необходимость
использования текстов.
Следуя ходу исторического развития, мы
тоже начнем наше рассмотрение с этого
вида информации. С точки зрения ЭВМ
текст состоит из отдельных символов. К
числу символов принадлежат не только
буквы (заглавные или строчные, латинские
или русские), но и цифры, знаки препинания,
спецсимволы типа "=",
"(",
"&"
и т.п. и даже (обратите особое внимание!)
пробелы между словами. Да, не удивляйтесь:
пустое место в тексте тоже должно иметь
свое обозначение. Каждый символ хранится
в виде двоичного кода, который является
номером символа. Можно сказать, что
компьютер имеет собственный алфавит,
где весь набор символов строго упорядочен.
Количество символов в алфавите также
тесно связано с двоичным представлением
и у всех ЭВМ равняется 256. Иными словами,
каждый символ всегда кодируется 8 битами,
т.е. занимает ровно один байт. При этом,
хранится не начертание буквы, а ее номер.
Именно по этому номеру воспроизводится
вид символа на экране дисплея или на
бумаге. Поскольку алфавиты в различных
типах ЭВМ не полностью совпадают, при
переносе с одной модели на другую может
произойти превращение разумного текста
в "абракадабру". Такой эффект иногда
получается даже на одной машине в
различных программных средах: например,
русский текст, набранный в MS DOS, нельзя
без специального преобразования
прочитать в Windows. Задача перекодировки
текста из одной кодовой таблицы в другую
довольно проста и при наличии программ
машина сама великолепно с ней справляется.
Наиболее стабильное положение в алфавитах
всех ЭВМ занимают латинские буквы, цифры
и некоторые специальные знаки. Это
связано с существованием международного
стандарта ASCII.
Украинские буквы не стандартизированы
и могут иметь различную кодировку. Ниже
в качестве примера приводится таблица
стандартной части алфавита ЭВМ - символы
с шестнадцатиричными кодами с 20 до 7F.
Согласно стандарта
ASCII, каждый
символ текста имеет свой числовой код,
но не каждому коду соответствует
отображаемый на экране символ. Речь
идет о существовании так называемых
‘управляющих
кодов’,
величина которых меньше шестнадцатиричного
числа 20 (т.е. 32 в десятичной системе
счисления). При получении этих кодов
внешние устройства не изображают
какого-либо символа, а выполняют те или
иные управляющие действия. Так, код 07
вызывает подачу стандартного звукового
сигнала, а код 0C
- очистку экрана. Особую роль играют
коды 0A
(перевод
строки,
обозначаемый часто LF) и 0D
(возврат
каретки
- CR). Первый вызывает перемещение в
следующую строку без изменения позиции,
а второй - на начало текущей строки.
Таким образом, для перехода на начало
новой строки требуются оба кода и в
любом тексте эта "неразлучная пара"
кодов хранится после каждой строки.
Обратим
внимание на то,
что названия возврат каретки и перевод
строки имеют историческое происхождение
и связаны с устройством пишущей машинки.
Основные
принципы хранения в памяти ЭВМ графической
информации.
В отличии от только что рассмотренного
текстового режима дисплея, когда
минимальной единицей изображения
является символ, при отображении графики
картинка строится из отдельных элементов
– ‘пикселов’
(от английских слов PICture ELement, означающих
"элемент картинки"). Очень часто
пиксел совпадает с точкой дисплея, но
это совсем необязательно: например, в
некоторых видеорежимах 1 пиксел может
состоять из 2 или 4 точек экрана.Каждый
пиксел характеризуется цветом. Как и
вся остальная информация в ЭВМ, цвет
кодируется числом. В зависимости от
количества допустимых цветов, число
двоичных разрядов на один пиксел будет
различным. Так, для черно-белой картинки
закодировать цвет точки можно одним
битом: 0 - черный, 1 - белый. Для случая 16
цветов требуется уже по 4 разряда на
каждую точку, а для 256 цветов - 8, т.е. 1
байт. Для того, чтобы наглядно представить
себе, как хранится в памяти ЭВМ простейшее
изображение, рассмотрим для примера
белый квадратик на черном фоне размером
4х4. В черно-белом режиме это будет
выглядеть наиболее компактно (сначала
для наглядности приведен двоичный, а
затем шестнадцатиричный вид). В режиме
16-цветной графики это же самое изображение
потребует памяти в 4 раза больше: Наконец,
при 256 цветах на каждую точку требуется
уже по байту и наш квадратик разрастется
еще вдвое: При этом, белый цвет, как самый
яркий, обычно имеет максимально возможный
номер. Поэтому для черно-белого режима
он равен 1, для 16-цветного - 15, а для 256
цветов - 255.Кодирование
промежуточные цвета.
Методы кодирования цвета даже для одной
и той же ЭВМ могут довольно существенно
различаться. Причем не только в зависимости
от конструкции дисплея, но и от графического
режима, в котором тот в данный момент
работает! Более того, соответствие между
номерами цветов и их представлением на
экране можно переопределять по усмотрению
пользователя (это называется изменением
палитры).
Поэтому ограничимся в качестве примера
сандартным 16-цветным набором для наиболее
распространенного компьютера IBM PC: Таким
образом, графическая информация, также
как числовая и текстовая, в конечном
счете заносится в память в виде двоичных
чисел.Кодирование
звуковой
информации
(ЭВМ третьего поколения еще не умела
обрабатывать этот вид информации).
Принцип преобразования звукового
сигнала в цифровую форму и его последующее
воспроизведение показаны на рис.2.Запись
звука происходит следующим образом.
Выбирается система равноотстоящих друг
от друга уровней напряжения сигнала и
каждому из них ставится в соответствие
определенный номер. Затем через равные
очень небольшие промежутки времени
измеряется уровень входного сигнала и
определяется, к какому из стандартных
уровней он ближе всего подходит; номер
найденного уровня и записывается в
память в качестве громкости звука в
данный момент. Для высококачественной
стереофонической записи используется
частота 44000 Гц, т.е. измерение происходит
десятки тысяч раз в секунду. При
воспроизведении данные считываются, и
с такой же самой, как и при записи, высокой
частотой компьютер изменяет интенсивность
звука в зависимости от прочитанных
номеров уровней. Интересно, что регулировка
громкости при таком методе воспроизведения
в самом прямом смысле осуществляется
с помощью умножения: например, чтобы
увеличить громкость вдвое, перед
воспроизведением номер уровня необходимо
также удвоить. Таким образом, рассмотрев
принципы хранения в ЭВМ различных видов
информации, можно сделать важный вывод
о том, что все они так или иначе
преобразуются в
числовую форму
и кодируются
набором нулей и единиц.
Благодаря
такой универсальности представления
данных, если из памяти наудачу извлечь
содержимое какой-нибудь ячейки, то
принципиально невозможно определить,
какая именно информация там закодирована:
текст, число или картинка.
62. Общие принципы организации памяти ЭВМ Системы памяти современных ЭВМ представляют собой совокупность аппаратных средств, предназначенных для хранения используемой в ЭВМ информации. К этой информации относятся обрабатываемые данные, прикладные программы, системное программное обеспечение и служебная информация различного назначения. К системе памяти можно отнести и программные средства, организующие управление ее работой в целом, а также драйверы различных видов запоминающих устройств.Память представляет собой одну из важнейших подсистем ЭВМ, во многом определяющую их производительность. Тем не менее в течение всей истории развития вычислительных машин она традиционно считается их "узким местом".Ключевым принципом построения памяти ЭВМ является ее иерархическая организация (принцип, сформулированный еще Джоном фон Нейманом), которая предполагает использование в системе памяти компьютера запоминающих устройств (ЗУ) с различными характеристиками. Причем с развитием технологий, появлением новых видов ЗУ и совершенствованием структурной организации ЭВМ количество уровней в иерархии памяти ЭВМ не только не уменьшается, но даже увеличивается. Например, сверхоперативные ЗУ больших ЭВМ 50-60-х годов заменяет двухуровневая кэш-память персональных ЭВМ 90-х годов. В данной главе проводится классификация ЗУ с точки зрения особенностей их организации и использования. Затем рассматриваются типовые структуры систем памяти ЭВМ, а также основные параметры и критерии оценки запоминающих устройств и систем.
8.1.1. Основные характеристики запоминающих устройств. Запоминающие устройства (ЗУ) характеризуются рядом параметров, определяющих возможные области применения различных типов таких устройств. К основным параметрам, по которым производится наиболее общая оценка ЗУ, относятся их информационная емкость (E), время обращения (T) и стоимость (C).Под информационной емкостью ЗУ понимают количество информации, измеряемое в байтах, килобайтах, мегабайтах или гигабайтах, которое может храниться в запоминающем устройстве.Как известно, приставки кило-, мега- и гига- допускают неоднозначную трактовку в связи с различием их понимания в общенаучном и специфическом при использовании двоичной системы счисления смыслах. Так, в общем смысле приставка "кило" соответствует 103, "мега" – 106, а "гига" – 109 (на подходе "тера", "пента" и "гексо") . В то же время, близкие по звучанию и смыслу двоичные аналоги этих величин: К-, М- и Г- обозначают 210 (1024), 220 (1048576) и 230 (1073741824), что только приблизительно соответствует перечисленным выше степеням 10. Поэтому при указании емкости одного и того же устройства памяти, например жесткого диска, в Гбайтах и миллиардах байт, могут наблюдаться определенные различия.Обычно информационная емкость учитывает только полезный объем хранимой информации, который не включает объем памяти, расходуемый на служебную информацию, контрольные разряды или байты, резервные области (например, интервал между концом дорожки диска и ее началом), дорожки синхросигналов и пр.Время обращения к ЗУ различных типов определяется по-разному. В качестве примера можно рассмотреть оперативные ЗУ и жесткие диски.Оперативные ЗУ обычно реализуются как ЗУ с произвольным доступом (см. Классификация ЗУ по функциональному назначению ). Это означает, что доступ к данным, физически организованным в виде двумерного массива (матрицы элементов памяти), производится с помощью схем дешифрации, выбирающих нужные строку и столбец массива по их номерам (адресам), как показано на рис.1. Поэтому время Tобр обращения к ним определяется, в случае отсутствия дополнительных этапов (таких, например, как передача адреса за два такта), временем срабатывания схем дешифрации адреса и собственно временами записи или считывания данных.Емко сти оперативных ЗУ этого же периода составляли для небольших ЭВМ порядка 256 Мб – 2 Гб.
 Следующим
уровнем иерархии памяти является
оперативная
память.
Оперативное ЗУ (ОЗУ) является основным
запоминающим устройством ЭВМ, в котором
хранятся выполняемые в настоящий момент
процессором программы и обрабатываемые
данные, резидентные программы, модули
операционной системы и т.п. Название
оперативной памяти также несколько
изменялось во времени. В некоторых
семействах ЭВМ ее называли основной
памятью, основной оперативной памятью
и пр. В англоязычной литературе также
используется термин RAM
(random
access memory),
означающий память с произвольным
доступом.Эта память используется в
качестве основного запоминающего
устройства ЭВМ для хранения программ,
выполняемых или готовых к выполнению
в текущий момент времени, и относящихся
к ним данных. В оперативной памяти
располагаются и компоненты операционной
системы, необходимые для ее нормальной
работы. Информация, находящаяся в ОЗУ,
непосредственно доступна командам
процессора, при условии соблюдения
требований защиты.Оперативная память
реализуется на полупроводниках
(интегральных схемах), стандартные
объемы ее составляют (в начале 2000-х
годов) сотни мегабайт – единицы гигабайт,
а времена обращения – единицы÷десятки
наносекунд.
Следующим
уровнем иерархии памяти является
оперативная
память.
Оперативное ЗУ (ОЗУ) является основным
запоминающим устройством ЭВМ, в котором
хранятся выполняемые в настоящий момент
процессором программы и обрабатываемые
данные, резидентные программы, модули
операционной системы и т.п. Название
оперативной памяти также несколько
изменялось во времени. В некоторых
семействах ЭВМ ее называли основной
памятью, основной оперативной памятью
и пр. В англоязычной литературе также
используется термин RAM
(random
access memory),
означающий память с произвольным
доступом.Эта память используется в
качестве основного запоминающего
устройства ЭВМ для хранения программ,
выполняемых или готовых к выполнению
в текущий момент времени, и относящихся
к ним данных. В оперативной памяти
располагаются и компоненты операционной
системы, необходимые для ее нормальной
работы. Информация, находящаяся в ОЗУ,
непосредственно доступна командам
процессора, при условии соблюдения
требований защиты.Оперативная память
реализуется на полупроводниках
(интегральных схемах), стандартные
объемы ее составляют (в начале 2000-х
годов) сотни мегабайт – единицы гигабайт,
а времена обращения – единицы÷десятки
наносекунд.
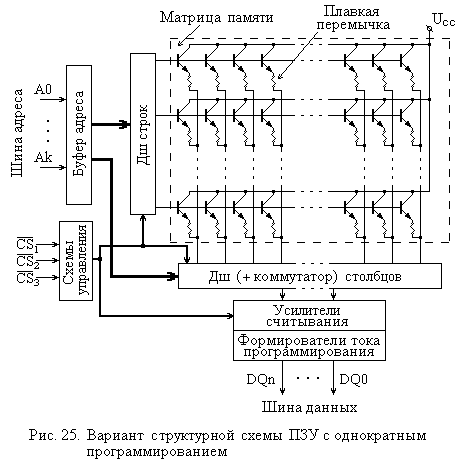
63. Організація дискової та інших видів пам’яті комп’ютерів. (см воп.№37) Постоянная память (ПЗУ - постоянное запоминающее устройство) обычно содержит такую информацию, которая не должна меняться в ходе выполнения микропроцессором различных программ. Постоянная память имеет также название ROM (Read Only Memory), которое указывает на то, что обеспечиваются только режимы считывания и хранения. Постоянная память энергонезависима, т. е. может сохранять информацию и при отключенном питании. Все микросхемы постоянной памяти по способу занесения в них информации делятся на масочные, программируемые изготовителем (ROM), однократно программируемые пользователем (Programmable ROM) и многократно программируемые пользователем (Erasable PROM). Последние, в свою очередь, подразделяются на стираемые электрически и с помощью ультрафиолетового облучения. К элементам EPROM с электрическим стиранием информации относятся, например, микросхемы флэш-памяти (flash). От обычных EPROM они отличаются высокой скоростью доступа и быстрым стиранием записанной информации. Данный тип памяти сегодня широко используется для хранения BIOS и другой постоянной информации.