

Рассмотрим практическую оценку влияния отдельных факторов на зависимую переменную в построенной модели регрессии.
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако с их помощью непосредственно нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости.
Для устранения таких различий и противоречий для анализа и интерпретации применяются средние частные коэффициенты эластичности Э(j) и -коэффициенты (j), которые рассчитываются соответственно по формулам:
 ,
,
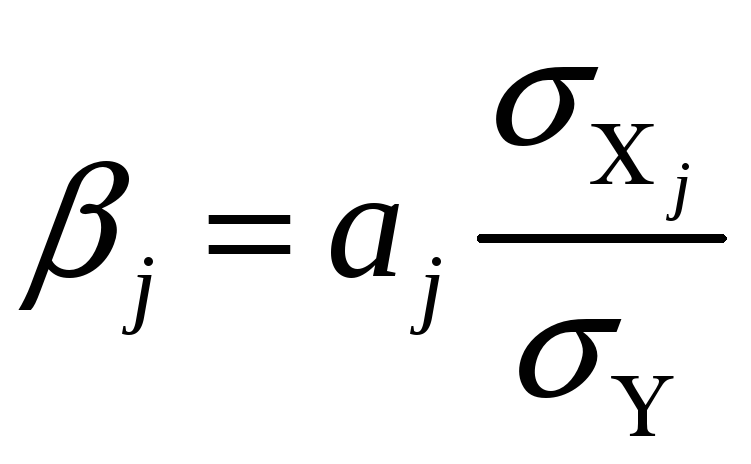 ,
,
где
![]() - среднее
квадратическое отклонение фактора j.
- среднее
квадратическое отклонение фактора j.
Коэффициент
эластичности
![]() показывает,
на сколько процентов изменяется зависимая
переменная при изменении j-го
фактора на 1 %. Однако здесь не учитывается
степень колеблемости факторов.
показывает,
на сколько процентов изменяется зависимая
переменная при изменении j-го
фактора на 1 %. Однако здесь не учитывается
степень колеблемости факторов.
Бета-коэффициент характеризует часть величины среднего квадратического отклонения а х на которую изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднего квадратического отклонения при фиксированном постоянном уровне значений остальных независимых переменных.
Указанные коэффициенты позволяют ранжировать факторы по степени их влияния на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов на результативный признак можно оценить по величине дельта-коэффициентов j
j=rYj j/R2,
где rYj - коэффициент парной корреляции между j-ым фактором (j = 1, ..., т) и зависимой переменной.
Разберём вопрос использования многофакторных моделей для анализа и прогнозирования развития экономических систем.
Одна из важнейших целей моделирования заключается в прогнозировании поведения исследуемого объекта. Обычно термин «прогнозирование» используется в тех ситуациях, когда требуется предсказать состояние системы в будущем. Для регрессионных моделей он имеет более широкое значение. Как уже отмечалось, данные могут не иметь временной структуры, но и в этих случаях вполне может возникнуть задача оценки значения зависимой переменной для некоторого набора независимых, объясняющих переменных, которых нет в исходных наблюдениях. Именно в этом смысле - как построение оценки зависимой переменной - и следует понимать прогнозирование в данной науке.
Проблема прогнозирования имеет много различных аспектов. Можно различать точечное и интервальное прогнозирование. В первом случае оценка - это конкретное число, во втором - интервал, в котором истинное значение переменной находится с заданным уровнем доверия. Кроме того, для временных рядов при нахождении прогноза существенно наличие или отсутствие корреляции по времени между ошибками.
При использовании построенной модели для прогнозирования делается предположение о сохранении в период прогнозирования существовавших ранее взаимосвязей переменных.
Для прогнозирования зависимой переменной на N шагов вперед необходимо знать прогнозные значения всех входящих в нее факторов. Их оценки могут быть получены с использованием МНК или на основе временных экстраполяционных моделей, а также могут быть заданы непосредственно пользователем. Эти оценки должны быть подставлены в модель, и таким образом получены прогнозные оценки.
Важен вопрос о факторах, влияющих на ширину доверительного интервала. Для того чтобы определить область возможных значений результативного показателя при рассчитанных значениях факторов, следует учитывать два возможных источника ошибок: ошибки, обусловленные рассеиванием наблюдений относительно линии регрессии и ошибки, обусловленные математическим аппаратом построения самой линии регрессии. Ошибки первого рода измеряются с помощью характеристик точности, в частности величиной Se.
Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
Для линейной модели доверительный интервал рассчитывается следующим образом. Оценивается величина отклонения U от линии регрессии:
U(l)
= Setкр![]() ,
(4)
,
(4)
где Vnp=XпрT(XT X)-1 Хпр,
Xпр =(X1(n+1),X21(n+1)),...,Xm1(n+1)).
Для модели парной регрессии формула (4) принимает вид:
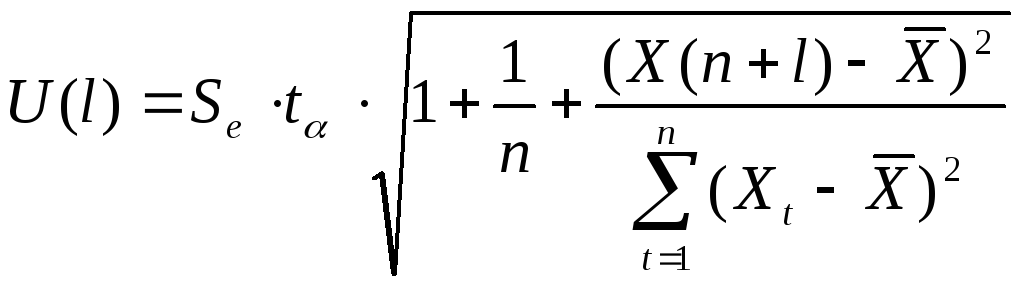 .
(5)
.
(5)
Коэффициент t является табличным значением t-статистики Стьюдента при заданном уровне значимости и числа наблюдений n, l-период прогнозирования.
Если исследователь задает вероятность попадания прогнозируемой величины внутрь доверительного интервала, равную 0,7 то t=1,05,
если вероятность составляет 0,95, то t=l,96, a при 0,99 t=2,65.
Как видно из формулы (5), величина U прямо пропорционально зависит от точности модели Se, коэффициенту доверительной вероятности t, степени удаления прогнозной оценки фактора X от среднего значения и обратно пропорциональна объему наблюдений.
В результате получается следующий интервал прогноза для шага прогнозирования l:
-
верхняя граница прогноза равна
Y(n + l) + U/(l),
-
нижняя граница прогноза равна
Y(n + l) - U(l).
Если построенная регрессионная модель адекватна и прогнозные оценки факторов достаточно надежны, то с заданным уровнем значимости можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадет в интервал, образованный нижней и верхней границами.
1.2. ПРАКТИЧЕСКИЕ ПРИМЕРЫ ПОСТРОЕНИЯ МОДЕЛЕЙ ВЗАИМОСВЯЗИ С ИСПОЛЬЗОВАНИЕМ ПАКЕТА АНАЛИЗА
MICROSOFT EXCEL
Используемый в данном разделе Пакет анализа – это, как известно, надстройка программы Excel, которая предоставляет широкие возможности для проведения статистического анализа в направлении исследования регрессионных и корреляционных процессов.
Для установки средств Пакет анализа в стандартной конфигурации программы Excel нет средства Пакет анализа. Это средство надо установить в качестве надстройки Excel. Для этого в зависимости от версии используемого программного средства необходимо выполнить действия, описываемые ниже.
При использовании версий ниже W2003 необходимо:
-
Выбрать команду Сервис => Надстройки.
-
В диалоговом окне Надстройки (рис. 2) установить флажок Пакет анализа.
-
Щелкнуть по кнопке ОК.
В результате выполненных действий в нижней части меню Сервис появится новая команда Анализ данных. Эта команда предоставляет доступ к средствам анализа, которые есть в Excel.
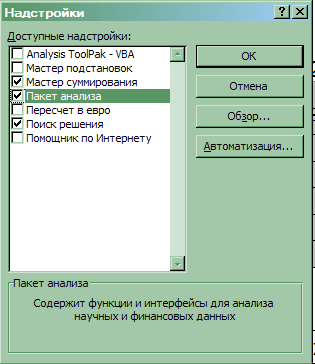
Рис. 2. Диалоговое окно Надстройки
При использовании версии Win2007, в параметрах Excel и диалоговом окне Надстройки также необходимо активизировать Пакет анализа
В результате выполненных действий появится новая команда Анализ данных. Эта команда предоставляет доступ к нужным средствам анализа, имеющимся в Excel.
Пример 1. Простейшее вычисление коэффициента корреляции в программе Microsoft Excel возможно с помощью функции КОРРЕЛ при задании характеристик следующим образом:
КОРРЕЛ (массив 1; массив 2),
где массив 1=диапазон данных для первой переменной,
массив 2=диапазон данных для второй переменной.
Так, в табл. 3 представлены выборочные данные об успеваемости шести студентов отобранных случайным образом.
Таблица 3
|
Экзаменационная оценка |
Количество часов, затраченное на самоподготовку в учебе |
|
3 |
86 |
|
5 |
95 |
|
4 |
92 |
|
4 |
83 |
|
2 |
78 |
|
3 |
82 |
На рис. 3 показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для данного примера с экзаменационными оценками.
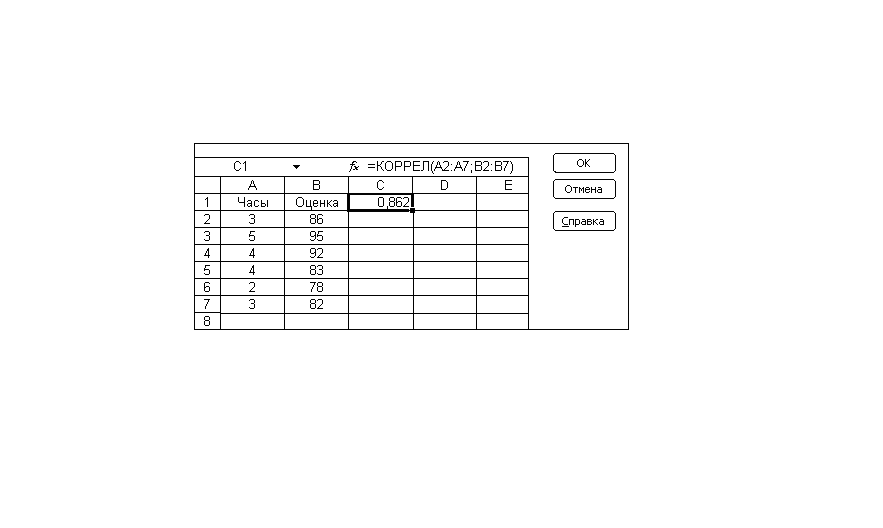
Рис. 3. Функция КОРРЕЛ на примере с экзаменационными оценками
Ячейка С1 содержит формулу = КОРРЕЛ(А2:А7; В2:В7) с результатом 0,862. Полученное значение фактического коэффициента корреляции r свидетельствует о наличии прямой тесной связи между успеваемостью и затратами времени на самоподготовку.
Пример 2. Рассмотрим возможности использования Excel для построения простейшей модели линейной регрессии.
Определим наличие линейной связи между временем и количеством реализованной машиностроительной продукции по видам из всего ассортиментного ряда на складе готовой продукции, используя возможности Excel.
Таблица 4
Реализация продукции по месяцам
|
Месяц |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Число видов реализованной продукции |
8 |
6 |
10 |
6 |
10 |
13 |
9 |
11 |
15 |
17 |
Введём данные на рабочее поле Excel в столбцы А и В чистого листа.
-
Активизируем меню Tools (Сервис) и надстройку Data Analysis (Анализ данных).
-
В окне Data Analysis (Анализ данных) выберем опцию Regression (Регрессия), как показано на рис. 4, и щелкнем ОК.

Рис. 4. Выбор опции линейной регрессии в Excel
-
Установим необходимые параметры регрессии в окне Regression (Регрессия), как показано на рис. 5. Щелкнем ОК и получим результаты, показанные на рис.5.
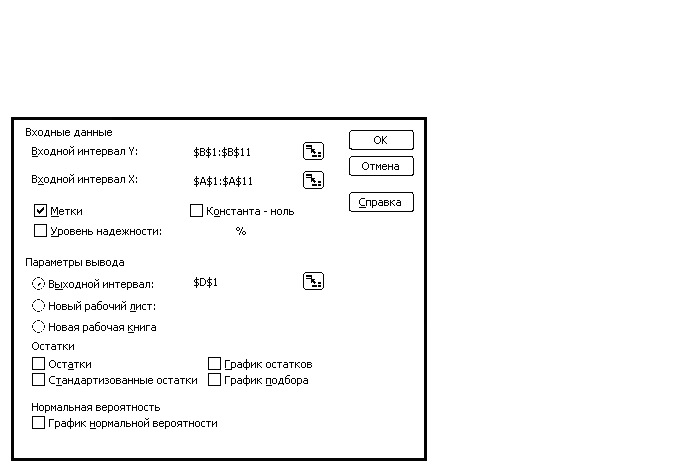
Рис. 5. Диалоговое окно Regression (Регрессия)
.
Рис. 6. Результаты регрессионного анализа в Excel
Поскольку уровень р-значимости для независимой переменной «Месяц» равен 0,00414, а это меньше α=0,01, следует отклонить основную гипотезу о независимости распределения во времени переменных и сделать вывод о существовании линейной связи между ними.
Пример 3. Оценим эффективность применения различных технологий в процессе производства и выполним однофакторный дисперсионный анализ в Excel по данным табл. 5.
Таблица 5
|
Выработка по цехам |
Технология 1 |
Технология 2 |
Технология 3 |
|
1 |
10,0 |
11,6 |
8,1 |
|
2 |
8,5 |
12,0 |
9,0 |
|
3 |
8,4 |
9,2 |
10,7 |
|
4 |
10,5 |
10,3 |
9,1 |
|
5 |
9,0 |
10,3 |
9,1 |
|
6 |
8,1 |
12,5 |
9,5 |
|
Среднее значение |
9,12 |
10,92 |
9,48 |
|
Дисперсия |
1,01 |
1,7 |
0,96 |
-
На чистом рабочем листе, в столбцы А, В и С введём данные из табл.5.
-
Откроем меню Tools (Сервис) и активизируем Data Analysis (Анализ данных).
-
В окне Data Analysis (Анализ данных) выберем опцию Anova: Single Factor (Однофакторный дисперсионный анализ), как показано на рис. 7, и щелкнем ОК.

Рис. 7. Выбор опции однофакторного дисперсионного
анализа в Excel
-
Укажем требуемые значения для проведения процедуры анализа в появившемся окне однофакторного дисперсионного анализа (рис. 8). Щелкнем ОК.
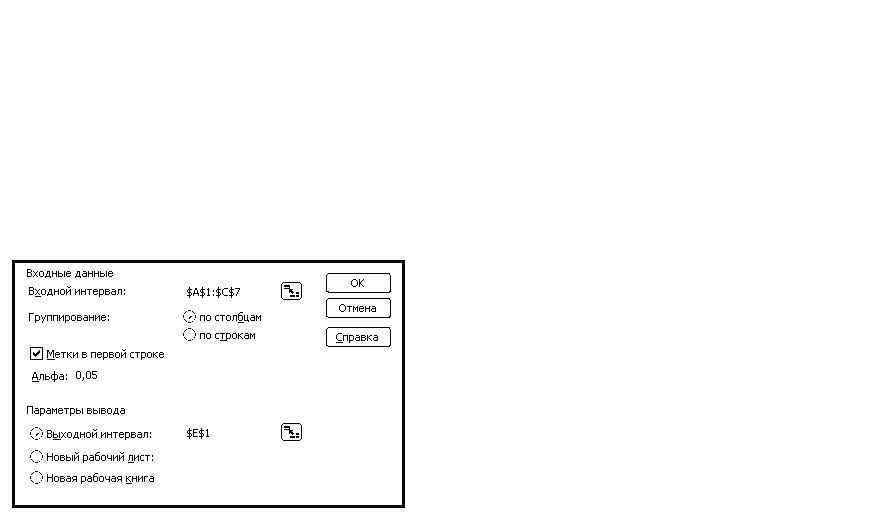
Рис. 8. Диалоговое окно Anova: Single Factor
(Однофакторный дисперсионный анализ)
-
На рис. 9 показаны результаты дисперсионного анализа.
Технология
1
Технология
2
Технология
3
Рис. 9. Результаты дисперсионного анализа
Здесь применялся полностью рандомизированный однофакторный анализ, подразумевающий независимый случайный отбор наблюдений для каждого уровня фактора.
Вариация внутри групп равна 16,45, а вариация между группами 13,01. Если вариация между выборками значительно превышает вариацию внутри выборки, вероятнее всего, что основная гипотеза, состоящая в одинаковом влиянии технологий на результат, будет отклонена.
Для проверки гипотезы о существенности связи воспользуемся значением F- критерия Фишера, которое сравнивается с критическим значением этого параметра. Вычисленное значение F- критерия превышает его критическое, что свидетельствует о неодинаковости средних по совокупности.
Уровень значимости равен 0,0126, а это значит, что следует отклонить Но, поскольку уровень р-значимости ≤ α (α=0,05).
Финальное заключение состоит в том, что одна из технологий в большей степени увеличивает производительность труда и даёт лучшие результаты, чем остальные.
Несмотря на то, что основная гипотеза отклонена и пришли к заключению, что средние по генеральной совокупности неодинаковы, ANOVA-анализ не позволяет сравнивать средние между собой, то есть нельзя доказать , что технология 2 лучше технологии 1 и хуже технологии 3. Для этого нужна ещё одна проверка.
Пример 4. Рассмотрим использование функции FРАСПОБР программы EXCEL для установления роли систематической и случайной вариаций в общей вариации и, следовательно, установления роли изучаемого факторного признака в изменении результативного.
Сгенерируем критические F-критерии при помощи функции FРАСПОБР со следующими характеристиками:
FРАСПОБР (вероятность; степени свободы 1; степени свободы 2), где:
-
вероятность=уровень значимости;
-
степени свободы 1=v1=k-1;
-
степени свободы 2=v2=N-k.
На рис. 10 показано полученное значение функции FРАСПОБР при определении критического значения F-критерия при α=0,05, v1=3-1=2 и v2=18-3=15 для данных предыдущего примера.
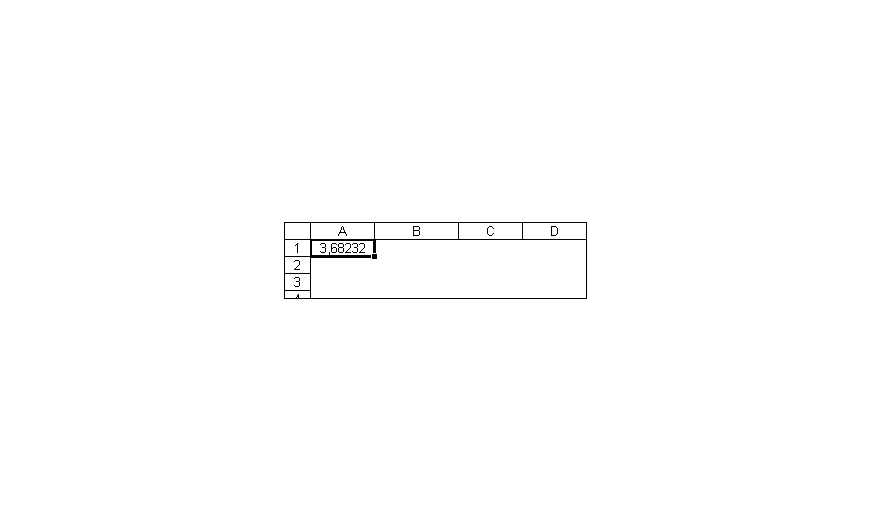
Рис. 10. Функция FРАСПОБР
Ячейка А1 содержит формулу = FРАСПОБР (0,05; 2; 15) с результатом 3,682. Эта вероятность получена в предыдущей таблице. Далее можно определить степень влияния каждой технологии на производительность с помощью проверки Шеффе.
Пример 5. Построим регрессионную модель, выявляющую связь между объемом реализации продукции одного вида от ряда факторных признаков ( временных и ценовых) предприятия.
Объем реализации - это зависимая переменная или результативный признак, обозначенный как Y. В качестве независимых, факторных переменных выбраны:
Х1 - время,
Х2 - расходы на материал,
Х3 - цена изделия,
Х4 - средняя цена по отрасли,
X5 - индекс расходов.
Собранные статистические данные по всем факторным признакам приведены в табл. 6.
В рассматриваемом примере число наблюдений составляло n = 16, число факторных признаков т = 5.
Таблица 6
Зависимость между объемом реализации продукции одного вида предприятия и различными факторными признаками
|
Y |
X1 |
Х2 |
Х3 |
Х4 |
Х5 |
|
126 |
1 |
4 |
15 |
17 |
100 |
|
137 |
2 |
4,8 |
14,8 |
17,3 |
98,4 |
|
148 |
3 |
3,8 |
15,2 |
16,8 |
101,2 |
|
191 |
4 |
8,7 |
15,5 |
16,2 |
103,5 |
|
274 |
5 |
8,2 |
15,5 |
16 |
104,1 |
|
370 |
6 |
9,7 |
16 |
18 |
107 |
|
432 |
7 |
14,7 |
18,1 |
20,2 |
107,4 |
|
445 |
8 |
18,7 |
13 |
15,8 |
108,5 |
|
367 |
9 |
19,8 |
15,8 |
18,2 |
108,3 |
|
367 |
10 |
10,6 |
16,9 |
16,8 |
109,2 |
|
321 |
11 |
8,6 |
16,3 |
17 |
110,1 |
|
307 |
12 |
6,5 |
16,1 |
18,3 |
110,7 |
|
331 |
13 |
12,6 |
15,4 |
16,4 |
110,3 |
|
345 |
14 |
6,5 |
15,7 |
16,2 |
111,8 |
|
364 |
15 |
5,8 |
16 |
17,7 |
112,3 |
|
384 |
16 |
5,7 |
15,1 |
16,2 |
112,9 |
Для установления связи будем использовать инструмент Корреляция.
Для проведения корреляционного анализа в данном случае необходимо выполнить следующие действия:
1. Расположить данные в смежных диапазонах ячеек.
2. Выбрать команду Сервис => Анализ данных (рис. 11). Появится диалоговое окно Анализ данных (рис. 12)
Рис.11. Выбор команды Анализ данных
3. В диалоговом окне Анализ данных выбрать инструмент Корреляция (рис.12), щелкнуть по кнопке ОК. Появится диалоговое окно Корреляция (рис.13).
Рис.12. Выбор команды Анализ данных
4. В диалоговом окне Корреляция в поле «Входной интервал» ввести диапазон ячеек, в которых содержатся исходные данные. Если выделены заголовки столбцов, то установить флажок «Метки в первой строке» (рис.13).
5. Выбрать параметры вывода. Для данного примера - установить переключатель «Новый рабочий лист».
6. Щелкнуть по кнопке ОК.
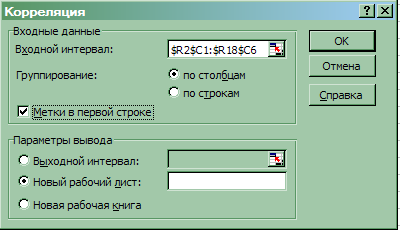
Рис.13. Диалоговое окно Корреляция
На новом рабочем листе получим результаты вычислений в виде таблицы значений коэффициентов парной корреляции (рис.14).
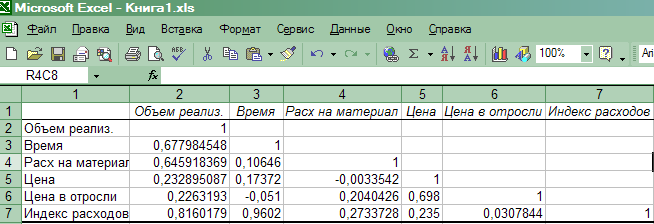
Рис. 14. Результаты корреляционного анализа
Выберем вид модели.
Анализ матрицы коэффициентов парной корреляции показывает, что зависимая переменная, т.е. объем реализации, имеет тесную связь:
- с индексом расходов ryX5 =0,816,
-
расходами на материал ryX2 = 0,646,
-
временем ryX1 = 0,678.
Однако факторы Х1 и Х5 тесно связаны между собой : rX1X5=0,96, что свидетельствует о наличии коллинеарости. Из этих двух переменных оставим в модели Х5 - индекс расходов. Переменные X1 (время), X3 (цена изделия) и Х4 (цена отрасли) также исключаем из модели, т.к. связь их с результативным признаком Y (объемом реализации) невысокая.
После исключения незначимых факторов имеем п=16,k = 2 и модель приобретает вид
![]() =
ао+а1Х2+а2Х5.
=
ао+а1Х2+а2Х5.
Оценим параметры модели.
На основе метода наименьших квадратов проведем оценку параметров регрессии по формуле (3). При этом используем данные, приведенные в табл.7.
Таблица 7
|
Y |
Х0 |
X2 |
X5 |
|
Объем реал. |
|
Реклама |
Инд. п.расходов |
|
126 |
1 |
4 |
100 |
|
137 |
1 |
4,8 |
98,4 |
|
148 |
1 |
3,8 |
101,2 |
|
191 |
1 |
8,7 |
103,5 |
|
274 |
1 |
8,2 |
104,1 |
|
370 |
1 |
9,7 |
107 |
|
432 |
1 |
14,7 |
107,4 |
|
445 |
1 |
18,7 |
108,5 |
|
367 |
1 |
19,8 |
108,3 |
|
367 |
1 |
10,6 |
109,2 |
|
321 |
1 |
8,6 |
110,1 |
|
307 |
1 |
6,5 |
110,7 |
|
331 |
1 |
12,6 |
110,3 |
|
345 |
1 |
6,5 |
111,8 |
|
364 |
1 |
5,8 |
112,3 |
|
384 |
1 |
5,7 |
112,9 |
Непосредственное вычисление (вычисление «вручную») вектора оценок параметров регрессии а согласно формуле (3) весьма громоздко, т.к. матрица независимых переменных X имеет довольно высокую размерность (16 х 3), матрица Y- размерности (16 х 1).
В табл. 8 приведены размерности матриц - результатов промежуточных действий.
Таблица 8
|
XT |
(3 х 16) |
|
ХTХ |
(3x3) |
|
(XTX)-1 |
(3x3) |
|
(ХTХ)-1ХT |
(3 х 16) |
|
(ХTX)-1ХTY |
(3x1) |
Задача существенно упрощается при использовании средств Excel. Операции, предписанные формулой (3), целесообразно проводить с помощью следующих встроенных в Excel функций:
•МУМНОЖ - умножение матриц,
•ТРАНСП - транспонирование матриц,
•МОБР - вычисление обратной матрицы.
Для вычисления вектора оценок параметров регрессии а в Excel необходимо выполнить следующие действия:
-
Ввести данные (табл. 6).
-
Выделить диапазон ячеек для записи вектора а, соответствующий его размерности (3x1) (рис. 15).
-
Используя встроенные в Excel функции, ввести формулу (3), определяющую вектор а.
-
Нажать одновременно клавиши CTRL + SHIFT + ENTER. Появится результат (рис. 16).
Таким образом, имеем
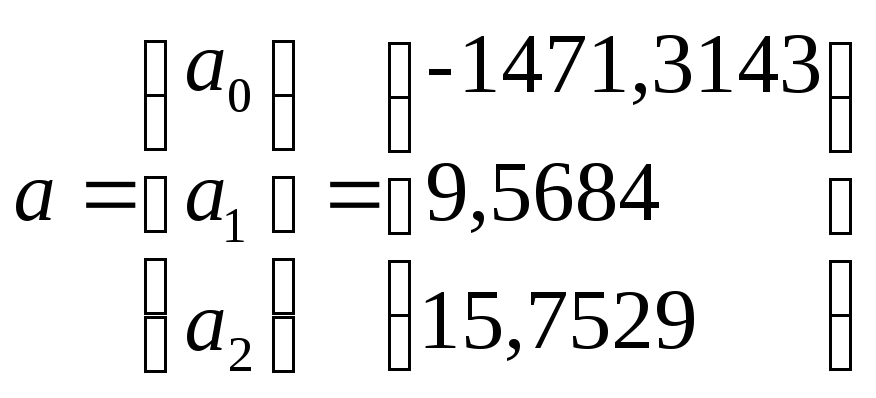
Рис. 15. Выделение диапазона ячеек (3 х 1) для записи вектора оценок параметров регрессии а
Уравнение регрессии зависимости объема реализации от затрат на рекламу и индекса потребительских расходов можно записать в виде:
![]() =
-1471,3143 + 9,5684 Х2+15,7529
Х5.
=
-1471,3143 + 9,5684 Х2+15,7529
Х5.
Расчетные значения Y определяются путем последовательной подстановки в эту модель значений факторов, взятых для каждого момента времени t.
Применение инструмента Регрессия в данном случае производится следующим образом.
Для проведения регрессионного анализа с помощью Excel выполните следующие действия:
-
Выбрать команду Сервис => Анализ данных.
-
В диалоговом окне Анализ данных выбрать инструмент Регрессия. Щелкните по кнопке ОК.
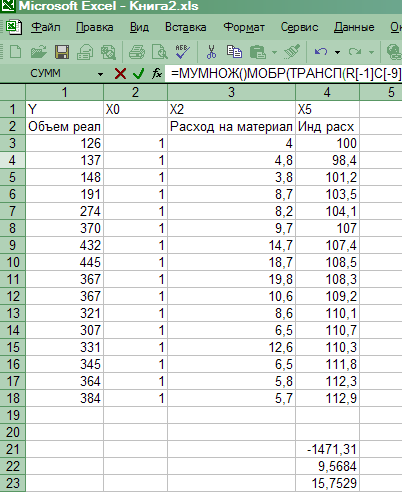
Рис. 16. Результат вычислений - вектор оценок параметров регрессии
-
В диалоговом окне Регрессия в поле «Входной интервал F» ввести адрес диапазона ячеек, который представляет зависимую переменную Y.
4. В поле «Входной интервал X» ввести адреса одного или нескольких диапазонов, которые содержат значения независимых переменных (в рассматриваемом примере - переменные Х2, Х5). Если выделены заголовки столбцов, то установить флажок «Метки в первой строке».
-
Выбрать параметры вывода. В данном примере – установить переключатель «Новая рабочая книга».
-
В поле «Остатки» поставить необходимые флажки.
-
Щелкнуть по кнопке ОК.
Результаты представлены на рис. 17 и в таблице на рис.18.
|
Обозначения в регрессионной статистике |
||
|
Наименования в отчете Excel |
Принятые наименования |
Формула |
|
Множественный R |
Коэффициент множественной корреляции, индекс корреляции |
|
|
R - квадрат
|
Коэффициент детерминации, R2 |
|
|
Нормированный R2 |
Скорректированный R2 |
|
|
Стандартная ошибка |
Стандартная ошибка оценки |
|
|
Наблюдения |
Количество наблюдений, п |
n |
Рис.17. «Регрессионная статистика»,
пояснения к таблице на рис.18
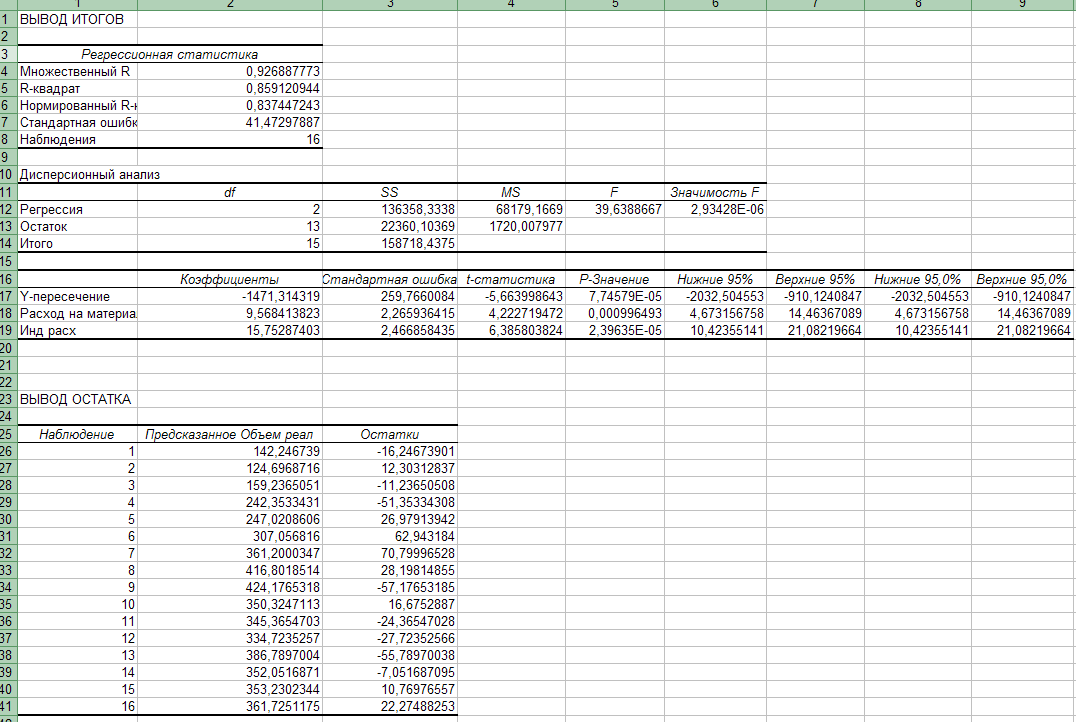
Рис. 18. Результаты регрессионного анализа, проведенного
с помощью Excel
|
|
Df - число степеней свободы |
SS -сумма квадратов |
MS |
F-критерий Фишера |
|
Регрессия
|
k
|
|
|
|
|
Остаток |
n-k-1 |
|
|
|
|
Итого |
n-1 |
|
|
|

Рис. 19. Пояснения к таблице «Дисперсионный анализ» на рис. 18
Во втором столбце таблицы дисперсионного анализа (рис. 18) содержатся коэффициенты уравнения регрессии а0, а1 а2, в третьем столбце содержатся стандартные ошибки коэффициентов уравнения регрессии, в четвертом - F-статистика, используемая для проверки значимости коэффициентов уравнения регрессии.
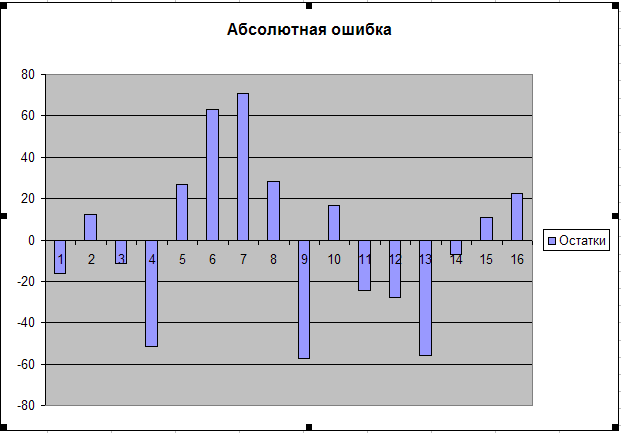
Рис.20. График остатков
Проведём оценку качества модели.
В
таблице «Вывод остатка» (рис. 18) приведены
вычисленные по модели
значения
![]() и
значения остаточной компоненты е.
и
значения остаточной компоненты е.
Исследование на наличие автокорреляции остатков проведен с помощью d-критерия Дарбина - Уотсона. Для определения величины d-критерия воспользуемся расчетной табл. 9.
Имеем
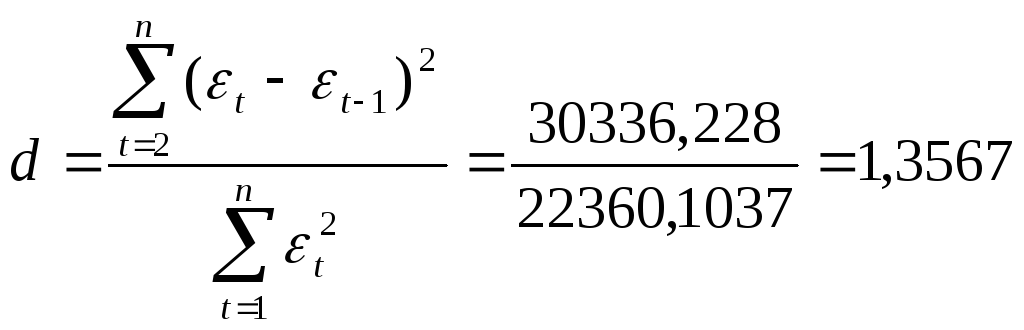 .
.
В качестве критических табличных уровней при n= 16, двух объясняющих факторах при уровне значимости = 0,05 возьмем величины вdL = 0,98 и dU=1,54 (приложения А и Б). Расчетное значение d = 1,3567 попало в интервал от dL= 0,98 до dU =1,54 (рис.21)
Таблица 9
|
Набл. |
Y |
Предск.Y |
|
|
|
|
(Y-Yср)2 |
|
1 |
126 |
142,2467 |
-16,2467 |
263,9565 |
|
|
32693,1602 |
|
2 |
137 |
124,6969 |
12,3031 |
151,3670 |
815,0949 |
-199,8857 |
28836,2852 |
|
3 |
148 |
159,2365 |
-11,2365 |
126,2590 |
554,1143 |
-138,2442 |
25221,4102 |
|
4 |
191 |
242,3533 |
-51,3533 |
2637,1658 |
1609,3607 |
577,0321 |
13412,5352 |
|
5 |
274 |
247,0209 |
26,9791 |
727,8740 |
6135,9778 |
-1385,469 |
1076,6602 |
|
6 |
370 |
307,0568 |
62,9432 |
3961,8444 |
1293,4125 |
1698,153 |
3992,6602 |
|
7 |
432 |
361,2000 |
70,8000 |
5012,6351 |
61,7290 |
4456,375 |
15671,9102 |
|
8 |
445 |
416,8019 |
28,1981 |
795,1356 |
1814,9148 |
1996,428 |
19095,7852 |
|
9 |
367 |
424,1765 |
-57,1765 |
3269,1558 |
7288,8361 |
-1612,272 |
3622,5352 |
|
10 |
367 |
350,3247 |
16,6753 |
278,0653 |
5454,0914 |
-953,4352 |
3622,5352 |
|
11 |
321 |
345,3655 |
-24,3655 |
593,6761 |
1684,3439 |
-406,3013 |
201,2852 |
|
12 |
307 |
334,7235 |
-27,7235 |
768,5939 |
11,2765 |
675,4967 |
0,0352 |
|
13 |
331 |
386,7897 |
-55,7897 |
3112,4907 |
787,7102 |
1546,687 |
585,0352 |
|
14 |
345 |
352,0517 |
-7,0517 |
49,7263 |
2375,3939 |
393,4115 |
1458,2852 |
|
15 |
364 |
353,2302 |
10,7698 |
115,9879 |
317,6042 |
-75,94502 |
3270,4102 |
|
16 |
384 |
361,7251 |
22,2749 |
496,1704 |
132,3677 |
239,8953 |
5957,9102 |
|
|
4909 |
4909,0000 |
0,0000 |
22360,1037 |
30336,2280 |
6811,9263 |
158718,4375 |






Рис. 21. Сравнение расчетного значения d-критерия Дарбина -Уотсона с критическими значениями вdL и dU
Так как расчетное значение d-критерия Дарбина-Уотсона попало в зону неопределенности, то нельзя сделать окончательный вывод об автокорреляции остатков по этому критерию.
Для определения степени автокорреляции вычислим коэффициент автокорреляции и проверим его значимость при помощи критерия стандартной ошибки. Стандартная ошибка коэффициента корреляции рассчитывается по формуле:
![]()
Коэффициенты автокорреляции случайных данных должны обладать выборочным распределением, приближающимся к нормальному с нулевым математическим ожиданием и средним квадратическим отклонением, равным
![]()
Если коэффициент автокорреляции первого порядка r1 находится в интервале
-1,96 * 0,25 < r1 < 1,96* 0,25,
то можно считать, что данные не показывают наличие автокорреляции первого порядка.
Используя расчетную таблицу 9, получаем:
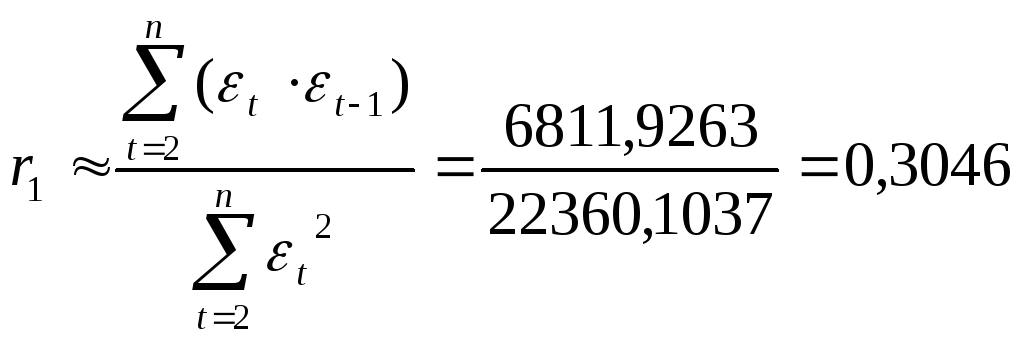 .
.
Так как -0,49 < r1 =0,3046 < 0,49, то свойство независимости остатков выполняется.
Вычислим для построенной модели множественный коэффициент детерминации
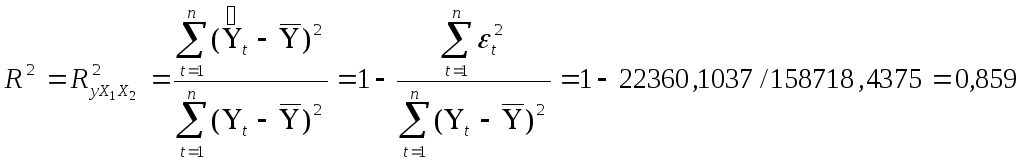 .
.
Множественный коэффициент детерминации показывает долю вариации результативного признака под воздействием включенных в модель факторов Х2 и Х5. Т.о., около 86 % вариации зависимой переменной (объема реализации) в построенной модели обусловлено влиянием включенных факторов Х2 (расходы на рекламу) и Х5 (индекс потребительских расходов).
Проверку значимости уравнения регрессии проведем на основе F-критерия Фишера
![]() .
.
Табличное значение F-критерия при доверительной вероятности 0,95, степенями свободы 1=k=2 и 2=(n-k-1)=16-2-1=13 составляет Fтабл=3,8.
Поскольку
Fфакт=39б599 Fтабл=3,8,
то уравнение регрессии следует признать адекватным.
Значимость коэффициентов уравнения регрессии а1 и а2 оценим с использованием t-критерия Стьюдента:
ta1=a1/Sa1=9,5684/2,2659=4,2227,
ta2=a2/Sa2=15,7529/2,4669=6,3857.
Табличное значение t-критерия Стьюдента при уровне значимости 0,05 и степенях свободы (16-2-1) = 13 составляет tma6n =2,16. Так как
ta1=4,2227 tma6n =2,16,
ta2=6,3857 tma6n =2,16,
то отвергаем гипотезу о незначимости коэффициентов уравнения регрессии а1 и а2.
Рассмотрим вопрос о влиянии факторов на зависимую переменную
Проанализируем влияние включенных в модель факторов на зависимую переменную по модели. Учитывая, что коэффициенты регрессии невозможно использовать для непосредственной оценки влияния факторов на зависимую переменную из-за различия единиц измерения, вычислим соответствующие коэффициенты эластичности, -коэффициенты:
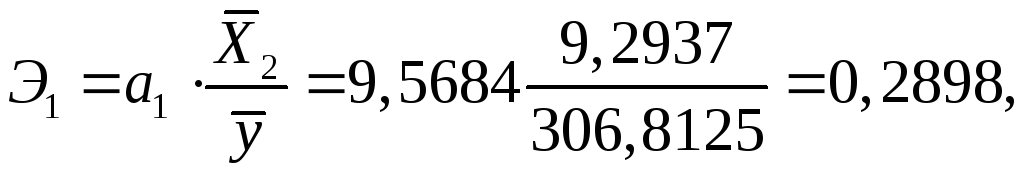
 ,
,
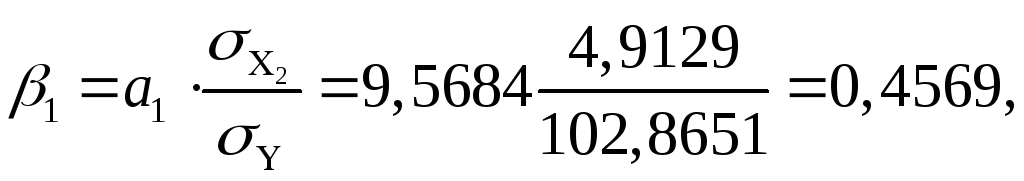 ,
,
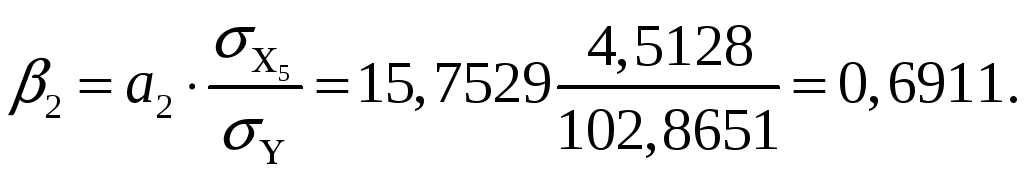 .
.
Таким образом, при увеличении расходов на материл на 1 % величина объема реализации изменится приблизительно на 0,3 %, при увеличении расходов на 1 % величина объема реализации изменится на 5,5 %.
Кроме того, при увеличении затрат на материалы на 4,9129 ед. объем реализации увеличится на 47 тыс. руб. (0,4569·102,865147), при увеличении расходов на 4,5128 ед. объем реализации увеличится на 71 ед. (0,6911·102,865171).
Проведём процедуру прогнозирования с использованием точечных и интервальных характеристик.
Найдем точечные и интервальные прогнозные оценки объема реализации на два квартала вперед.
Для построения прогноза результативного признака Y и оценок прогноза необходимо определить прогнозные значения включенных в модель факторов Х2 и Х5. В п. 1.3 на рис. 10 приведен результат построения тренда и прогнозирования по тренду для временного ряда «Индекс расходов».
В качестве аппроксимирующей функции выбран полином второй степени - парабола:
Х5 = 97,008 + 1,739 t - 0,0488 t2,
по которой построен прогноз на два шага вперед, причем прогнозные значения на 17-й и 18-й периоды соответственно составляют:
Х5(17) = 97,008+1,739·17-0,0488·172= 112,4678,
Х5(18) = 97,008 +1,739·18-0,0488 182= 112,4988.
Описанным способом (п. 1.3) построим линию тренда для временного ряда «Расходы на материалы» (рис. 22).
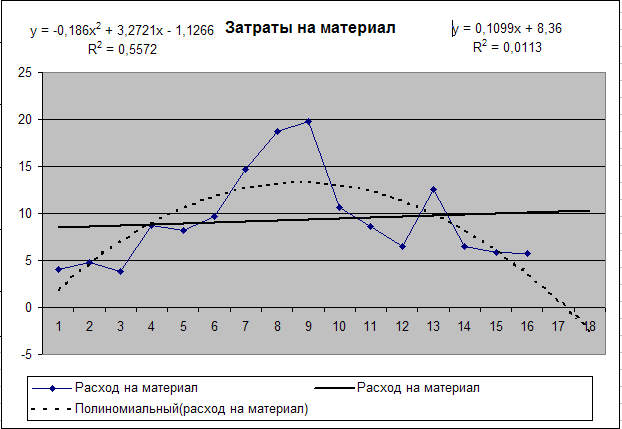
Рис. 22. Результат построения тренда и прогнозирования по тренду для временного ряда «Расходы на материал»
Для фактора Х2 «затраты на материал» выбираем полиномиальную модель пятой степени (этой модели соответствует наибольшее значение коэффициента детерминации):
Х2= -0,00055157·t5 + 0,02915029·t4 - 0,55145744·t3 + +4,31897327·t2 - 11,61564797·t + 12,83076923.
Замечание. Полиномы высоких порядков редко используются при прогнозировании экономических показателей. В этом случае при вычислении прогнозных оценок коэффициентов модели необходимо учитывать большое число знаков после запятой.
Прогнозные значения на 17-й и 18-й периоды соответственно составляют:
Х2(17) = 5,7485,
Х2(18) = 4,8485.
Для получения прогнозных оценок переменной 7 по модели
![]() =-1471,3143
+ 9,5684·X2+15,7529·X5
=-1471,3143
+ 9,5684·X2+15,7529·X5
подставим в нее найденные прогнозные значения факторов Х2 и Х5, получим:
![]() (17)
=-1471,3143
+ 9,5684·5,7485
+ 15,7529·112,4678
= 355,3805,
(17)
=-1471,3143
+ 9,5684·5,7485
+ 15,7529·112,4678
= 355,3805,
![]() (18)
=
-1471,3143 + 9,5684·4,8485
+ 15,7529·112,4988
= 347,2573.
(18)
=
-1471,3143 + 9,5684·4,8485
+ 15,7529·112,4988
= 347,2573.
Доверительный интервал прогноза имеет границы:
верхняя
граница прогноза:
![]() (n+l)
+ U(l),
(n+l)
+ U(l),
нижняя
граница прогноза:
![]() (n+l)
- U(l),
(n+l)
- U(l),
где
![]() ,
Vпр=XпрT(XTX)-1Xпр.
,
Vпр=XпрT(XTX)-1Xпр.
Имеем
![]() ,
,
tкр=2,16 (по таблице при =0,05 и числе степеней свободы 13),
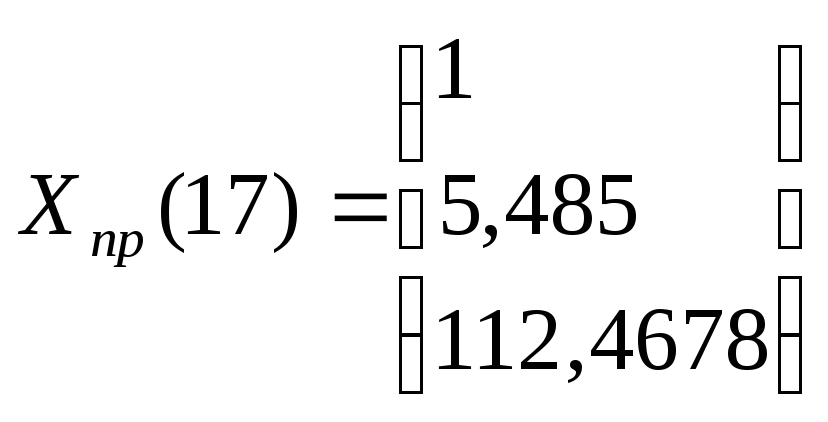 ,
,
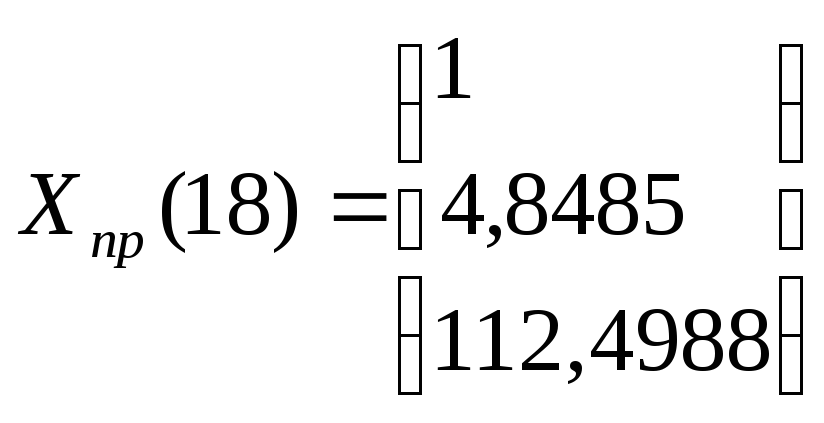 .
.
Тогда с использованием Excel ,
имеем
Vпр(17)=XпрT(XTX)-1Xпр=0,2300,
U(1)=41,473*2,16*![]() =42,9714
=42,9714
и
Vпр(18)=XпрT(XTX)-1Xпр=0,2613,
U(2)=41,473*2,16*![]() =45,7964.
=45,7964.
Результаты прогнозных оценок модели регрессии представим в таблице прогнозов (табл. 10).
Таблица 10
|
Упреждение |
Прогноз |
Нижняя граница |
Верхняя граница |
|
1 |
355,3805 |
312,4091 |
398,3520 |
|
2 |
347,2573 |
301,4609 |
393,0537 |