

3.3. Статистические гипотезы
Как уже видно из изложенного выше материала, при статистическом оценивании (т.е. при приближенном определении случайной величины) для обос-
66
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
нования (состоятельности, несмещенности и эффективности) выбора той или иной оценки неизвестного параметра распределения приходится высказывать предположение, что, например, случайная величина не противоречит нормальному закону распределения. Кроме того, использование всех имеющихся выборочных значений при расчете оценок, так или иначе, предполагает, что среди них нет грубых ошибок (резко выделяющихся значений). С еще большим количеством различных предположений (гипотез) приходится сталкиваться, когда необходимо не только определять случайные величины, но и сравнивать их между собой, и тем более, когда по результатам эксперимента строится функция отклика.
Статистическая гипотеза - любое предположение, касающееся неизвестного распределения случайной величины.
Например, специалиста интересует, удалось ли добиться повышения механической прочности окатышей при использовании новой технологии их обжига. Он может сформулировать следующую гипотезу: "Механическая прочность окатышей увеличилась". Эта гипотеза (нулевая гипотеза) будет подлежать проверке в ходе проведения опытов. Кроме того, можно сформулировать и любую другую (альтернативную) гипотезу, например: "Изменения механической прочности не произошло" или "Механическая прочность окатышей, наоборот, даже уменьшилась".
Процесс принятия решения называется проверкой статистической гипотезы. Поскольку мы выдвигали гипотезу, опираясь только на случайные выборочные значения, наши выводы будут носить вероятностный характер, то есть мы не можем дать точного ответа: да или нет. Можно будет лишь с некоторой долей уверенности (с некоторой вероятностью) утверждать, что данные не противоречат (или противоречат) предположению.
Статистические гипотезы можно разделить на следующие группы.
1. Гипотезы о параметрах распределения. Эти гипотезы представляют собой предположение о значении некоторых параметров распределения генеральной совокупности. Пусть, например, высказывается гипотеза о том, что параметры (математическое ожидание, дисперсии) в двух выборках равны между собой. Обычно гипотезы о параметрах
67
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
распределения можно выдвигать, располагая достаточно большой информацией о генеральной совокупности или имея весомые основания считать известным ее закон распределения.
2. Гипотезы о виде распределения. Это более общие гипотезы, они выдвигаются в условиях недостаточной информации о генеральной совокупности. По выборке выдвигается гипотеза о том, соответствуют ли данные, например, нормальному закону распределения. Заметим, что проверка гипотезы о нормальности распределения может помочь при дальнейшей обработке выборки: если случайную величину достаточно уверенно можно считать нормально распределенной, то к ней применимы все теоремы о нормальных величинах, в частности имеется возможность построить доверительные интервалы для параметров.
Нулевая гипотеза Но - гипотеза, подлежащая проверке. Это гипотеза, имеющая наиболее важное значение в проводимом исследовании. Нулевую гипотезу выдвигают и затем проверяют с помощью статистических критериев с целью выявления оснований для ее отклонения и принятия альтернативной гипотезы.
Альтернативная гипотеза Hi - каждая допустимая гипотеза, отличная от нулевой. Обычно в качестве альтернативной гипотезы принимают гипотезу вторую по значимости после основной.
Предположение, которое касается неизвестного параметра распределения, когда вид распределения известен (например, закон Гаусса), называется параметрической гипотезой, а предположение, при котором вид распределения неизвестен, называется непараметрической гипотезой.
Задача исследователя заключается в том, чтобы на основе анализа опытных данных, полученных по выборке, принять ту или иную гипотезу относительно свойств генеральной совокупности, используя при этом какой-либо способ (критерий) проверки высказанного предположения.
Статистический критерий - однозначно определенный способ проверки статистических гипотез.
68
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
Критерии для проверки параметрических гипотез называются параметрическими, а для проверки непараметрических гипотез - соответственно непараметрическими.
Естественно, что прежде чем использовать тот или иной параметрический критерий, экспериментатор должен найти способ убедиться в том, согласуется или нет распределение исследуемой им случайной величины с тем или иным теоретическим (например, нормальным) распределением.
Критерий согласия - статистический критерий для проверки гипотезы о согласии (равенстве) распределения случайной величины исследуемой совокупности с теоретическим распределением или гипотезы о согласии распределений в двух и более совокупностях.
Как и при статистическом оценивании, любой критерий может быть построен только на основе тех результатов наблюдений, которые имеются в рас-поряжении исследователя, т.е. путем вычисления той или иной статистики. А как уже раннее было отмечено, любая статистика как некоторая функция слу-чайной величины (функция от результатов наблюдений) также является слу-чайной величиной.
Таким образом, статистические гипотезы всегда носят вероятностный характер. Это говорит о том, что, основываясь на той или иной статистике и принимая нулевую гипотезу в качестве рабочей (либо отвергая эту гипотезу и в качестве рабочей принимая альтернативную), исследователь может совершить ошибки. Ситуации, возникающие при проверке статистических гипотез, представлены в табл.3.2.
Гипотеза Н0 верна, и она не отвергается, т.е. принятое решение от-ражает истинное положение и принимается верная гипотеза.
Гипотеза Н0 верна, но она отвергается, т.е. в этом случае допущена ошибка первого рода. Ошибка первого рода - ошибка, заключающаяся в том, что отвергают нулевую гипотезу, в то время как в действительности эта гипотеза верна. Вероятность этого события по определению равна уровню значимости а. Уровень значимости а - вероятность ошибки первого рода. Так как уровень значимости задается произвольно, можно
69
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
снизить вероятность ошибки первого рода до сколь угодно низкого уровня.
Гипотеза Н0 неверна, и она отвергается. Опять принятое решение отражает истинное положение и отвергается неверная гипотеза.
Гипотеза Н0 неверна, но она не отвергается. В этом случае допущена ошибка второго рода. Ошибка второго рода - ошибка, заключающаяся в том, что принимают нулевую гипотезу, в то время как в действительности эта гипотеза неверна. Если вероятность ошибки второго рода обозначить как р, то величина 1 - Р носит название мощность критерия. Мощность критерия - вероятность того, что если верна альтернативная гипотеза, то нулевая гипотеза будет отвергнута.
Таблица 3.2 Возможные исходы при проверке статистических гипотез
Фактическая ситуация |
Но - принимается |
Но - отвергается |
Но - верна |
Правильное решение |
Ошибка первого рода (а) |
Н0 - не верна |
Ошибка второго рода (Р) |
Правильное решение |
Значения применяемой для данного критерия статистики, при которых для выбранного уровня значимости отвергается нулевая гипотеза, образуют так называемую критическую область.
Критическая область со - область со следующими свойствами: если значения применяемой статистики принадлежат данной области, то отвергают нулевую гипотезу; в противном случае ее принимают.
Приведенные определения намечают самую простую форму проверки статистических гипотез. Для того чтобы пояснить сущность этого метода, предположим, что выборочная величина 0, представляющая собой несмещенную оценку параметра ©о, имеет плотность распределения f(@). Если гипотеза, состоящая в том, что @=@о, верна, то функция f(@) должна попадать в среднюю область, как показано на рис.3.4. Вероятность того, что параметр 0 не будет превышать нижнего уровня @1-а/2,составит
70
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
®1-а/
Р(®^®^/2)= Jf(@)i® = a/2.
—ос
Вероятность того, что параметр 0 превысит верхний уровень 0а/2, равна
х
Ф>©1-а/2)= Jf(@)d® = a/2.
©а/2
Следовательно, вероятность того, что параметр 0 выйдет за пределы интервала [0i-a/2; 0a/2 ], составляет а. Теперь примем величину а малой, чтобы попадание параметра 0 за пределы интервала [01-а/г; ©a/2 ] было маловероятно. Если после извлечения выборки и определения величины 0 окажется, что она выходит за пределы интервала [0-i-a/2; ©а/2 ] и попадает в критическую область, то в этом случае есть серьезные основания подвергнуть сомнению справедливость проверяемой гипотезы 0 = @0. С другой стороны, если параметр 0 попадает в интервал [0i-a/2; 0«/2 ], то в этом случае нет серьезных оснований подвергать сомнению справедливость проверяемой гипотезы, и гипотезу равенства 0 = 0о можно принять. Как видно из рис.3.4, ошибка первого рода допускается, если гипотеза верна, а параметр 0 попадает в область отклонения гипотезы. Отсюда следует, что вероятность допустить ошибку первого рода равна а, т.е. уровню значимости критерия.
f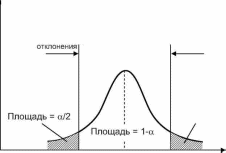 (0)
(0)
Область принятия Область k ^
Площадь = а/2
отклонения
01-а/2 ©0 ©а/2
Pwc. 3.4. Области принятия и отклонения гипотезы при проверке гипотез
71
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
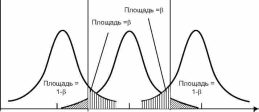
Для того чтобы найти, какова вероятность допустить ошибку второго рода, необходимо задать определенную величину отклонения истинного значения от гипотетического значения параметра, которое требуется определить. Предположим, например, что истинное значение параметра в действительности равно 0o+d или 0o-d, как показано на рис.3.5. Если, согласно гипотезе, 0=0о, а в действительности 0=0О ±d, то вероятность того, что 0 попадает в область принятия гипотезы, т.е. в интервал [0i-a/2; 0a/2], составляет р. Это означает, что вероятность допустить ошибку второго рода при выявлении отклонения ±d от гипотетического значения 0 равна р.
▲ т(0)
0O"d ©1-a/2 ©О ©a/2 ©0+d
Рис. 3.5. Области принятия и отклонения гипотезы, соот-ветствующие ошибке второго рода при проверке гипотезы
Очевидно, что при любом заданном объеме выборки вероятность допустить ошибку первого рода можно сократить, уменьшив уровень значимости а. Однако при этом увеличивается вероятность допущения ошибки второго рода (снижается мощность критерия). Таким образом, в большинстве случаев нельзя добиться минимального значения вероятностей аир одновременно. Поступают обычно следующим образом: фиксируют вероятность а ошибки первого рода, а затем добиваются минимума вероятности р ошибки второго рода. За счет чего можно уменьшить р при фиксированном значении а? За счет правильного выбора критической области: при заданной альтернативе Hi критическую область выбирают таким образом, чтобы значение р (вероятность принять неверную гипотезу) было наименьшим из возможных. Таким образом, за-
72
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
дача состоит в построении наиболее мощного критерия (1- Р) при заданном уровне значимости а.
Различают односторонние и двусторонние критические области. Различные варианты областей представлены на рис. 3.6.
Если хотят убедиться, что одна случайная величина строго больше или строго меньше другой, то используют одностороннюю критическую область (рис.3.6.а,б).
Таким образом, для данного случая Н0: 0 = ©о;
Н1(1) :0<0О;
Н1(2)0>0О.
Если проверяют как положительные, так и отрицательные расхождения между изучаемыми величинами, то используют двусторонние критические области (рис.3.6,в)
Но : 0 = ©о ;
Н-|(3): 0 ф 0о .
Подводя итог всему вышесказанному, алгоритм проверки любой статистической гипотезы в самом общем случае заключается в следующем:
формулирование нулевой гипотезы Н0;
выбор одной из альтернативных гипотез Н/1) , Н/2) , Н/3';
поиск критерия, по которому может быть проверена сформулированная нулевая гипотеза Н0;
расчет значения статистики, применяемой для данного критерия;
выбор уровня значимости а;
построение критической области со при выбранном уровне значимости а;
принятие решения: если значение статистики попало в критическую область - нулевая гипотеза отвергается, при этом вероятность ошибки (первого рода) не превышает выбранный уровень значимости; в противном случае -нулевая гипотеза принимается.
73
3. ПРЕДВАРИТЕЛЬНАЯ ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ
а
б
в
f(0)
f(0)
отклонения И-
кр
л.еъ.а/2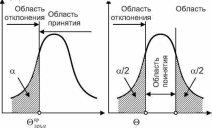
:(0) Область принятия |
Область отклонения |
|
|
\ а 1, |
0кр
пр,а
0кр /,
пр,ск/2
Рис. 3.6. Критические области плотности распределения: а - правосторонняя, б - левосторонняя, в - двусторонняя
При использовании механизма статистических гипотез следует помнить, что даже в случае принятия нулевой гипотезы в 100а% вывод будет ошибочным в связи со всегда имеющейся вероятностью совершить ошибку первого рода. Причем если значение статистики не попадает в критическую область, то прежде, чем принять нулевую гипотезу, необходимо оценить вероятность ошибки второго рода, т.е. рассчитать мощности критерия. Если же его величина оказывается недостаточной для решения поставленной задачи, требуется увеличение объема опытных данных (однако поскольку при обработке эксперимента исследователи зачастую уже не имеют возможности увеличить объем выборки, то они обычно пропускают данный пункт).