

Назаметдинов Анализ данных 2012
.pdf10.1. Вычисление главных компонент
Вычисление весовых коэффициентов будем проводить последовательно, начиная с первой главной компоненты. Значение первой главной компоненты z1 для i-го объекта (i=1,2,…,N) составит
z1i a11x1i a21x2i ... an1xni , |
i 1,2,...,N . |
(10.3) |
Вводя векторное обозначение Z1 (z11, z12 ,...,z1N ) , |
выражение |
|
(10.3) можно записать в виде |
|
|
Z1 Xa1 . |
|
(10.4) |
Оценка дисперсии D(z1) центрированной переменной z1 есть по определению среднее квадрата ее значений. Таким образом,
|
|
D(z1) |
1 |
|
Z1' Z1 |
1 |
|
( Xa1)'( Xa1) a1' ( |
1 |
|
X ' X )a1 . (10.5) |
|
|
N 1 |
N 1 |
N 1 |
|||||||
|
|
|
|
|
|
||||||
1 |
X X |
есть не что иное, как оценка матрицы ковариаций ис- |
|||||||||
|
|||||||||||
N 1 |
|||||||||||
ходных признаков 1 2 n . Эту оценку обозначим ˆ . Выраже- x , x ,..., x C
ние (10.5) примет вид:
(10.5а)
Вектор параметров a1 необходимо подобрать так, чтобы дис-
персия D(z1) была максимальной. Если на параметры не накладывать никаких ограничений, то, очевидно, такая задача не имеет ко-
нечного решения. Потребуем, чтобы норма (длина) вектора a1 , равнялась единице:
a1a1 1. |
(10.6) |
Для максимизации (10.5а) при ограничении (10.6) воспользуемся методом неопределенных множителей Лагранжа. Определим функцию
ˆ ,
(a1, ) a1Ca1 λ1(a1a1 1)
где λ1 – множитель Лагранжа.
Дифференцирование (a1, ) по отдельным элементам вектора a1 компактно может быть записано так:
231
|
|
|
φ |
ˆ |
|
|
|
|
|
|
2Ca1 2λ1a1 . |
|
|
|
|
|
a1 ' |
|
||
Полагая |
φ |
0 , получаем |
|
|
||
|
|
|
||||
|
a1 ' |
|
|
|||
|
|
|
ˆ |
λ1a1 . |
(10.7) |
|
|
|
|
Ca1 |
|||
|
|
|
|
|
|
ˆ |
Из (10.7) видно, что a1 – собственный вектор матрицы C , соот- |
||||||
ветствующий собственному значению λ1. |
|
|||||
Из (10.6) и (10.7) следует, что |
|
|
||||
|
|
|
|
|
ˆ |
|
|
|
D(z1) a1Ca1 a1λ1a1 λ1 . |
|
|||
Поскольку D z1 максимизируется, в качестве |
1 выбирается |
|||||
ˆ .
наибольшее собственное значение матрицы С
При поиске значений элементов вектора a2 , кроме ограничения
на норму вектора, аналогичного (10.6), требуется обеспечить ортогональность векторов значений первой и второй главных компо-
нент Z1 и Z2 . Так как скалярное произведение ортогональных век-
|
|
|
|
|
|
ˆ |
|
торов равняется нулю, а матрица С симметричная и, следователь- |
|||||||
ˆ |
ˆ |
|
|
|
|
|
|
но, С С , то справедлива следующая цепочка равенств: |
|||||||
|
0 Z1' Z2 |
(Xa1)'(Xa2 ) a1' X ' Xa2 |
|||||
|
|
ˆ |
|
|
ˆ |
(N 1)λ1a1' a2 . |
|
|
a1' (N 1)Ca2 |
(N 1)(Ca1)'a2 |
|||||
Поскольку ни (N-1), ни нулю не равны, имеем: |
|||||||
|
|
|
|
a1a2 0 . |
(10.8) |
||
Определим функцию Лагранжа следующим образом: |
|||||||
|
|
|
ˆ |
2 |
|
2 2 2 |
1 2 , |
|
φ |
2 |
λ |
||||
|
a Ca |
a a 1 |
μ a a |
||||
где λ2 |
и μ – множители Лагранжа. |
|
|||||
Приравняем нулю частную производную φ по a2 : |
|||||||
|
|
φ |
ˆ |
|
2λ2a2 μa1 0 . |
||
|
|
|
2Ca2 |
||||
|
|
a2 |
|||||
Умножая последнее равенство слева на a1 и принимая во внимание условие нормировки (10.6), получаем:
232
|
ˆ |
μ |
0 . |
||
|
2a1Ca2 |
||||
Учитывая, что |
ˆ |
|
|
|
|
a1C λ1a1 , а также условие (10.8), имеем: |
|||||
|
μ 0 . |
|
|||
Следовательно, соотношение (10.8) примет вид |
|||||
|
ˆ |
|
2 |
|
2 , |
|
2 |
|
|||
|
Ca |
|
λ |
a |
|
где в качестве 2 выбирается второе по величине собственное зна-
чение матрицы |
ˆ . |
Этот процесс продолжается до тех пор, |
пока не |
С |
|||
исчерпается список всех n собственных значений матрицы |
ˆ |
||
С . По- |
|||
лученные в результате n собственных векторов матрицы составят ортогональную матрицу:
An n [a1 a2 ...a j ...an ] .
В итоге, значения главных компонент задаются матрицей:
|
|
|
|
|
ZN n X N n An n . |
|
(10.9) |
||||
Ковариационная матрица главных компонент есть |
|
||||||||||
|
1 |
|
|
|
1 |
|
|
ˆ |
|
||
|
|
|
|
Z ' Z A' |
|
X ' XA A'CA . |
|
||||
|
|
N 1 |
N 1 |
|
|||||||
Введем диагональную матрицу собственных значений |
|
||||||||||
|
|
|
|
|
λ1 |
0 |
|
0 |
|
||
|
|
|
|
|
|
|
λ2 |
|
|
|
|
|
|
|
|
|
0 |
0 |
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
0 |
λn |
|
||
Тогда |
ˆ |
|
|
|
|
|
|
||||
CA A , и окончательное выражение для ковариацион- |
|||||||||||
ной матрицы главных компонент приобретает вид |
|
||||||||||
|
1 |
|
|
ˆ |
|
|
|
|
|||
|
|
|
|
Z Z |
|
A CA |
A A , |
(10.10) |
|||
|
|
|
N 1 |
||||||||
поскольку A′A = I в силу ортогональности собственных векторов. Следовательно, главные компоненты попарно некоррелированы,
а их дисперсии совпадают с собственными значениями ковариационной матрицы исходных переменных.
233
Если ранг матрицы Х меньше n , то у матрицы |
ˆ |
будет k нуле- |
С |
вых собственных значений, и изменения в переменных x1, x2 ,..., xn
могут быть полностью выражены с помощью n-k независимых переменных. При отсутствии нулевых собственных значений некоторые λi могут оказаться весьма близкими к нулю, так что суще-
ственный вклад в суммарную дисперсию будут вносить первые несколько главных компонент.
Суммарная дисперсия исходных переменных, равная следу мат-
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
|
рицы С , равняется суммарной дисперсии главных компонент. Дей- |
|||||||||||||
ствительно, |
|
|
|
|
|
|
|
|
|
|
. |
||
|
|
|
|
|
|||||||||
|
1 |
|
|
|
ˆ |
|
|
ˆ |
|
ˆ |
|
||
tr |
|
|
|
Z Z |
|
tr A CA |
|
tr CAA |
|
SpC |
|
||
N 1 |
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
||||
Здесь мы воспользовались свойством неизменности следа произведения матриц при перестановке сомножителей, т.е. tr(AB)=tr(BA) (предполагается, что произведение ВА существует). Тогда отношения
q1 |
1 |
, q2 |
λ2 |
,…, qk |
λk |
, k n |
n |
n |
n |
||||
|
i |
|
λi |
|
λi |
|
|
i 1 |
|
i 1 |
|
i 1 |
|
характеризуют пропорциональный вклад каждого вектора, представляющего главные компоненты, в суммарную дисперсию исходных переменных.
Накопленные отношения
Q1 q1, Q2 q1 q2 ,..., Qk q1 q2 ... |
qk , |
k n |
показывают относительную долю в суммарной дисперсии исходных переменных, которая приходится на первые k главных компонент. Задавшись некоторым порогом , для дальнейшего анализа оставляют те первые k΄ главных компонент, для которых
Qk 1 , а Qk .
В заключение сделаем два замечания.
1. Переход к главным компонентам наиболее естественен и эффективен, когда исходные признаки имеют общую физическую природу и измерены в одних и тех же единицах. Если это условие
234
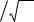
не имеет место, то результаты иcследования с помощью главных компонент будут существенно завиcеть от выбора масштаба и природы единиц измерения. В качестве практического средства в таких ситуациях можно рекомендовать переход к вспомогательным
безразмерным признакам xi*, i 1,2,...,n нормированием исходных
признаков x |
по формуле x* x |
σ2 |
где σ2 |
– дисперсия i-го при- |
|
i |
i |
i |
i |
i |
|
знака.
2. Аналитически доказано, что переход от исходного n-мерного пространства к m-мерному пространству главных компонент сопровождается наименьшими искажениями суммы квадратов расстояний между всевозможными парами точек наблюдений, расстояний от точек наблюдений до их общего центра тяжести, а также углов между прямыми, соединяющими всевозможные пары точек наблюдений с их общим центром тяжести
Геометрическая интерпретация главных компонент. Для n-
мерного вектора a с ковариационной матрицей С можно постро-
ить так называемый эллипсоид рассеяния:
a a C 1 a a n 2 ,
где a – вектор средних значений элементов a .
Точки, соответствующие наблюдениям вектора а, будут располагаться примерно в очертаниях этого эллипсоида. На рис. 10.1 приведена двумерная иллюстрация эллипсоида рассеяния.
В методе главных компонент исходные наблюдения предполагаются центрированными. Переход к центрированным наблюдениям означает перенос начала координат в точку (x1, x2 ) . Затем оси
координат поворачивают на угол α так, чтобы ось z1 шла вдоль главной оси эллипсоида рассеяния. Наблюдения в новых координатах z1 и z2 станут независимыми.
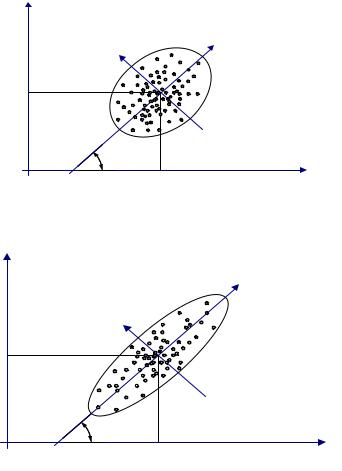
Чем теснее наблюдения группируются около главной оси эллипсоида рассеяния, являющейся теперь новой координатой z1, тем менее значащим является для исследователя разброс точек в направлении оси z2, а следовательно, и сама эта координата (рис.10.2).
235
x2 |
|
|
|
|
|
|
z2 |
z1 |
|
|
|
|
|
|
_ |
|
|
|
|
x 2 |
|
|
|
|
|
α |
|
_ |
|
|
|
x1 |
x1 |
|
|
|
|
||
Рис.10.1. Двумерный эллипсоид рассеяния |
|
|||
x 2 |
|
|
|
|
|
|
|
z 1 |
|
|
|
z2 |
|
|
_ |
|
|
|
|
x 2 |
|
|
|
|
α |
|
|
_ |
|
|
|
x1 |
x1 |
|
|
|
|
||
Рис.10.2. «Вытянутый» эллипсоид рассеяния |
|
|||
10.2. Статистические свойства главных компонент
При вычислении матрицы весовых коэффициентов использова-
ˆ
лась выборочная ковариационная матрица C , полученная по результатам наблюдений конечного числа N объектов. Если объем выборки увеличить за счет привлечения дополнительных объектов,
236

то естественно ожидать, что пересчет главных компонент изменит оценки собственных значений и элементов собственных векторов. Степень изменения оценок зависит от N. Чем больше N, тем меньше эти изменения. Иными словами, можно ожидать, что для больших выборок главные компоненты совпадают с главными компонентами всей генеральной совокупности.
Здесь рассматриваются некоторые оценки близости выборочных и теоретических характеристик главных компонент. Как принято в статистике, выборочные значения в отличие от теоретических будем помечать знаком ^ над буквами.
Прежде всего следует заметить, что проведение подобных оценок возможно, если принять некоторые допущения, а именно: исследуемая генеральная совокупность подчиняется многомерному нормальному закону, а извлеченные из нее выборки взаимно независимы. Приведем без доказательства ряд утверждений.
1. Собственные значения и собственные векторы, найденные по выборочной ковариационной матрице, являются оценками максимального правдоподобия и обладают всеми хорошими свойствами этих оценок (состоятельность, асимптотическая эффективность).
2. Величины |
ˆ |
асимптотически нормаль- |
N 1(λi λi ), i 1,2,...n |
ны со средним значением, равным нулю, и дисперсией, равной 2λi2 , и независимы от других выборочных собственных значений.
Последнее утверждение дает основу для нахождения доверительного интервала для i-го собственного значения λi . А именно:
|
|
|
|
|
|
1 |
|
|
|
|
|
1 |
|
|
u |
2 |
|
|
|
u |
2 |
|
|||||
λ 1 |
|
|
|
|
λ λ 1 |
|
|
, |
|||||
ˆ |
|
|
|
|
|
|
|
ˆ |
|
|
|
|
|
|
i |
2 |
N 1 |
|
|
|
|
i i |
2 |
N 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
где α – уровень значимости; |
|
uα 2 |
– значение аргумента функции |
||||||||||
стандартного нормального распределения, которое находится из таблиц из условия
P U u  2 1 2α .
2 1 2α .
Проиллюстрируем определение главных компонент на примере. Пример. Выборочная ковариационная матрица имеет вид:
237
|
|
|
25 |
0 |
9 |
|
|
|
ˆ |
|
|
|
|
|
|
C 0 |
16 |
0 . |
||
|
|
|
9 |
0 |
4 |
|
|
|
|
|
|
|
|
ˆ |
составляют характеристическое уравнение |
|||||
По матрице C |
||||||
|
|
25 λ |
0 |
|
9 |
|
|
|
|
|
|||
|
|
0 |
16 λ |
0 |
0 , |
|
|
|
9 |
0 |
|
4 λ |
|
которое сводится к виду |
|
|
|
|
||
(25 -λ ) ( 1 6 -λ ) ( 4 -λ ) – 92 (16-λ ) = 0 . |
||||||
Решая получающееся уравнение относительно , находят: λ1 28,33; λ2 16, λ3 0,67 .
Заметим, что программы вычисления собственных значений и собственных векторов входят практически во все пакеты прикладных программ по статистике.
Для рассматриваемого примера найдем первый собственный вектор а1. Как следует из (10.7) и (10.6)
25 28,33 |
0 |
9 |
a11 |
|
|
|
0 |
|
|
|
|
|
||
|
0 |
16 28,33 |
0 |
a |
21 |
|
|
|
0 |
, a2 |
a2 |
a2 |
1 . |
|
|
|
|
|
|
|
|
|
|
|
11 |
21 |
31 |
|
|
|
9 |
0 |
|
|
|
|
|
|
0 |
|
|
|
|
|
|
4 28,33 a31 |
|
|
|
|
|
|
|
|
|||||
Отсюда находим: |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
a11 0,94; |
a21 0; |
|
a31 0,35. |
|
|
|||||||
Накопленные отношения, показывающие долю суммарной дисперсии, обусловленной первой и второй и всеми тремя главными компонентами, составляют:
Q1 |
|
λ1 |
|
|
0,63; Q2 |
|
|
λ1 + λ2 |
|
0,985; Q3 1 . |
|||
λ |
+ λ |
2 |
+ λ |
3 |
λ |
+ λ |
2 |
+ λ |
3 |
||||
1 |
|
|
|
1 |
|
|
|
||||||
Полученные значения позволяют сделать вывод, что 63% изменчивости исходных переменных приходится на долю первой главной компоненты:
238
z1 0,94x1 0,35x3 .
Первые две главные компоненты практически полностью «выбирают» разброс исходных переменных.
10.3. Приложения главных компонент
10.3.1. Регрессия на главные компоненты
Возможность сокращения числа предикторов за счет выделения главных компонент используется в регрессионном анализе в случае нехватки числа степеней свободы либо как способ борьбы с мультиколлинеарностью. Процедура применения достаточно очевидна:
1)по матрице F значений базисных функций находят главные компоненты;
2)отбрасывают те из них, которые соответствуют малым значениям собственных чисел;
3)ищется регрессия на оставшиеся главные компоненты;
4)от оценок коэффициентов регрессии на главные компоненты
переходят к оценкам на исходные базисные функции.
Пусть ищется линейная регрессия у=b1x1+b2x2+b3x3+-b4x4+u на четыре центрированные переменные х1,х2,х3,х4.
Из четырех главных компонент ограничимся двумя первыми:
z1 a11x1 a21x2 a31x3 a41x4 ; z2 a12x1 a22x2 a32x3 a42x4.
Регрессия у на z1 и z2 имеет вид:
y c1z1 c2 z2 e c1(a11x1 ... a41x4 ) c2 (a12x1 ... a42x4 ) e(c1a11 c2a12)x1 ... (c1a41 c2a42)x4 e .
Если бы использовались все четыре главные компоненты, то оценки последнего уравнения совпали бы с оценками прямой ре-
грессии у на х1,х2,х3,х4: bi c1ai1 c2ai2 c3ai3 c4ai4 , i=1,2,3,4.
Сравнивая коэффициенты при xi, видим, что отбрасывая часть главных компонент (при условии, что соответствующие λ≠0), мы привносим смещение в оценки коэффициентов регрессии.
Оценка вектора с есть cˆ (Z Z ) |
1 |
~ |
. С учетом (10.10) получаем |
|
Z y |
239
1 |
~ |
|
1 |
j ~ j |
|
cˆ |
/(N 1)Z y |
, иначе cˆi |
|
zi y |
,i=1,2,…,n. |
(N 1) i |
Последнее выражение показывает, что при отбрасывании компонент с малыми значениями λ, исключаются большие по модулю сˆ , т.е. мы приходим к редуцированным оценкам.
10.3.1.Сингулярный спектральный анализ
Вглаве, посвященной временным рядам, мы ограничились рядами сравнительно простой структуры с единственной периодической составляющей – сезонной компонентой. В реальных рядах периодическая составляющая часто имеет более сложную структуру
ихарактеризуется переменными периодом и амплитудой. Выделение и представление структурных компонент ряда,
включая все возможные периодики, имеет большое прикладное значение. Оказалось, что главные компоненты могут помочь в выявлении структуры ряда и его прогнозировании. В зарубежной
литературе метод получил название сингулярный спектральный анализ (Singular Spectrum Analysis – SSA), в отечественной испо-
льзуется также название «метод гусеница». Идея метода состоит в представлении одномерного ряда в виде совокупности его представительных фрагментов (траекторной матрицы) с последующим разложением исходного временного ряда (точнее, его траекторной матрицы) по базису, порождаемому им самим. Метод не требует изначальной спецификации модели исследуемого временного ряда. Тем не менее он позволяет разложить ряд на элементарные составляющие, что по ним оказывается возможным выявить тренд или найти периодические составляющие.
Метод "гусеница" содержит четыре этапа:
1.Развёртка одномерного ряда в многомерный.
2.Выделение главных компонент – сингулярное разложение выборочной ковариационной матрицы.
3.Отбор главных компонент.
4.Восстановление одномерного ряда.
Перейдём к более подробному описанию каждого этапа.
240