

Navch._posibnuk_Ivaschyk
.pdfНелінійні за змінними та параметрами багатопараметричні моделі можуть бути складними для аналізу, а сам розрахунок – зв’язаний з обчислювальними проблемами збіжності алгоритму. У таких випадках рекомендується починати з розгляду лінійної моделі або з попереднього розкладу задачі на декілька однопараметричних задач, і тільки після підбору нелінійних моделей для кожної із незалежних змінних переходити до загальної нелінійної багатопараметричної моделі.
Вхідні дані подаються у вигляді матриці, яка містить одну чи декілька незалежних змінних X і залежну змінну Y.
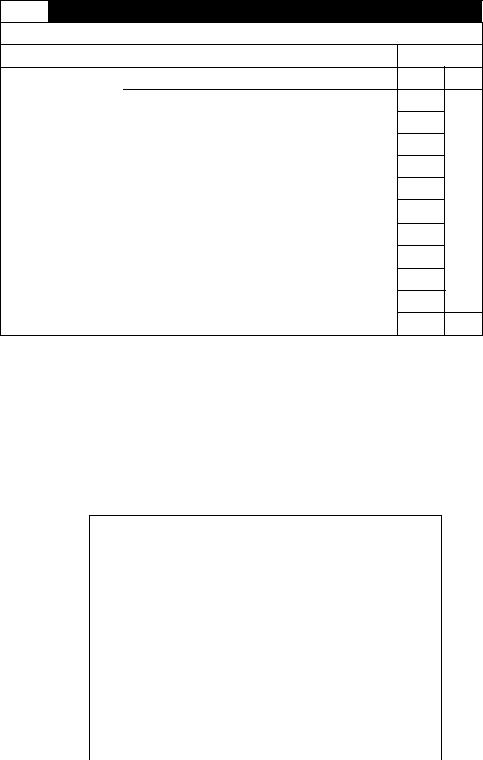
Діалог і результати. Після запуску процедури у типовому бланку формул (рис. 16.8.1) потрібно вибрати чи ввести заново в одну із позицій необхідну формулу моделі.
0Регрессионная модель
Формулы
h1= |
fligt=a0*COS(a1*Х4+a2) |
|
|||||||
2= |
py= a0*pх+a2*pх^2+a3*pх^3 |
|
|||||||
3= |
Y=a0+a1*X1+a2*X2+a3*X1*X2 |
|
|||||||
4= |
Y=a0+a1*Х1+a2*X2+a3*Х1^2+a4*X1*X2 |
||||||||
5= |
|
|
|
|
|
|
|
|
|
6= |
|
|
|
|
|
|
|
|
|
7= |
|
|
|
|
|
|
|
|
|
8= |
|
|
|
|
|
|
|
|
|
Редактор |
|
|
|
|
aУтвердить |
|
rОтменить |
||
Рис. 16.8.1. Бланк вибору регресійної моделі
Введення нових формул можна проводити безпосередньо в бланк, проте деколи зручно користуватися формульним редактором, який викликається натисканням кнопки «Редактор» після чого з’являється бланк редактора регресійної моделі (рис. 16.8.2).
Робота цього бланку аналогічна типовому формульному редактору STADIA [24. розд.12] з урахуванням таких доповнень:
h крім поля формули є поле залежної змінної з своєю кнопкою переносу із списку змінних ЕТ;
hу правій частині бланку розміщений список позначень коефіцієнтів регресійної моделі: а0 , а1, а2 ,…;
hпри завершальному формуванні моделі незалежна змінна приписується справа до формули і виділяється від неї за допомогою знака рівність.
531
0 |
|
|
|
Регрессионная модель |
|||
Редактор моделей |
|
|
|
||||
Переменные |
|
Регресионная модель |
|
||||
x(?) |
¾ |
a0*COS(a1*x4+a2) |
|
||||
sample |
|
|
|
|
|
|
|
px |
|
|
Y-переменная |
¿ |
Функции |
||
py |
|
|
|
|
|
|
|
¾ |
flight |
ABS(?) |
t |
||||
lx |
|
|
|
SQRT(?) |
|
||
|
|
|
|
||||
ly |
|
|
|
LN(?) |
|
||
|
|
|
|
||||
|
|
|
LOG(?) |
|
|||
time |
|
a Утвердить |
EXP(?) |
|
|||
ser |
|
|
|
INT(?) |
|
||
|
|
|
|
||||
|
|
|
|
|
FRACI(?) |
|
|
|
|
|
r Отменить |
|
|||
|
|
|
SIGN(?) |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
½
КАЛЬКУЛЯТОР
Коэфф.
а 0 t
а 1
а 2
а3
а4
а5
а6
а7
а8
а9
а10
а11 u
Рис. 16.8.2. Бланк редактора регресійної моделі
Після вибору моделі з’являється бланк для вводу початкових оцінок її параметрів (рис. 16.8.3), оскільки алгоритм і правильність для деяких випадків може суттєво залежати від початкових значень параметрів.
Оценки коэффициентов
а 0= |
1 |
|
|
aУтвердить |
|
а 1= |
1 |
|
|
|
|
а 2= |
1 |
|
|
|
|
|
1 |
|
|
|
|
а 3= |
|
|
Обнулить |
|
|
а 4= |
|
|
|
|
|
а 5= |
|
|
|
|
|
а 6= |
|
|
|
|
|
а 7= |
|
|
|
|
|
а 8= |
|
|
|
|
|
а 9= |
|
|
|
|
|
Рис. 16.8.3. Бланк вводу початкових оцінок коефіцієнтів нелінійної моделі
Якщо в окресленому бланку натиснути на кнопку «Обнулить», то початкові оцінки параметрів будуть встановлені рівними одиниці. Видача результатів процедури загальної (нелінійної) регресії стандартна з урахуванням поправок для множинної регресії. Для
532
однопараметричної регресії послідовність графічної видачі аналогічна розділу 7.3 [24].
Збіжність процесу мінімізації та його швидкість при розрахунку нелінійної моделі можуть тісно залежати від початкових оцінок коефіцієнтів і прийнятності моделі для наявних даних. Особливо це суттєво у випадку багатопараметричної моделі. Тому рекомендується спочатку приблизно оцінити характер залежності відгуку від кожної незалежної змінної, а після цього на цій основі компанувати та розраховувати нелінійну багатопараметричну модель.
Метод неможливо використати при m >30 або m> n, де n– число вимірів, m – число регресійних коефіцієнтів.
Приклад 16.15. Вихідними даними використовуємо файл MLR із прикл. 16.14. Розрахуємо для них повну лінійну модель, а також
повну лінійну модель, доповнену нелінійним |
членом Х12 . Три |
|||||
значення |
відгуку передбачаються для |
Х1 =1, Х2 =2; Х1 =2, |
Х2 =3 та |
|||
Х1 =1, Х2 =3. |
|
|
|
|
|
|
Результат: ОБЩАЯ (+НЕЛИНЕЙНАЯ)РЕГРЕССИЯ. Файл: mir. std |
|
|||||
Модель: Y=a0+a1*X1+a2*X2+a3*X1*X1 |
|
|
|
|||
Коэфф. |
а0 |
а1 |
а2 |
а3 |
|
|
Значение |
3.25 |
0.75 |
1.08 |
0.25 |
|
|
Ст.ошиб. |
0.434 |
0.336 |
0.232 |
0.18 |
|
|
Значим. |
0.0002 |
0.0544 |
0.0019 |
0.2 |
|
|
Источник |
Сум.квадр. |
Степ.своб. Средн.квадр |
|
|
|
|
Регресс. |
37.4 |
3 |
12.5 |
|
|
|
Остаточная |
2.58 |
8 |
0.323 |
|
|
|
Вся |
40 |
11 |
|
|
|
|
Множеств R |
R^2 |
R^2 прив |
Ст.ошиб. |
F |
Значим. |
|
0.967 |
0.935 |
0.911 |
0.568 |
38.6 |
0.0001 |
|
Гипотеза 1: <Модель адекватна экспериментальным данным> |
|
|
||||
X1 =1 |
X2 = 2 |
Y =6.67 |
|
|
|
|
X1 = 2 |
X2 = 3 |
Y=9.5 |
|
|
|
|
X1 = 1 |
X2 = 3 |
Y=8 |
|
|
|
|
Хэксп |
Yэксп |
Yрегр |
Остаток |
Ст.остат |
Ст.ошиб. Довер.инт. |
|
0 |
3 |
3.25 |
-0.25 |
-0.516 |
0.559 |
1.25 |
0 |
4 |
4.33 |
-0.333 |
-0.688 |
0.559 |
1.25 |
0 |
6 |
5.42 |
0.583 |
1.2 |
0.559 |
1.25 |
0 |
6 |
6.5 |
-0.5 |
-1.03 |
0.559 |
1.25 |
1 |
4 |
4 |
-7.28Е-12 |
-1.38Е-11 |
0.529 |
1.18 |
1 |
6 |
5.33 |
0.667 |
1.38 |
0.529 |
1.18 |
1 |
7 |
6.67 |
0.333 |
0.688 |
0.529 |
1.18 |
1 |
8 |
8 |
-7.28Е-12 |
1.63Е-11 |
0.529 |
1.18 |
2 |
5 |
4.75 |
0.25 |
0.516 |
0.559 |
1.25 |
2 |
6 |
6.33 |
-0.333 |
-0.688 |
0.559 |
1.25 |
2 |
7 |
7.92 |
-0.917 |
-1.89 |
0.559 |
1.25 |
2 |
10 |
9.5 |
0.5 |
1.03 |
0.559 |
1.25 |
533
Результат: ОБЩАЯ (+НЕЛИНЕЙНАЯ)РЕГРЕССИЯ. Файл: mir. std
Модель: Y=a0+a1*X1+a2*X2+a3*X1^2+ a4*X1*X2 |
|
|
|
|||
Коэфф. |
а0 |
а1 |
а2 |
а3 |
a4 |
|
Значение |
3.12 |
1.5 |
1.08 |
-0.375 |
0.25 |
|
Ст.ошиб. |
0.444 |
0.764 |
0.229 |
0.344 |
0.178 |
|
Значим. |
0.0004 |
0.0883 |
0.0025 |
0.312 |
0.2 |
|
Источник |
Сум.квадр. Степ.своб Средн.квадр |
|
|
|
||
Регресс. |
37.28 |
4 |
9.45 |
|
|
|
Остаточная |
2.21 |
7 |
0.315 |
|
|
|
Вся |
40 |
11 |
|
|
|
|
Множеств R |
R^2 |
R^2 прив |
Ст.ошиб. |
F |
Значим. |
|
0.972 |
0.945 |
0.913 |
0.562 |
29.9 |
0.0004 |
|
Гипотеза 1: <Модель адекватна экспериментальным данным> |
|
|
||||
X =1 |
X2 = 2 |
Y =6.92 |
|
|
|
|
X = 2 |
X2 = 4 |
Y=11 |
|
|
|
|
Хэксп |
Yэксп |
Yрегр |
Остаток |
Ст.остат |
Ст.ошиб |
Довер.инт |
0 |
3 |
3.12 |
-0.125 |
-0.279 |
0.517 |
1.16 |
0 |
4 |
4.21 |
-0.208 |
-0.465 |
0.517 |
1.16 |
0 |
6 |
5.29 |
0.708 |
1.58 |
0.517 |
1.16 |
0 |
6 |
6.38 |
-0.375 |
-0.837 |
0.517 |
1.16 |
1 |
4 |
4.25 |
-0.25 |
-0.558 |
0.489 |
1.1 |
1 |
6 |
5.58 |
0.417 |
0.93 |
0.489 |
1.1 |
1 |
7 |
6.92 |
0.0833 |
0.186 |
0.489 |
1.1 |
1 |
8 |
8.25 |
-0.25 |
-0.558 |
0.489 |
1.1 |
2 |
5 |
4.63 |
0.375 |
0.837 |
0.517 |
1.16 |
2 |
6 |
6.21 |
-0.208 |
-0.465 |
0.517 |
1.16 |
2 |
7 |
7.79 |
-0.792 |
-1.77 |
0.517 |
1.16 |
2 |
10 |
9.37 |
0.625 |
1.39 |
0.517 |
1.16 |
Результати проведеного аналізу показують, що помітне покращення за стандартною помилкою порівняно з моделлю з прикладу 16.14 дає тільки перша модель. Для другої моделі, крім цього, обидва коефіцієнти нових членів отримують з достатньо значною помилкою, тому її неможливо розглядати як суттєво кращу порівняно з двома попередніми.
16.9.Питання для самоконтролю
1.Опишіть постановку класичної лінійної багатофакторної моделі.
2.Побудуйте систему нормальних рівнянь для економетричної моделі з трьома незалежними змінними.
3.Сформулюйте властивості методу найменших квадратів.
4.Опишіть алгоритм оцінки параметрів моделі у матричній формі.
5.Опишіть етапи алгоритму визначення параметрів багатофакторної моделі.
534
6.Сформулюйте основні передумови застосування методу найменших квадратів.
7.Опишіть алгоритм узагальненого методу найменших квадратів.
8.Охарактеризуйте основні умови, які необхідно враховувати при побудові багатофакторних моделей.
9.Дайте тлумачення виробничої функції та опишіть основні характеристики виробничих функцій.
10.Як визначається коефіцієнт множинної детермінації і його зв’язок із скорегованим коефіцієнтом детермінації ?
11.Як визначається коефіцієнт множинної кореляції ?
12.Дайте тлумачення коефіцієнтів парної кореляції та запишіть формули їх знаходження.
13.Що є нормалізацією вихідних даних ?
14.Як визначається матриця парних коефіцієнтів кореляції ?
15.Дайте тлумачення коефіцієнтів частинної кореляції та запишіть формули їх знаходження.
16.Побудуйте матрицю коефіцієнтів частинної кореляції, якщо результативний показник формується під впливом трьох факторів.
17.Опишіть процедуру оцінки якості виробничої функції регресії на основі стандартних помилок оцінок параметрів моделі.
18.Побудуйте дисперсійно-коваріаційну матрицю для трьох незалежних змінних.
19.Запишіть формулу знаходження відносного показника розсіяння оцінок параметрів моделі.
20.Опишіть основні фактори від яких залежить стандартна помилка коефіцієнта регресії.
21.Дайте тлумачення значущості економетричної моделі.
22.Як визначається критерій Фішера ? Його застосування.
23.Дайте тлумачення значущості коефіцієнтів детермінації та кореляції.
24.Як обчислюється t-критерій ?
25.Сформулюйте гіпотези про значущість параметрів економетричної моделі.
26.Як визначити довірчий інтервали параметрів моделі ?
27.Як визначити довірчі інтервали коефіцієнта кореляції ?
535
28.Опишіть алгоритми побудови прогнозної моделі.
29.Опишіть алгоритм покрокової регресії.
30.Охарактеризуйте різновидності процедури покрокової регресії в системі STADIA.
31.Дайте тлумачення множинної нелінійної регресії.
32.Запишіть функцію Кобба-Дугласа та сформулюйте її основні характеристики.
33.Опишіть процедуру побудови нелінійної регресії у системі
STADIA.
34.Побудуйте економетричну модель, яка описує залежність випуску валової продукції концерну від вартості основних виробничих фондів (млн. грн.), затрат праці (млн. люд.-год.), ритмічності виробництва (частини). Звітні дані наведено у такій таблиці:
Номер структурного |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
підрозділу |
|||||||||||
|
|
|
|
|
|
|
|
|
|
Обсяг випуску про-дукції, |
10,1 |
14,2 |
12,0 |
17,4 |
16,3 |
20,4 |
22,0 |
22,4 |
21,6 |
24,1 |
|
млн.грн. |
|
|
|
|
|
|
|
|
|
|
|
Вартість основних ви- |
5,4 |
6,6 |
6,2 |
5,3 |
7,4 |
8,5 |
8,0 |
9,2 |
9,4 |
12,0 |
|
робничих фондів, млн.грн. |
|||||||||||
|
|
|
|
|
|
|
|
|
|
||
Затрати праці, млн. люд-год. |
1,2 |
1,8 |
1,6 |
2,1 |
2,0 |
2,6 |
2,8 |
3,6 |
3,2 |
3,8 |
|
Ритмічність виробництва, |
0,75 |
0,81 |
0,78 |
0,85 |
0,82 |
0,89 |
0,9 |
0,86 |
0,92 |
0,95 |
|
частини |
|||||||||||
|
|
|
|
|
|
|
|
|
|
35.Обчисліть коефіцієнти множинної детермінації та кореляції для економетричної моделі, використавши дані завд. 34
36.Використовуючи статистичні дані завд. 34, знайдіть коефіцієнти парної кореляції.
37.Згідно з завд. 34 обчисліть частинні коефіцієнти кореляції.
38.Оцініть якість економічної моделі (завд. 34) з допомогою процедури стандартних помилок оцінок параметрів моделі.
39.Перевірте гіпотези про значущість економетричної моделі
(завд. 34).
40.Перевірте гіпотези для коефіцієнтів множинної детермінації та кореляції.
41.Перевірте гіпотези про значущість параметрів економетричної моделі (завд. 34).
536
42.Побудуйте довірчі інтервали параметрів моделі (завд. 34).
43.Знайдіть довірчі інтервали коефіцієнта множинної кореляції
(завд. 35).
44.Побудуйте точковий та інтервальний прогнози для економетричної моделі (завд. 34), якщо на прогнозний період відомий вектор:
|
|
|
1 |
|
|
|
|
23,4 |
|
|
|
|
|
|
X |
|
= |
9,1 |
. |
|
a |
|
3,8 |
|
|
|
|
|
|
|
|
|
0,9 |
|
|
|
|
|
45.Побудуйте економетричну модель методом покрокової регресії, використавши умову завд. 34.
46.Використовуючи програмний продукт STADIA, виконайте завд. 45.
47.Побудуйте економетричну модель типу Кобба-Дугласа, використавши умову завд. 34.
537
Розділ 17. Економетричні моделі динаміки
17.1. Економетричний аналіз часових рядів
Часовий ряд – це сукупність послідовних вимірювань деякої змінної економічного процесу, проведених через рівні інтервали значень деякого параметра (часу чи просторової координати).
Економетричний аналіз часових рядів з допомогою програмного продукту STADIA [24] дає можливість розв’язати такі основні завдання:
hдослідження структури часового ряду, який, як правило, відображається закономірною зміною середнього рівня (тренду) та наявністю періодичних коливань;
hпобудова математичної моделі економічного процесу, представленого часовим рядом;
hпрогнозування майбутнього розвитку економічного процесу ; hдослідження причинно-наслідкових взаємозв’язків між економічними процесами, які проявляються у вигляді різноманітних
взаємних кореляцій між часовими рядами.
Для розв’язання цих та інших завдань економетричного аналізу часових рядів в системі STADIA існує необхідна кількість різноманітних методів, серед яких можна виокремити такі:
hметоди кореляційного аналізу, які дають можливість виявити найбільш суттєві періодичні залежності та їх лаги (затримки) в одному процесі (автокореляція) або між декількома процесами (кроскореляція); hметоди спектрального аналізу дозволяють знаходити
періодичні та квазіперіодичні залежності в даних;
hметоди згладжування та фільтрації призначені для перетворення часових рядів з метою усунення з них високоякісних або сезонних коливань;
hметоди авторегресії та ковзного середнього є особливо корисними для опису та прогнозування процесів, які виявляють однорідні коливання навколо середнього значення.
Значна частина методів аналізу зорієнтована на стаціонарні процеси, статистичні властивості яких не змінюються протягом часу (середнє та дисперсія постійні у випадку нормального розподілу). Однак багато часових рядів мають нестаціонарний характер. У ряді випадків нестаціонарність можна усунути шляхом:
538

hвирахування тренду чи процесу зміни середнього значення, представленого деякою детермінованою функцією, підібраною шляхом процедур простої чи поліномної регресії;
hфільтрація нестаціонарним фільтром, нулі якого знаходяться тільки на одиничному колі (стохастичний тренд).
Зметою стандартизації часових рядів буває доцільним провести
їїзагальне чи сезонне центрування та нормування на стандартне відхилення шляхом відповідних операцій блоку перетворення даних. Центрування ряду спрямоване на усунення ненульового середнього значення, яке може завадити інтерпретації результатів (наприклад, при спектральному аналізі). Мета нормування – запобігти в обрахунках операцій з великими числами, що може призвести до переповнення результату.
Внаслідок наведених вище перетворень часового ряду можна побудувати його математичну модель, за якою здійснене прогнозування, тобто одержане певне продовження часового ряду.
Проте, щоб результати прогнозу можна було би порівняти з вхідними даними, з ними треба провести перетворення, зворотні виконаним, що робиться засобами блоку перетворень.
17.1.1. Аналіз і прогнозування тренду
Основною характерною рисою, яка виділяє часові ряди від інших видів статистичних даних, є суттєвість порядку, в якому здійснюються спостереження.
При дослідженні економічних процесів та явищ використовуються дискретні часові ряди. Дискретний часовий ряд можна розглядати як послідовність значеньy1, y2 ,..., yn у момент часу
t (скорочено yt (t =1, n)).
Часовий ряд можна представити таким чином: |
|
yt = xt + εt , |
(17.1) |
де xt – детермінована невипадкова складова (тренд) відповідного процесу;εt – стохастична випадкова складова даного процесу.
Детермінована складова xt характеризує існуючу динаміку процесу повністю, тобто часову тенденцію зміни показника, який вивчається. Стохастична складова εt відображає випадкові коливання
або шуми відповідних процесів. Завдання процесу прогнозування
539
полягає у визначенні виду екстраполяційних функцій xt і εt на основі
вхідних емпіричних даних.
Аналіз тренду призначений для дослідження закону зміни або маневру локального середнього значення часового ряду з побудовою математичної моделі тренду та прогнозуванням на цій основі майбутньої поведінки часового ряду. Аналіз тренду проводиться процедурою простої регресії.
Вхідні дані, що використовуються методом простої регресії, є двома змінними з матриці даних, одна з яких містить значення часового параметра, а інша – значення часового ряду.
Значення часового параметра легко сформувати з допомогою генератора послідовності зростаючих з фіксованим кроком чисел у блоці перетворень даних.
У ході аналізу тренду можна отримати такі результати: hвипробувати декілька математичних моделей тренду й
вибрати ту, яка з більшою точністю описує динаміку зміни часового ряду;
hпобудувати прогноз майбутньої поведінки часового ряду на основі вибраної моделі тренду з 95 % довірчим інтервалом;
hвилучити тренд із часового ряду для забезпечення його стаціонарності, необхідної для кореляційного та спектрального аналізу (для цього після розрахунку регресійної моделі виконується аналіз залишків і зберігається в матриці даних).
Приклад 17.1. Дослідити та побудувати тренд на основі даних за 1997-2006 р.р. зовнішнього боргу держави (табл. 17.1). Розрахувати прогнозні показники на 2007 та 2011 р.р., якщо основна тенденція описується експоненціальною залежністю.
Таблиця 17.1
Рік |
1997 |
1998 |
1999 |
2000 |
2001 |
|
|
|
|
|
|
Зовнішній борг, |
49370866.15 |
79538915.66 |
77020449.37 |
74629740.51 |
75729102.93 |
млн. грн. |
|
|
|
|
|
Рік |
2002 |
2003 |
2004 |
2005 |
2006 |
Зовнішній борг, |
77533476.67 |
85401136.2 |
78146568 |
80548517.36 |
88744741.81 |
млн. грн. |
|
|
|
|
|
Для побудови моделі використаємо процедуру «Простая регрессия/тренд» системи STADIA [24].
540