

2.12. Использование оцененной модели для прогнозирования
Пусть мы имеем модель наблюдений в виде модели простой линейной регрессии
![]()
и хотим дать
прогноз, каким будет значение объясняемой
переменной
![]() при некотором выбранном (фиксированном)
значении
при некотором выбранном (фиксированном)
значении![]() объясняющей переменной
объясняющей переменной![]() ,
если мы будем продолжать наблюдения.
,
если мы будем продолжать наблюдения.
Мы умеем оценивать
коэффициенты
![]() и
и![]() методом наименьших квадратов, и
естественно использовать для целей
прогнозирования получаемую в результате
такого оценивания (подобранную) модель
линейной связи
методом наименьших квадратов, и
естественно использовать для целей
прогнозирования получаемую в результате
такого оценивания (подобранную) модель
линейной связи
![]()
что приводит к прогнозируемому значению объясняемой переменной, равному
![]()
Вопрос только в том, сколь надежным является выбор такого значения в качестве прогнозного. И здесь надо иметь в виду следующее.
Поскольку
мы используем для прогноза оценки,
полученные, исходя из модели наблюдений
![]() то для того, чтобы этот прогноз был
осмысленным, нам по необходимости
приходится предполагать, что структура
модели наблюдений и ее параметрыне
изменятся
при переходе к новому наблюдению, так
что соответствующее
то для того, чтобы этот прогноз был
осмысленным, нам по необходимости
приходится предполагать, что структура
модели наблюдений и ее параметрыне
изменятся
при переходе к новому наблюдению, так
что соответствующее
![]() значение
значение![]() должно описыватьсятем
же линейным
соотношением
должно описыватьсятем
же линейным
соотношением
![]() .
В таком случае, мы по-существу имеем
дело с расширенной линейной моделью с
.
В таком случае, мы по-существу имеем
дело с расширенной линейной моделью с![]() наблюдениями, в которой дополнительное
наблюдение удовлетворяет соотношению
наблюдениями, в которой дополнительное
наблюдение удовлетворяет соотношению
![]()
При этом, случайная
величина
![]() должна иметьто жераспределение,
что и случайные величины
должна иметьто жераспределение,
что и случайные величины![]() и должна образовывать вместе с ними
множество случайных величин, независимых
в совокупности.
и должна образовывать вместе с ними
множество случайных величин, независимых
в совокупности.
Итак, мы договорились, что в расширенной модели
![]()
Выбирая в качестве
прогноза для
![]() значение
значение![]() мы
тем самым допускаемошибку прогноза,
равную
мы
тем самым допускаемошибку прогноза,
равную
![]()
Поскольку
вычисленные оценки
![]() являются (как мы уже выяснили выше)
реализациями случайных величин,
наблюдаемая ошибка прогноза также
является реализацией случайной величины
являются (как мы уже выяснили выше)
реализациями случайных величин,
наблюдаемая ошибка прогноза также
является реализацией случайной величины![]() и включает два источника неопределенности:
и включает два источника неопределенности:
неопределенность, связанную с отклонением вычисленных значений случайных величин
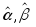 от
истинных значений параметров
от
истинных значений параметров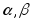 ;
;неопределенность, связанную со случайной ошибкой
 в
в -
м наблюдении.
-
м наблюдении.
При наших стандартных
предположенияхо линейной модели
наблюдений ошибка прогноза являетсяслучайной величиной![]() ,
имеющей математическое ожидание
,
имеющей математическое ожидание
![]()
(Мы использовали
здесь справедливые при выполнении
стандартных предположений соотношения
![]() )
)
Точность прогноза характеризуется дисперсией ошибки прогноза
![]()
Здесь использован
тот факт, что сумма
![]() неслучайна(хотя ее точное значение
и не известно). Далее, из предположенной
независимости случайных ошибок
неслучайна(хотя ее точное значение
и не известно). Далее, из предположенной
независимости случайных ошибок![]() и
и![]() вытекает независимость случайных
величин
вытекает независимость случайных
величин![]() (эта величина зависит от случайных
ошибок
(эта величина зависит от случайных
ошибок![]() )
и
)
и![]() (последняянезависит от случайных
ошибок
(последняянезависит от случайных
ошибок![]() ).
В силу же независимости
).
В силу же независимости![]() и
и![]() ,
,
![]()
(использовано правило сложения дисперсий). Остается заметить, что

где, как обычно,
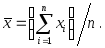 (Мы не будем выводить эту формулу.) Таким
образом,
(Мы не будем выводить эту формулу.) Таким
образом,
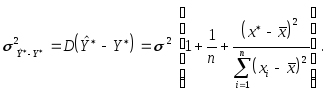
Если случайные
ошибки
![]() имеютнормальноераспределение, то
тогда случайные величины
имеютнормальноераспределение, то
тогда случайные величины![]() и
и![]()
также имеют
нормальные распределения. При этом,
ошибка прогноза
![]() имеет нормальное распределение с нулевым
математическим ожиданием и дисперсией,
вычисляемой по последней формуле.
имеет нормальное распределение с нулевым
математическим ожиданием и дисперсией,
вычисляемой по последней формуле.
Разделив разность
![]() на квадратный корень из ее дисперсии,
получаем случайную величину
на квадратный корень из ее дисперсии,
получаем случайную величину
![]()
имеющую стандартноенормальное распределение![]() .
Заменяя в правой части выражения для
.
Заменяя в правой части выражения для![]() неизвестное
значение
неизвестное
значение![]() его несмещенной оценкой
его несмещенной оценкой![]() ,
получаем оценку дисперсии
,
получаем оценку дисперсии![]() в виде
в виде

Заменяя, наконец,
в знаменателе отношения, имеющего
стандартное нормальное распределение,
неизвестное значение
![]() его оценкой
его оценкой![]() ,
приходим к
,
приходим к![]() -статистике
(
-статистике
(![]() -отношению)
-отношению)
![]()
имеющей при
выполнении сделанных предположенийо модели наблюдений![]() -распределение
Стьюдента
-распределение
Стьюдента![]() с
с![]() степенями
свободы.
степенями
свободы.
Последний факт
дает возможность построения
![]() -процентного
доверительного интерваладля значения
-процентного
доверительного интерваладля значения![]()
а именно,
![]()
на основании
которого получаем
![]() -процентный
доверительный интервалдля
-процентный
доверительный интервалдля![]() :
:
![]()
— здесь мы
использовали то, что в силу симметрии
распределения Стьюдента,
![]() .
.
Заметим, что при
заданных значениях
![]() (по
которым строится прогноз) доверительный
интервал для
(по
которым строится прогноз) доверительный
интервал для![]() будеттем длинее, чем больше значение
будеттем длинее, чем больше значение![]() .
Последнее же равно
.
Последнее же равно![]() при
при![]() и возрастает с ростом
и возрастает с ростом![]() .
Это означает, что длина доверительного
интервалавозрастаетпри удалении
значения
.
Это означает, что длина доверительного
интервалавозрастаетпри удалении
значения![]() ,
при котором строится прогноз, от среднего
арифметического значений
,
при котором строится прогноз, от среднего
арифметического значений![]() .
.
Таким образом,
прогнозы для значений
![]() ,
далеко отстоящих от
,
далеко отстоящих от![]() ,
становятся менее определенными, поскольку
длина соответствующих доверительных
интервалов для значений объясняемой
переменной возрастает.
,
становятся менее определенными, поскольку
длина соответствующих доверительных
интервалов для значений объясняемой
переменной возрастает.
Пример. Для
данных о размерах совокупного
располагаемого дохода и совокупных
расходах на личное потребление в США в
период с 1970 по 1979 год (в млрд.
долларов, в ценах 1972 года), оцененная
модель линейной связи имеет вид![]() .
.
Представим себе,
что мы находимся в 1979 году и ожидаем
увеличения в 1980 году совокупного
располагаемого дохода (в тех же ценах)
до
![]() млрд. долларов. Тогда прогнозируемый
по подобранной модели объем совокупных
расходов на личное потребление в
1980 году равен
млрд. долларов. Тогда прогнозируемый
по подобранной модели объем совокупных
расходов на личное потребление в
1980 году равен
![]()
так что если выбрать
уровень доверия
![]() ,
то
,
то
![]()
и доверительный
интервал для соответствующего
![]() значения
значения![]() имеет вид
имеет вид
![]()
т. е.
![]()
или
![]()
Заметим, что интервал достаточно широк и его нижняя граница допускает даже возможность некоторого снижения уровня потребления по сравнению с предыдущим годом.
В действительности, в 1980 г. совокупный располагаемый доход достиг млрд. долларов, а совокупное потребление — млрд. долларов. Тем самым, ошибка прогноза составила
![]()
Если бы мы исходили
при прогнозе из действительного
значения![]() ,
а не из
,
а не из![]() ,
то прогнозируемое значение для
,
то прогнозируемое значение для![]() равнялось быи ошибка прогноза составила всего лишь
равнялось быи ошибка прогноза составила всего лишь
![]()
Проиллюстрируем,
наконец, как изменяется в этом примере
длина %-доверительных
интервалов в интервале наблюдавшихся
значений объясняющей переменной![]() .
На графике приведены отклонения нижней
и верхней границ таких интервалов от
центра интервала:
.
На графике приведены отклонения нижней
и верхней границ таких интервалов от
центра интервала:

В случае модели множественной линейной регрессии
![]()
точечный прогноззначения![]() соответствующегофиксированномунабору
соответствующегофиксированномунабору![]() значений объясняющих переменных, дается
формулой
значений объясняющих переменных, дается
формулой
![]()
где
![]() —
оценки наименьших квадратов параметров
—
оценки наименьших квадратов параметров![]() .Интервальный прогноз имеет вид
.Интервальный прогноз имеет вид
![]()
где
![]()
оценка дисперсии ошибки прогноза, а
 -
несмещенная оценка дисперсии
-
несмещенная оценка дисперсии случайных
ошибок.
случайных
ошибок.