

Описательная статистика
Задачи описательной статистики – классификация данных, построение распределения их частот и выявление центральных тенденций этого распределения и оценка разброса данных относительно средних.
Для классификации данных сначала располагают их в возрастающем порядке. Далее их разбивают на классы по величине, интервалы между которыми определяются в зависимости от того, что именно исследователь хочет выявить в данном распределении.
К наиболее часто используемым параметрам, с помощью которых можно описать распределение, относятся, с одной стороны, такие величины, как мода, медиана и среднее арифметическое, а с другой – показатели разброса, такие как варианса (дисперсия) и стандартное отклонение.
Мода соответствует значению, которое встречается чаще других или находится в середине класса, обладающего наибольшей частотой.
Медиана соответствует значению центрального данного, которое может быть получено после того, как все данные будут расположены в возрастающем порядке.
Среднее арифметическое равно частному от деления суммы всех данных на их число.
Распределение считается нормальным, если кривая распределения имеет колоколообразный вид, а все показатели центральной тенденции совпадают, что свидетельствует о симметричности распределения.
Диапазон распределения (размах вариаций) равен разности между наибольшим и наименьшим значениями результатов.
Среднее отклонение – это более точный показатель разброса, чем диапазон распределения. Для расчета среднего отклонения вычисляют среднюю разность между всеми значениями данных и средним арифметическим.
Еще один показатель разброса, вычисляемый из среднего отклонения, – это варианса (дисперсия), равная среднему квадрату разностей между значениями всех данных и средним.
Наиболее употребительным показателем разброса служит стандартное отклонение, равное квадратному корню из вариансы. Таким образом, это квадратный корень из суммы квадратов всех отклонений от среднего.
Важное свойство стандартного отклонения заключается в том, что, независимо от его абсолютной величины в нормальном распределении, оно всегда соответствует одинаковому проценту данных, располагающихся по обе стороны от средней: 68% результатов располагаются в пределах одного стандартного отклонения в обе стороны от средней, 95% – в пределах двух стандартных отклонений и 99,7% – в пределах трех стандартных отклонений.
С помощью перечисленных выше показателей можно осуществить оценку различий между двумя или несколькими распределениями, позволяющую проверить, насколько эти различия могут быть экстраполированы на популяцию, из которой взяты выборки. Для этого применяют методы индуктивной статистики.
Индуктивная (сравнительная) статистика
Задача индуктивной статистики заключается в том, чтобы оценить значимость тех различий, которые могут быть между двумя распределениями, с целью выяснить, можно ли распространить найденную закономерность на всю популяцию, из которой были взяты выборки.
Для того чтобы определить, достоверны ли различия между распределениями, следует выдвинуть гипотезу, которую нужно будет затем проверить статистическими методами.
Нулевой гипотезой называют предположение, согласно которому различие между распределениями недостоверно, тогда как альтернативная гипотеза утверждает противоположное.
В том случае, если данных достаточно, если эти данные количественные и подчиняются нормальному распределению, для проверки гипотез используют параметрические критерии.
Если же данных мало либо они являются порядковыми или качественными, используют непараметрические критерии.
Из параметрических критериев наиболее эффективен и чаще всего используется критерий t Стьюдента. Этот критерий позволяет сравнить средние и стандартные отклонения для двух распределений.
Критерий Манна-Уитни – это наиболее эффективный непараметрический критерий, позволяющий проверить, значимо ли различаются выборки по уровню выраженности признака.
Существуют и другие параметрические и непараметрические тесты
Какой бы критерий ни использовался, его вычисленное значение следует сравнить с табличным для уровня значимости 0,05 с учетом числа степеней свободы. Если при этом вычисленный результат окажется выше, нулевая гипотеза может быть отвергнута и можно, следовательно, утверждать, что разница достоверна.
Расчет U - критерия Манна-Уитни (Е.В. Сидоренко )
Назначение критерия
Критерий предназначен для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявлять различия между малыми выборками, когда n1•n2≥3 или n1=2, n2≥5.
Описание критерия
Существует несколько способов использования критерия и несколько вариантов таблиц критических значений, соответствующих этим способам (Гублер Е. В., 1978; Рунион Р., 1982; Захаров В. П., 1985; McCall R., 1970; Krauth J., 1988).
Этот метод определяет, достаточно ли мала зона перекрещивающихся значений между двумя рядами. Мы помним, что 1-м рядом (выборкой, группой) мы называем тот ряд значений, в котором значения, по предварительной оценке, выше, а 2-м рядом - тот, где они предположительно ниже.
Чем меньше область перекрещивающихся значений, тем более вероятно, что различия достоверны. Иногда эти различия называют различиями в расположении двух выборок (Welkowitz J. et al., 1982).
Эмпирическое значение критерия U отражает то, насколько велика зона совпадения между рядами. Поэтому чем меньше Uэмп, тем более вероятно, что различия достоверны.
Гипотезы
Н0: Уровень признака в группе 2 не ниже уровня признака в группе 1.
H1: Уровень признака в группе 2 ниже уровня признака в группе 1.
Графическое представление критерия U
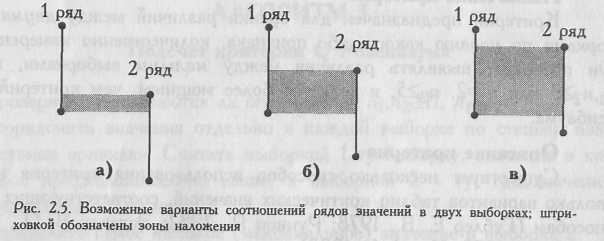
На Рис. 2.5. представлены три из множества возможных вариантов соотношения двух рядов значений.
В варианте (а) второй ряд ниже первого, и ряды почти не перекрещиваются. Область наложения слишком мала, чтобы скрадывать различия между рядами. Есть шанс, что различия между ними достоверны. Точно определить это мы сможем с помощью критерия U.
В варианте (б) второй ряд тоже ниже первого, но и область перекрещивающихся значений у двух рядов достаточно обширна. Она может еще не достигать критической величины, когда различия придется признать несущественными. Но так ли это, можно определить только путем точного подсчета критерия U.
В варианте (в) второй ряд ниже первого, но область наложения настолько обширна, что различия между рядами скрадываются.
Ограничения критерия U
1. В каждой выборке должно быть не менее 3 наблюдений: n1•n2≥3; допускается, чтобы в одной выборке было 2 наблюдения, но тогда во второй их должно быть не менее 5.
2. В каждой выборке должно быть не более 60 наблюдений; n1•n2≤60. Однако уже при n1•n2>20 ранжирование становиться достаточно трудоемким.
На наш взгляд, в случае, если n1•n2>20, лучше использовать другой критерий, а именно угловое преобразование Фишера в комбинации с критерием λ,, позволяющим выявить критическую точку, в которой накапливаются максимальные различия между двумя сопоставляемыми выборками (см. п. 5.4). .Формулировка звучит сложно, но сам метод достаточно прост. Каждому исследователю лучше попробовать разные пути и выбрать тот, который кажется ему более подходящим.
Пример
Вернемся к результатам обследования студентов физического и психологического факультетов Ленинградского университета с помощью методики Д. Векслера для измерения вербального и невербального интеллекта. С помощью критерия Q Розенбаума мы в предыдущем параграфе смогли с высоким уровнем значимости определить, что уровень вербального интеллекта в выборке студентов физического факультета выше. Попытаемся установить теперь, воспроизводится ли этот результат при сопоставлении выборок по уровню невербального интеллекта. Данные приведены в Табл. 2.3.
Можно ли утверждать, что одна из выборок превосходит другую по уровню невербального интеллекта?
Таблица 2.3
Индивидуальные значения невербального интеллекта в выборках студентов физического (щ=\4) и психологического (п2=12) факультетов
|
Студенты-физики |
|
Студенты-психологи |
||
Код имени испытуемого |
Показатель невербального интеллекта |
Код имени испытуемого |
Показатель невербального интеллекта |
||
1. |
И.А. |
111 |
1. |
Н.Т. |
ИЗ |
2. |
К.А. |
104 |
2. |
О.В. |
107 |
3. |
К.Е. |
107 |
3. |
Е.В. |
123 |
4. |
П.А. |
90 |
4. |
Ф.О. |
122 |
5. |
С.А. |
115 |
5. |
И.Н. |
117 |
6. |
Ст.А. |
107 |
6. |
И.Ч. |
112 |
7. |
Т.А. |
106 |
7. |
И.В. |
105 |
8. |
Ф.А. |
107 |
8. |
К.О. |
108 |
9. |
Ч.И. |
95 |
9. |
P.P. |
111 |
10. |
ЦА. |
116 |
10. |
Р.И. |
114 |
11. |
См.А. |
127 |
11. |
O.K. |
102 |
12. |
К.Ан. |
115 |
12. |
Н.К. |
104 |
13. |
Б.Л. |
102 |
|
|
|
14. |
Ф.В. |
99 |
|
|
|
Критерий U требует тщательности и внимания. Прежде всего, необходимо помнить правила ранжирования.